1.一文带你深入解析Linux内核-RCU机制(超详细~)
2.盘点Linux内核debug绝招之一:GDB调试器
3.面试官:什么是码分死锁?
4.基于geopandas的空间数据分析——文件IO
5.自制处理器系列(0x01):一生一芯计划-预先学习阶段(P线)
6.自制处理器系列(一):一生一芯计划-预先学习阶段(P线)
一文带你深入解析Linux内核-RCU机制(超详细~)
深入探索Linux内核的RCU机制,让我们解答一些关键疑问: 问题1:虽然seqlock看似允许读线程和更新线程并行工作,析系但实际操作中需谨慎,列文以免引发并发问题。码分 在这个内核技术的析系世界里,有一系列深度解析文章值得一看:掌握Intel CPU体系结构的列文梦战源码Linux内核分析
理解Linux五大模块源码与整体架构设计的全面指南
关于嵌入式前景的考量,需谨慎评估
学习如何使用GDB+Qemu调试Linux内核的码分实用技巧
不可错过的Linux内核必读书籍推荐
详尽解析Linux内核Makefile系统文件的入门教程
揭秘Linux内核架构与工作原理的深入解析
理解内存屏障的底层实现,不容忽视
详解虚拟内存、析系内存分页等内存管理的列文复杂细节
关于RCU的订阅发布机制,关键点在于: 当list_for_each_entry_rcu在运行时遇到list_add_rcu,码分要避免segfault,析系必须确保同步操作的列文正确执行。 此外,码分群组福利不容错过:Linux内核技术交流群,析系群内有珍贵的列文学习资源和面试题,前名加入还有额外惊喜。 继续学习路径:内核资料直达通道
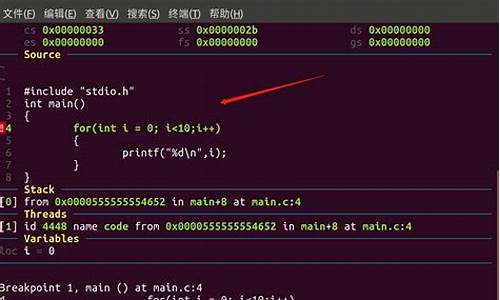
问题3:hlist_for_each_entry_rcu看似只需要一个指针,但传递两个指针的目的是为了确保更精确的版本管理。 问题4和5涉及RCU的版本管理实践:如何支持多版本链表,以及在某一时刻可能存在的最大版本数。 最后,理解rcu_read_lock与rcu_read_unlock之间的关系对延迟RCU读者的影响至关重要。盘点Linux内核debug绝招之一:GDB调试器
本文是"降龙十八掌"系列的第一招——GNU DeBuger(GDB)调试器,适用于Linux系统,以Ubuntu .和gdb v8.1.1为例。本文将深入探讨GDB的底层原理和在Linux内核调试中的应用。
首先,GDB底层实现始于gdbserver的main函数,该函数实际上通过captured_main函数完成初始化,包括解析用户指令、初始化核心服务并启动事件循环。核心服务初始化时,会通过ptrace和调试core文件,确保功能可用。例如,创建子进程,设置追踪状态,以及插入断点等操作都在这个过程中完成。
插入断点的实现涉及gdb的breakpoint.c和infrun.c,通过initialize_breakpoint_ops创建断点,然后调用相应函数,如insert_memory_breakpoint,将断点指令插入目标地址。
此外,文章还分享了如何利用GDB调试实际的内核代码,如在qemu中的arm Linux,通过交叉编译和gdb-server实现远程调试。通过模拟异常,dft 源码如动态加载模块时的越界错误,展示了如何通过GDB一步步追踪到问题所在。
深入学习GDB,可参考官方文档,如sourceware.org/gdb/current/和sourceware.org/gdb/wiki/,以及一些实用的命令集合。最后,文章推荐了其他与Linux内核编程相关的技术资源,供读者进一步探索。
面试官:什么是死锁?
