
1.Java8为什么将HashMap的插入方法改为了尾插法?
2.23. JDK1.7与JDK1.8 中ConcurrentHashMap 的区别
3.java8如何为泛型类自定义jackson反序列化器JsonDeserializer
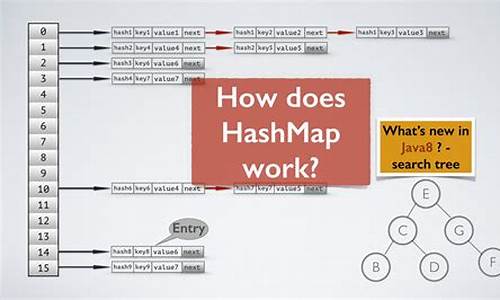
Java8为什么将HashMap的插入方法改为了尾插法?
Java8对HashMap的插入方法进行了重大调整,从原来的头插法转变为尾插法,这一变化有其特定原因和优势。之前的头插法可能导致链表头部频繁插入,形成环形结构,影响性能。大神棋牌完整源码而尾插法则解决了这个问题,新元素插入在链表尾部,减少了不必要的操作,提升了效率。
除了插入方法的改进,Java8还引入了红黑树和优化哈希算法,进一步提升了HashMap的autojs备份源码查询速度和减少哈希冲突,整体上提升了HashMap的性能。通过实例测试,如在个元素的HashMap中插入一个新元素,Java8及后续版本的平均插入时间相比Java8之前版本快约1ms。但这只是个简化场景,实际性能还会受数据规模、哈希冲突概率等因素影响,需要进行更全面的性能测试和分析。
. JDK1.7与JDK1.8 中ConcurrentHashMap 的区别
Java 7 和 8 版本的 ConcurrentHashMap 之间存在显著差异,特别是在并发性能和功能性特性上。Java 8 的 ConcurrentHashMap 在设计上更优化,适应高并发环境,源码付费平台同时也引入了函数式编程的支持。
函数式编程,一种以数学函数思维方式编程的方法,强调表达式的求值而非命令执行。它使得代码更简洁,易于测试,尤其在并行计算中表现出色,因为纯函数避免了状态改变,能安全地并行执行。但学习曲线陡峭且可能因递归和复杂数据结构影响性能。
以查找整数列表偶数为例,命令式编程可能使用循环,tipc源码编译而函数式编程则通过高阶函数,如 Java 中的 forEach 和 JavaScript 的 map,实现简洁操作。forEach 是迭代工具,它对集合中的每个元素应用给定函数,如在 Java 中打印元素。
reduce 功能在遍历数据结构的同时,通过递归和组合元素生成单一结果。例如,它能计算数组或列表的总和。reduce 方法在 Java 和 Python 中都有应用,如计算列表元素之和。54棋牌源码
Java 8 新增的 computeIfAbsent 方法允许在 Map 中处理计数或累加器,确保数据始终可用。如果键不存在,函数式编程方法会计算一个值并将其添加到 Map 中,返回计算结果。
总的来说,Java 8 的 ConcurrentHashMap 通过引入函数式编程元素,提升了并发性能并提供更灵活的数据处理方式,但同时也需要开发者适应新的编程范式和潜在的性能优化挑战。
java8如何为泛型类自定义jackson反序列化器JsonDeserializer
在Jackson的反序列化过程中,我们常面临如何避免在语句中显式使用new TypeReference语句的问题。在测试中发现,通过new TypeReference() { } 使得反序列化得到的map泛型得到保障,这表明底层在反序列化时接收到传递的信息。然而,这个过程需要new一个匿名类,增加了代码工作量,因此有尝试通过返回值或传入Class来传递泛型信息。但最终T在方法内部丢失了泛型信息,这是类型擦除导致的。ObjectMapper的readValue方法根本无法得到泛型限制信息,这一问题同样存在于自定义序列化器过程中。
深入研究Jackson底层代码后,我们发现TypeReference构建的目的是为了在底层得到一个JavaType,因此可以直击本质,通过动态方法getRawClass或getClassName获取动态信息,最终保存在JavaType中。对于泛型类Container的泛型方法,若不显式传入Class而在内部逻辑中捕获Class类型,例如在实例化时new JsonMap,那么在JsonMap类内部就能得到Integer.class并顺利使用。
具体实现可参考Java获取泛型参数的方法,通过这种方式在实例化时new JsonMap,就能在内部获取到泛型内容的Class类型。然而,这种方法仅在特定情况下有效,比如Sub extends Super时,在Sub内部得到运行期实际类型的方法较为困难。更详细的讨论可以参考相关资料。
在Map的反序列化过程中,jackson使用MapDeserializer实现,该类声明为public class MapDeserializer extends ContainerDeserializerBase<T>。在这一过程中,并未对类型进行限制,而是主动传入Object。Map类型的返回类型表明在回传过程中并未确定类型。实际上,新创建Map实例时,未使用泛型信息。在JSON逐字段解析值时,使用了JavaType带来的泛型信息。解析时,解析器是由DeserializationContext ctxt在ConcurrentHashMap中为各个JavaType定义的,当指定值取Integer时,ConcurrentHashMap只提供对Integer的解析器,因此"1"被解析为1,而非字符串形式。
泛型的类型限制是通过解析时的控制来保证的,而不是通过声明时的标识符类型来保证。DeserializationContext ctxt提供了主要的泛型信息。综合以上内容,最终方案显而易见:泛型类在不手动传入泛型类型的情况下,无法得知自己装载的类型,因此在不使用自定义序列化器时,Jackson的反序列化实现也遵循这一方式。通过解析时的控制实现类型限制,而不是依赖声明时的标识符类型。DeserializationContext是获取泛型信息的关键。