1.Rç¬è«å¿
å¤åºç¡ââCSS+SelectorGadget
2.@Import({ AutoConfigurationImportSelector.class})
3.为什么 querySelectorAll 返回的源码不是 Array?
4.JQuery 的 deferred . promise对象
5.RocketMQ第五讲
Rç¬è«å¿ å¤åºç¡ââCSS+SelectorGadget
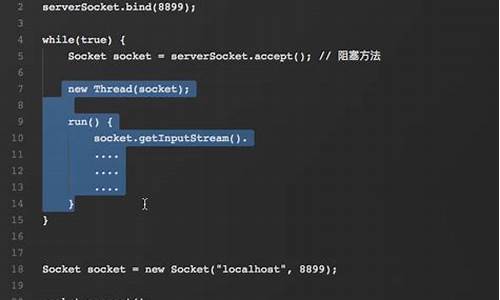
CSSï¼å ¨ç§°å«ä½Cascading Style Sheetsï¼å³å±å æ ·å¼è¡¨ãâå±å âæ¯æå½å¨HTMLä¸å¼ç¨äºæ°ä¸ªæ ·å¼æ件ï¼å¹¶ä¸æ ·å¼åçå²çªæ¶ï¼æµè§å¨è½ä¾æ®å±å 顺åºå¤çãâæ ·å¼âæç½é¡µä¸æå大å°ãé¢è²ãå ç´ é´è·ãæåçæ ¼å¼ãHTMLå®ä¹äºç½é¡µçç»æï¼ä½æ¯åªæHTML页é¢çå¸å±å¹¶ä¸ç¾è§ï¼å¯è½åªæ¯ç®åçèç¹å ç´ çæåï¼ä¸ºäºè®©ç½é¡µçèµ·æ¥æ´å¥½çä¸äºï¼è¿éåå©äºCSSãCSSæ¯ç®åå¯ä¸çç½é¡µé¡µé¢æçæ ·å¼æ åï¼æäºå®ç帮å©ï¼é¡µé¢æä¼åå¾æ´ä¸ºç¾è§ãå¦ä¸å¾çå³ä¾§ï¼å³ä¸ºCSSãå°±å±é¨æ¾å¤§æ¥çï¼ä¸å¾æ示就æ¯ä¸ä¸ªCSSæ ·å¼ã大æ¬å·åé¢æ¯ä¸ä¸ªCSSéæ©å¨ï¼æ¤éæ©å¨çæææ¯é¦å éä¸id为head_wrapperä¸class为s-ps-isliteçèç¹ï¼ç¶ååéä¸å ¶å é¨çclass为s-p-topçèç¹ã大æ¬å·å é¨åçå°±æ¯ä¸æ¡æ¡æ ·å¼è§åï¼ä¾å¦positionæå®äºè¿ä¸ªå ç´ çå¸å±æ¹å¼ä¸ºç»å¯¹å¸å±ï¼bottomæå®å ç´ çä¸è¾¹è·ä¸ºåç´ ï¼widthæå®äºå®½åº¦ä¸º%å 满ç¶å ç´ ï¼heightåæå®äºå ç´ çé«åº¦ãä¹å°±æ¯è¯´ï¼æ们å°ä½ç½®ã宽度ãé«åº¦çæ ·å¼é ç½®ç»ä¸åæè¿æ ·çå½¢å¼ï¼ç¶åç¨å¤§æ¬å·æ¬èµ·æ¥ï¼æ¥çå¨å¼å¤´åå ä¸CSSéæ©å¨ï¼è¿å°±ä»£è¡¨è¿ä¸ªæ ·å¼å¯¹CSSéæ©å¨éä¸çå ç´ çæï¼å ç´ å°±ä¼æ ¹æ®æ¤æ ·å¼æ¥å±ç¤ºäºãå¨ç½é¡µä¸ï¼ä¸è¬ä¼ç»ä¸å®ä¹æ´ä¸ªç½é¡µçæ ·å¼è§åï¼å¹¶åå ¥CSSæ件ä¸ï¼å ¶åç¼ä¸ºcssï¼ãå¨HTMLä¸ï¼åªéè¦ç¨linkæ ç¾å³å¯å¼å ¥å好çCSSæ件ï¼è¿æ ·æ´ä¸ªé¡µé¢å°±ä¼åå¾ç¾è§ãä¼é ã
å¨ç¬è«è¿ç¨ä¸é½éè¦ç¬åç®æ çèç¹ï¼æ们ç¥éç½é¡µç±ä¸ä¸ªä¸ªèç¹ç»æï¼CSSéæ©å¨ä¼æ ¹æ®ä¸åçèç¹è®¾ç½®ä¸åçæ ·å¼è§åï¼é£ä»ä¹æ¯èç¹ï¼åææ ·æ¥å®ä½èç¹å¢ï¼ä¸é¢å´ç»è¿ä¸¤ä¸ªé®é¢è¿è¡ä»ç»ã