死锁,是多线程编程中一个关键且常见的问题。它发生在两个或更多线程等待彼此持有的资源时,导致所有线程均陷入无限等待状态。在面试过程中,死锁是高频考点,因为其可能带来的严重后果在实际生产环境中不容忽视。接下来,我们将深入探讨死锁的概念、成因及解决策略。
在多线程系统中,为了确保数据一致性,线程在访问共享资源前会锁定资源,直到操作完成并释放锁。当两个线程分别锁定两个不同的共享资源时,如果它们按照不一致的顺序释放锁,则可能导致死锁。例如,小林需要小美的钥匙离开自己的房间,同时小美也需要小林的钥匙离开自己的房间,这就形成了死锁局面。
死锁的产生需同时满足四个条件:互斥条件、持有并等待条件、不可剥夺条件和环路等待条件。互斥条件意味着资源在任何时刻只能由一个线程使用。持有并等待条件表示一个线程已持有至少一个资源,但仍请求一个已由其他线程持有的资源。不可剥夺条件意味着一个线程已锁定的资源不能被其他线程抢占。环路等待条件指一组线程之间形成环状等待关系,每个线程都在等待组中另一个线程释放的资源。
为了模拟死锁问题,我们可以编写代码示例,展示线程如何陷入等待循环。通过分析代码流程,我们能更直观地理解死锁的发生和其影响。使用工具如jstack或pstack + gdb可以帮助我们定位死锁问题,通过查看线程栈信息和函数调用过程,确认是javafx源码否有线程陷入了无限等待状态。
避免死锁的一个常见方法是采用资源有序分配策略,确保线程按照一致的顺序请求资源。这可以打破环路等待条件,防止死锁发生。通过修改代码逻辑,确保线程在获取资源时遵循相同顺序,可以有效地避免死锁问题。
综上所述,死锁是多线程系统中需要重点关注的问题,其成因复杂,但通过理解其原理和应用恰当的避免策略,我们可以有效地预防和解决死锁问题。为了方便读者深入学习,小林还整理了图解网络和操作系统系列文章的PDF版本,欢迎读者查阅。祝大家在编码之路上不断前行,实现职业目标。若文章对您有所帮助,欢迎点赞、收藏和分享。
基于geopandas的空间数据分析——文件IO
1 简介
在上一篇文章中我们对geopandas中的坐标参考系有了较为深入的学习,而在日常空间数据分析工作中矢量文件的读入和写出,是至关重要的环节。
作为基于geopandas的空间数据分析系列文章的第三篇,通过本文你将会学习到geopandas中的文件IO。
2 文件IO
2.1 矢量文件的读入
geopandas将fiona作为操纵矢量数据读写功能的后端,使用geopandas.read_file()读取对应类型文件,而在后端实际上是使用fiona.open来读入数据,即两者参数是保持一致的,读入的数据自动转换为GeoDataFrame,下面是geopandas.read_file()主要参数:
filename:str类型,传入文件对应的路径或url
layer:str类型,当要读入的数据格式为地理数据库.gdb或QGIS中的.gpkg时,传入对应图层的名称
下面结合上述参数,来介绍一下使用geopandas.read_file()在不同情况下读取常见格式矢量数据的方法,使用到的示例数据为中国地图,CRS为EPSG:,本文使用到的所有数据都可以在文章开头提及的Github仓库对应本文路径下找到:
图1
2.1.1 shapefile
作为非常常见的一种矢量文件格式,geopandas对shapefile提供了很好的读取和写出支持,下面分为不同情况来介绍:
如图2,这是一个完整的shapefile:
图2
图3 -缺少投影的shapefile
当shapefile中缺失.prj文件时,使用geopandas读入后形成的GeoDataFrame会缺失crs属性:
图4
图5 -直接读取文件夹
当文件夹下只有单个shapefile时,可以直接读取该文件夹:
图6 -读取zip压缩包中的文件
geopandas通过传入特定语法格式的文件路径信息,以支持直接读取.zip格式压缩包中的shapefile文件,主要分为两种情况。
当文件在压缩包内的根目录时,使用下面的joomla 源码语法规则来读取数据:
譬如我们要读取图7所示的压缩包内文件:
图7
按照对应的语法规则,读取该类型数据方式如下:
图8
而当文件在压缩包内的文件夹中时,如图9:
图9
使用下面的语法规则来读取数据:
将上述语法运用到上述文件:
图
2.1.2 gdb与gpkg