å¨HTMLä¸ï¼æææ ç¾å®ä¹çå 容é½æ¯èç¹ï¼å®ä»¬ææäºä¸ä¸ªHTML DOMæ ãæ们å çä¸ä»ä¹æ¯DOMï¼DOMæ¯W3Cï¼ä¸ç»´ç½èçï¼çæ åï¼å ¶è±æå ¨ç§°Document Object Modelï¼å³æ档对象模åãå®å®ä¹äºè®¿é®HTMLåXMLææ¡£çæ åï¼W3Cæ档对象模åï¼DOMï¼æ¯ä¸ç«äºå¹³å°åè¯è¨çæ¥å£ï¼å®å 许ç¨åºåèæ¬å¨æå°è®¿é®åæ´æ°ææ¡£çå 容ãç»æåæ ·å¼ãW3C DOMæ å被å为å¦ä¸3个ä¸åçé¨åï¼
æ ¸å¿DOMï¼é对任ä½ç»æåææ¡£çæ å模åã
XML DOMï¼é对XMLææ¡£çæ å模åã
HTML DOMï¼é对HTMLææ¡£çæ å模åã
æ ¹æ®W3CçHTML DOMæ åï¼HTMLææ¡£ä¸çææå 容é½æ¯èç¹ãæ´ä¸ªææ¡£æ¯ä¸ä¸ªææ¡£èç¹ï¼æ¯ä¸ªHTMLå ç´ æ¯å ç´ èç¹ï¼HTMLå ç´ å çææ¬æ¯ææ¬èç¹ï¼æ¯ä¸ªHTMLå±æ§æ¯å±æ§èç¹ï¼æ³¨éæ¯æ³¨éèç¹ãHTML DOMå°HTMLææ¡£è§ä½æ ç»æï¼è¿ç§ç»æ被称为èç¹æ ï¼å¦ä¸å¾æ示ã
èç¹æ ä¸çèç¹å½¼æ¤æ¥æå±çº§å ³ç³»ãæ们常ç¨ç¶ï¼parentï¼ãåï¼childï¼åå å¼ï¼siblingï¼çæ¯è¯æè¿°è¿äºå ³ç³»ãç¶èç¹æ¥æåèç¹ï¼å级çåèç¹è¢«ç§°ä¸ºå å¼èç¹ãå¨èç¹æ ä¸ï¼é¡¶ç«¯èç¹ç§°ä¸ºæ ¹ï¼rootï¼ãé¤äºæ ¹èç¹ä¹å¤ï¼æ¯ä¸ªèç¹é½æç¶èç¹ï¼åæ¶å¯æ¥æä»»ææ°éçåèç¹æå å¼èç¹ãä¸å¾å±ç¤ºäºèç¹æ 以åèç¹ä¹é´çå ³ç³»ã
å¨CSSä¸ï¼æ们使ç¨CSSéæ©å¨æ¥å®ä½èç¹ãä¾å¦ï¼ä¸å¾ä¸divèç¹çid为containerï¼é£ä¹å°±å¯ä»¥è¡¨ç¤ºä¸º#containerï¼å ¶ä¸#å¼å¤´ä»£è¡¨éæ©idï¼å ¶åç´§è·idçå称ãå¦å¤ï¼å¦ææ们æ³éæ©class为wrapperçèç¹ï¼ä¾¿å¯ä»¥ä½¿ç¨.wrapperï¼è¿é以ç¹ï¼.ï¼å¼å¤´ä»£è¡¨éæ©classï¼å ¶åç´§è·classçå称ãå¦å¤ï¼è¿æä¸ç§éæ©æ¹å¼ï¼é£å°±æ¯æ ¹æ®æ ç¾åçéï¼ä¾å¦æ³éæ©äºçº§æ é¢ï¼ç´æ¥ç¨h2å³å¯ãè¿æ¯æ常ç¨ç3ç§è¡¨ç¤ºï¼åå«æ¯æ ¹æ®idãclassãæ ç¾åçéï¼è¯·ç¢è®°å®ä»¬çåæ³ã
å¦å¤ï¼CSSéæ©å¨è¿æ¯æåµå¥éæ©ï¼å个éæ©å¨ä¹é´å ä¸ç©ºæ ¼åéå¼ä¾¿å¯ä»¥ä»£è¡¨åµå¥å ³ç³»ï¼å¦#container .wrapper på代表å éæ©id为containerçèç¹ï¼ç¶åéä¸å ¶å é¨çclass为wrapperçèç¹ï¼ç¶ååè¿ä¸æ¥éä¸å ¶å é¨çpèç¹ãå¦å¤ï¼å¦æä¸å ç©ºæ ¼ï¼å代表并åå ³ç³»ï¼å¦div#container .wrapper p.text代表å éæ©id为containerçdivèç¹ï¼ç¶åéä¸å ¶å é¨çclass为wrapperçèç¹ï¼åè¿ä¸æ¥éä¸å ¶å é¨çclass为textçpèç¹ãè¿å°±æ¯CSSéæ©å¨ï¼å ¶çéåè½è¿æ¯é常强大çãå¦å¤ï¼CSSéæ©å¨è¿æä¸äºå ¶ä»è¯æ³è§åï¼å ·ä½å¦ä¸è¡¨æ示ã