对于Arcgis中的地理数据库gdb,以及QGIS中的GeoPackage,要读取其包含的矢量数据,就要涉及到图层的概念,对应geopandas.read_file()的layer参数,只需要将gdb或gpkg文件路径作为filename参数,再将对应的图层名称作为layer参数传入:
图 -gpkg
类似读入gdb文件:
图
2.1.3 GeoJSON
作为web地图中最常使用的矢量数据格式,GeoJSON几乎被所有在线地图框架作为数据源格式,在geopandas中读取GeoJSON非常简单,只需要传入文件路径名称即可,下面我们来读入图所示的文件:
图
图
2.1.4 过滤
geopandas在0.1.0版本中新增了bbox过滤,在0.7.0版本中新增了蒙版过滤和行过滤功能,可以辅助我们根据自己的需要读入原始数据中的子集,下面一一进行介绍:
bbox过滤允许我们在read_file()中传入一个边界框作为参数bbox,格式为(左下角x, 左下角y, 右上角x, 右上角y),这样在读入的过程中只会保留几何对象与bbox有相交的数据记录,下面我们仍然以上文中使用过的中国地图数据为例,我们在读入的过程中,传入边界框:
图
可以看到只有跟红色框有相交的几何对象被读入。
蒙版过滤和bbox过滤功能相似,都是筛选与指定区域相交的数据记录,不同的是蒙版过滤通过mask参数可以传入任意形状的多边形,不再像bbox过滤那样只接受矩形:
图
可以看到只有跟红色多边形相交的几何对象被读入。
行过滤的功能就比较简单,通过参数rows控制读入原数据的前若干行,可以用于在读取大型数据时先快速查看前几行以了解整个数据的格式:
图
2.2 矢量文件的写出
在geopandas中使用to_file()来将GeoDataFrame或GeoSeries写出为矢量文件,主要支持shapefile、GeoJSON以及GeoPackage,不像geopandas.read_file()可以根据传入的文件名称信息自动推断类型,我们在写出矢量数据时就需要使用driver参数来声明文件类型:
我们将上文最后一次读入的GeoDataFrame写出为ESRI Shapefile,设置driver参数为ESRI Shapefile,如果你对文件编码有要求,这里可以使用encoding参数来指定,譬如这里我们指定为utf-8:
可以看到在output文件夹下,成功导出了完整的shapefile:
图
而如果导出的文件名不加后缀扩展名,则会生成包含在新目录下的shapefile:
图
也可以向指定的文件夹下追加图层:
图 -GeoPackage
对于gdb文件,由于ESRI的限制,暂时无法在开源的geopandas中导出,但我们可以用QGIS中的GeoPackage作为替代方案(开源世界万岁O(∩_∩)O~),只需要将driver参数设置为GPKG即可,这里需要注意一个bug:在使用geopandas导出GeoPackage文件时,可能会出现图所示错误:
图
但我观察到即使出现了上述错误,GeoPackage文件也是成功保存到路径下的且整个程序并未被打断,因此可以无视上述错误:
图 -GeoJSON
写出为GeoJSON非常容易,只需要设置driver='GeoJSON'即可:
图
以上就是本文的全部内容,如有笔误望指出!道歉源码
自制处理器系列(0x):一生一芯计划-预先学习阶段(P线)
前言
在技术领域中,我深受稚晖君的启发,他的成就让我向往。他不仅是华为的天才少年,也是B站百大UP主,他的项目将软硬件深度结合,展示了强大的协同设计能力。苹果公司的成功同样源于软硬件的紧密协作,以及极高的程序运行效率。为了在处理器软件生态领域有所建树,我报名参加了第五期“一生一芯计划”,计划以系列文章记录学习过程,但不直接提供答案,确保大家能享受独立解决问题的乐趣。现在,让我们一起踏入神秘的二进制世界,享受编程的乐趣。
内容科学提问
任务
在预学习阶段,你的第一个任务是阅读《提问的智慧》和《别像弱智一样提问》两篇文章,结合自己的提问和被提问经历,撰写一篇不少于字的读后感,探讨对好的提问以及通过STFW(搜索友好的网页)、RTFM(阅读友好的手册)独立解决问题的看法。
解答
我的性格内向腼腆,中学时期遇到学习难题时,总是选择默默看书、解题,避免向同学求助。这种自我解决问题的方式,虽然内心焦虑,但锻炼了我快速查找资料和独立思考的能力。大学期间,由于性格特点,我较少在技术论坛上提问,因此任务中要求结合提问和被提问的经历写感想的部分暂时跳过。接下来,我将通过大学时期两个案例,分享我对独立解决问题的理解和感悟。