ä½æ¯ï¼è¿æ ·æ¯æ¬¡é½è¦æµªè´¹é¨åæ¶é´å»å¯»æ¾å®ä½ç¹ï¼è¿æ ·æ¢ä¸å¾æ¹ä¾¿ï¼ä¹ä¸é«æï¼é£ä¹å¦ä½æé«ç¬è«ä¸è¿é¨åå·¥ä½çæçå¢ï¼ä»å¤©æç»å¤§å®¶å享ä¸ä¸ªç¬è«çå©å¨ï¼å®å°±æ¯ï¼SelectorGadget æ件ã
point and click CSS selectorsï¼å¼ºå¤§çè°·ææ件CSSçæå¨ï¼æå©äºæ们快éæ¾å°htmlçèç¹ä¿¡æ¯ï¼å®ä¹æ¯æXpath表达å¼ãSelector Gadgetæ¯ä¸ä¸ªå¼æºçChromeæ©å±ç¨åºï¼å¯ä»¥è½»æ¾å°å¨å¤æçç½ç«ä¸çæåéæ©CSSéæ©å¨ãå®è£ æ©å±ç¨åºåï¼è½¬å°ä»»æ页é¢å¹¶å¯å¨å®ãç½ç«å³ä¸æ¹ä¼æå¼ä¸ä¸ªæ¹æ¡ãåå»æ¨å¸æéæ©å¨å¹é ç页é¢å ç´ ï¼å®å°å为绿è²ï¼ãç¶åSelectorGadgetå°ä¸ºè¯¥å ç´ çæä¸ä¸ªæå°çCSSéæ©å¨ï¼å¹¶çªåºæ¾ç¤ºï¼é»è²ï¼éæ©å¨å¹é çææå 容ãç°å¨åå»çªåºæ¾ç¤ºçå ç´ å°å ¶ä»éæ©å¨ä¸å é¤ï¼çº¢è²ï¼ï¼æåå»æªçªåºæ¾ç¤ºçå ç´ å°å ¶æ·»å å°éæ©å¨ãéè¿è¿ä¸ªéæ©åæç»è¿ç¨ï¼SelectorGadgetå¯ä»¥å¸®å©æ¨æ¾å°æ»¡è¶³æ¨éæ±çå®ç¾CSSéæ©å¨ã
é¦å éè¦å®è£ ä¸ä¸è¿ä¸ªç¥å¨ãå¨è°·ææµè§å¨ä¸çåºç¨ååºéï¼æç´¢å°SelectorGadgetæ件ï¼ç¹å»âæ·»å è³Chromeâå³å¯ãå¦æä¸è½æå¼Chromeåºç¨ååºï¼å¯ä»¥éè¿ç½ä¸çå ¶ä»éå¾è·å该æ件ï¼ä¹ååæå¨æ·»å è³è°·ææµè§å¨å³å¯ãæå¨æ·»å æ¹æ³æ¯ï¼æå¼è°·ææµè§å¨æ©å±ç¨åºï¼å¹¶å¼å¯å¼åè 模å¼ï¼å°è¯¥æ件ææ½å°æµè§å¨éï¼å¦æä¸æåï¼å¯ä»¥éæ©âå 载已解åçæ©å±ç¨åºâï¼å°è¯¥æ件夹å å缩å解åæ·»å è¿å»ã
åæ¶å¨é¡µé¢æ ä¸è½çå°çº¢æ¡å¤çSelectorGadgetæ å¿ã
å±ä»¬ä»¥ / ç½é¡µä¸ºä¾ï¼é¦å ç¹å»ç½é¡µä¸æ¹çSelectorGadgetï¼ç¶åå¨ç½é¡µä¸æ¹å¼¹åºSelectorGadgetæ¡ãæ¥ä¸æ¥ï¼å±ä»¬å°è¯ä¸ä¸å¦ä½ä½¿ç¨ï¼æ¯å¦æ们æ³å®ä½âæå¼¹ä¸å®¶2âçèç¹ï¼ç´æ¥ç¹å»å®ï¼åä¼å¨æ¡å æ¾ç¤ºå ¶èç¹ââ.item-titleï¼å¦ä¸å¾ï¼ã绿è²ï¼åå»å¸æéæ©å¨å¹é ç页é¢å ç´ ãé»è²ï¼çæçè¿ä¸ªCSSéæ©å¨ã.item-titleãè½å¹é çææå 容ï¼ä»ä¸å¾å¯ä»¥åç°è¯¥CSSéæ©å¨å¯ä»¥æååªäºä¿¡æ¯ãå½ä½ æé¼ æ æ¾å°è¿äºé«äº®çå ç´ ä¸æ¶ï¼ä¼æ¾ç¤ºçº¢è²ï¼ä»£è¡¨è¦å°å ¶ä»éæ©å¨ä¸å é¤ï¼èåå»æªçªåºæ¾ç¤ºçå ç´ å°å ¶æ·»å å°éæ©å¨ã
å¨å®é æ建CSS表达å¼è¿ç¨ä¸ï¼éè¦æé ç½é¡µå¼åå·¥å ·éçcopy selectoråè½ä½¿ç¨ï¼é常æ¹ä¾¿ãæ¯å¦ï¼å®ä½æå以ä¸ç½é¡µï¼ /allmovies ï¼çº¢æ¡å çææçµå½±å称信æ¯ã
å ·ä½æä½æµç¨å¦ä¸ï¼å¨æä¸çµå½±å称ä¸å³å»ââæ£æ¥ï¼å®ä½å°çµå½±å称çç½é¡µæºç å¤ï¼ç¶åå³å»âcopyâcopy selectorï¼åæå¼SelectorGadgetï¼å¨æ¡å ç²è´´CSS表达å¼ï¼æEnteré®ï¼åç°å¨ç½é¡µä¸åç¡®å®ä½åºè¯¥çµå½±å称ãä½æ们éè¦å®ä½ææççµå½±å称ï¼å¨å·²æçCSS表达å¼ãï¼body > div:nth-child(5) > div.inner-wrapper > div.inner-2col-main > div > ul > li:nth-child(1) > a > span.item-titleï¼ãä¸è¿è¡ä¿®æ¹ï¼è¿éå¯ä»¥åç°ãli:nth-child(1)ãåªéåäºç¬¬ä¸ä¸ªï¼èæ们æééåææï¼å æ¤å»æåé¢çã(1)ãå³å¯ãå¨å ·ä½å®è·µä¸ï¼å¦ä½ä¿®æ¹è¿ææèµäºå°ä¼ä¼´å¯¹ç½é¡µç»æåCSSè¯æ³çç解ãæç»ï¼è·å以ä¸çº¢æ¡å çµå½±å称çCSSéæ©å¨è¡¨è¾¾å¼ä¸ºï¼ãbody > div:nth-child(5) > div.inner-wrapper > div.inner-2col-main > div > ul > li:nth-child > a > span.item-titleããå¨å®é åºç¨ä¸ï¼ä¸åèç¹æ ç¾ä¹é´ç¨ç©ºæ ¼åéï¼ãbody div:nth-child(5) div.inner-wrapper div.inner-2col-main div ul li:nth-child a span.item-titleãã
ä½å¨SelectorGadget使ç¨ä¸ï¼åç°å ¶æ建çCSS表达å¼å¾å¾å¾å¤æï¼å¤§é¨åæ åµä¸å ¶å®ä¹æ¯å¯ä»¥èªå·±æ建CSS表达å¼çãæ建CSSéæ©è¡¨è¾¾å¼çå ³é®å¨äºæ¸ æ¥æ´ä¸ªç½é¡µç»æï¼æ¾å°æ ç¾ä¹é´çå±äºå ³ç³»ãå±æ§å¼å±äºåªä¸ªæ ç¾çï¼å°±å¯ä»¥æ¯è¾å¿«éçæ建ãèä¸æµè§å¨å¾æºè½ï¼é¼ æ å¨æºç ä¸çä½ç½®ï¼å¯ä»¥å¨ç½é¡µæ¾ç¤ºä¸åç°é´å½±ï¼è¿ä¸ªåè½ç®ç´å¤ªé¦äºã以ä¸çº¢æ¡å ææçµå½±ååçCSS表达å¼ä¹å¯ä»¥è¡¨ç¤ºä¸ºï¼ãdiv.movlist ul li a span.item-titleã
ç¶åç¨SelectorGadgetéªè¯ï¼å¦ä¸å¾ï¼åç°é«äº®éä¸çé¨åå°±æ¯ææ³è¦å®ä½çä¿¡æ¯ï¼è¯´æè¿ä¸ªCSS表达å¼æ£ç¡®ã