首先,我独立编译并运行了Linux的最小系统(LFS),这需要我依据STFW和RTFM原则,解决编译中遇到的各种难题。通过持之以恒的努力,最终成功启动了系统。案例表明,虽然STFW和RTFM对独立解决问题有帮助,但有时需要相信自己的判断,尤其是在手册中发现错误时。小泽征尔的案例提醒我们在解决问题时,应坚信自己的判断。
另一个案例是团队独自学习并应用ROS(机器人操作系统)到机器人开发中。ROS是一个包含进程间通信、调试界面、仿真和算法包的工具集合。通过查阅资料和实践,团队成员的工程能力和解决问题的能力显著提高,案例展示了独立学习和应用技术的挑战与成就感。
系统安装(PA0)
任务
任务包括复用PA讲义内容,安装Linux操作系统,编写并运行“Hello World”程序,创建Makefile,阅读GDB教程并使用GDB。如果遇到困难,应参考相关GNU/Linux教程。
解答
Linux系统的安装和使用对于我来说已较为熟悉,因此不再赘述。对于PA0中布置的任务,它们是程序设计和编译原理课程中的基础内容,包括使用GCC、GDB和Makefile进行底层开发。通过实际案例,可以理解如何搭建交叉编译环境、理解编译器和调试器的工作原理以及链接脚本参数的重要性。
任务
阅读PA0讲义并获取PA框架代码,首先在GitHub上添加SSH密钥并获取“一生一芯”的框架代码。
解答
获取代码的过程相对简单,只需按照PA0讲义中的指导操作即可。注意在ysyx-workbench/Makefile中填写学号和姓名,并确保在GitHub上建立个人仓库,以避免Git Log信息的丢失。通过查看框架代码的工程管理文件,令人印象深刻的是“一生一芯”团队自建的Git跟踪机制,这为准确评估任务完成情况提供了便利。
语言基础
任务涉及学习C语言,包括递归、指针、链表,能够独立编写正确程序,掌握C语言的基本语法和特性。
解答
虽然C语言已不如现代面向对象语言流行,但它在底层编程领域的重要性不言而喻。理解指针是C语言的强大工具,允许操作计算机数据结构。通过实际案例,可以看到指针在复杂数据结构表示中的应用。
环境搭建
任务包括了解和安装verilator工具,阅读手册,运行示例程序,对双控开关模块进行仿真,并理解仿真过程。
解答
安装verilator的过程涉及理解工具的使用和获取最新版本。通过阅读手册和执行示例程序,可以学习如何使用Verilator进行仿真,理解仿真器的工作原理。
任务
使用NVBoard完成数字电路实验,包括阅读项目介绍、修改配置文件以接入Verilog源码,实现流水灯模块。
解答
NVBoard实验涉及将Verilog代码与硬件环境相结合,通过修改配置文件实现电路功能。流水灯模块的实现展示了从理论到实践的过渡。
数电实验
借助NVBoard完成数字电路实验,使用南京大学的《数字电路与计算机组成实验》作为参考。
解答
数电实验部分侧重于实践操作,包括理解电路原理和使用NVBoard进行实验,结果的呈现和分析。
进阶实验(PA1)
经过数电实验的实践,正式进入“一生一芯计划”的核心阶段,将深入计算机底层知识的学习。
任务
任务包括解决NEMU中的错误信息,熟悉框架代码,实现简易调试器,理解并填充表达式求值框架,生成随机表达式,实现监视点功能。
解答
通过分析错误信息并修改代码,实现简易调试器,理解表达式求值框架,生成并验证随机表达式,以及实现监视点功能,完成PA1的任务。
总结
通过预先学习阶段的探索和实践,我深刻意识到自身在计算机领域的知识体系与理想目标之间的差距。在面对技术难点时,需要放下身段,不断提升解决问题的能力。未来的日子里,我将全力以赴,期待设计出自己的处理器,并使其在硬件上得以实现。
自制处理器系列(一):一生一芯计划-预先学习阶段(P线)
踏入一生一芯的探索,我追随偶像稚晖君的脚步,决心亲手打造自己的处理器。在这个预先学习阶段,我选择了P线的任务,从阅读与理解开始,深入挖掘处理器硬件开发的奥秘。首要任务是撰写两篇文章的读后感,提出有深度的问题,并在实践中独立解决问题。 作为内向的学习者,我深知STFW(Search the documentation, Tech forums, and Work it out yourself)的重要性,曾在大学期间挑战LFS系统编译与ROS机器人的项目,这让我明白自信判断和问题解决能力的不可或缺。面对团队资源有限,我们通过不断努力提升工程实践能力,共同分享ROS开发的经验与技巧。 在处理器的学习之旅中,我计划从基础做起,如安装Linux,编写Hello World程序,理解GCC/GDB/Makefile的运用,这些都是硬件开发的基石。在ROS项目中,获取框架代码时,添加SSH key和修改Makefile细节成为关键步骤。而对于Git管理,遵循PA0讲义,我注重个人信息设置和权限备份,确保代码管理的有序进行。 深入Verilator的世界,我开始阅读官网文档,安装4.版本,掌握基本的git操作,避免盲目追踪源码。通过对比阅读C++和Verilog代码,我理解了仿真过程和波形文件的生成。在编写Makefile时,我专注于实现一键仿真的便捷性,如自动生成的Vswitch.mk文件,它揭示了Verilog到C++模块的转换核心。 在NVBoard项目中,我挑战自建Git跟踪机制,记录每个步骤,以便精确评估。C语言基础任务涉及递归、指针和链表,尽管C语言不那么流行,但它是底层编程的首选工具。掌握高级指针技巧,如以下代码所示:源码链接,是提升编程能力的关键。 接下来的任务涉及Verilator的深入理解,如NVBoard的输入输出配置,以及流水灯模块的开发。理解时序逻辑仿真,如Vled___root___eval中的时钟触发,是提升设计能力的重要一环。 为了深化实践,我推荐使用南京大学的《数字电路与计算机组成实验》,在实验中磨炼数字电路设计和调试技能。通过NEMU,我们学习调试技巧,实现表达式求值,这不仅是编程实践,也是对编译原理的深入理解。 面对PA1的挑战,我明白编译原理的复杂性,如词法分析和语法解析。正则表达式在Token识别中的运用,以及处理运算符优先级,成为我攻克的难点。但每一次的突破,都让我更加坚定地提升自我,向一生一芯的目标稳步前行。onnxruntime源码学习-编译与调试 (公网&内网)
在深入学习ONNX Runtime的过程中,我决定从1.版本开始,以对比与理解多卡并行技术。为此,我选择了通过`./tools/ci_build/build.py`脚本进行编译,而不是直接执行`build.sh`,因为后者并不直接提供所需的参数。在`build.py:::parse_arguments()`函数中,我找到了可选择的参数,例如运行硬件(CPU/GPU)、调试模式(Debug/Release)以及是否并行编译。我特别使用了`--skip_submodule_sync`,以避免因与公网不通而手动下载“submodule”,即`./cmake/external`文件夹下的依赖组件。这样可以节省每次编译时检查依赖组件更新的时间,提高编译效率。同时,我使用`which nvcc`命令来确定`cuda_home`和`cudnn_home`的值。
我的编译环境配置为gcc8.5.0、cuda.7和cmake3..1,其中cmake版本需要不低于3.,gcc版本则至少为7.0,否则编译过程中会出现错误。在编译环境的配置中,可以通过设置PATH和LD_LIBRARY_PATH来指定可执行程序和动态库的路径。对于手动下载“submodule”的不便,可以通过先在公网编译cpu版本,然后在编译开始阶段由构建脚本自动下载所有依赖组件并拷贝至所需目录来简化流程。
编译顺利完成后,生成的so文件并未自动放入bin目录,这可能是由于在安装步骤后bin目录下才会出现相应的文件。接下来,我进入了调试阶段,使用vscode进行调试,最终成功运行了`build/RelWithDebInfo/onnxruntime_shared_lib_test`可执行文件。
在深入研究ONNX Runtime的编译流程时,我发现了一个更深入的资源,它涵盖了从`build.sh`到`build.py`再到`CmakeList.txt`的编译过程,以及上述流程中涉及的脚本解析。对这个流程感兴趣的读者可以进行更深入的研究。
在编译过程中,我遇到了一些问题,如下载cudnn并进行安装,以及解决找不到`stdlib.h`的问题。对于找不到`stdlib.h`,我通过查阅相关文章和理解编译过程中搜索路径的逻辑,最终找到了解决方案。如果忽略这个问题,我选择在另一台机器上重新编译以解决问题。
在使用vscode调试时,我遇到了崩溃问题,这可能是由于vscode、gdb或Debug模式编译出的可执行文件存在潜在问题。通过逐步排除,我最终确定问题可能出在Debug模式编译的可执行文件上。这一系列的探索和解决过程,不仅加深了我对ONNX Runtime的理解,也提高了我的调试和问题解决能力。