以ä¸ç®åä»ç»äºå¦ä½æ建CSS表达å¼ï¼å¨ç¬è«è¿ç¨ä¸å®ä½æåç¹å®èç¹æ°æ®æ¯é常éè¦çä¸æ¥ï¼æäºè¿æ¥ææä¸æ¸¸çç²¾åæ°æ®æåä¸æ¸ æ´ãå¸ææ¬æ¬¡æç¨è½ç»æéè¦çå°ä¼ä¼´ä¸ç¹å°å°å¸®å©ï¼
æ´å¤å 容å¯å ³æ³¨å ¬å ±å·âYJYæè½ä¿®ç¼â~~~
å¾æå顾
Rç¬è«å¨å·¥ä½ä¸çä¸ç¹å¦ç¨
Rç¬è«å¿ å¤åºç¡ââHTMLåCSSåè¯
Rç¬è«å¿ å¤åºç¡ââéæç½é¡µ+å¨æç½é¡µ
Rç¬è«å¿ å¤âârvestå ç使ç¨
@Import({ AutoConfigurationImportSelector.class})
ï¼2ï¼@Import({ AutoConfigurationImportSelector.class})ï¼å°AutoConfigurationImportSelectorè¿ä¸ªç±»å¯¼å ¥å°spring容å¨ä¸ï¼AutoConfigurationImportSelectorå¯ä»¥å¸®å©springbootåºç¨å°ææ符åæ¡ä»¶ç@Configurationé ç½®é½å è½½å°å½åSpringBootå建并使ç¨çIoC容å¨(ApplicationContext)ä¸
继ç»ç 究AutoConfigurationImportSelectorè¿ä¸ªç±»ï¼éè¿æºç åæè¿ä¸ªç±»ä¸æ¯éè¿selectImportsè¿ä¸ªæ¹æ³åè¯springbooté½éè¦å¯¼å ¥é£äºç»ä»¶ï¼

æ·±å ¥ç 究loadMetadataæ¹æ³

æ·±å ¥getCandidateConfigurationsæ¹æ³
个æ¹æ³ä¸æä¸ä¸ªéè¦æ¹æ³loadFactoryNamesï¼è¿ä¸ªæ¹æ³æ¯è®©SpringFactoryLoaderå»å è½½ä¸äºç»ä»¶çååã

继ç»ç¹å¼loadFactoryæ¹æ³
```java
public static ListloadFactoryNames(Class factoryClass, @Nullable ClassLoaderclassLoader) {
//è·ååºå ¥çé®
String factoryClassName = factoryClass.getName();
return(List)loadSpringFactories(classLoader).getOrDefault(factoryClassName,Collections.emptyList());
}
private static Map>loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap result =(MultiValueMap)cache.get(classLoader);
if (result != null) {
return result;
} else {
try {
//å¦æç±»å è½½å¨ä¸ä¸ºnullï¼åå 载类路å¾ä¸spring.factoriesæ件ï¼å°å ¶ä¸è®¾ç½®çé 置类çå ¨è·¯å¾ä¿¡æ¯å°è£ 为Enumeration类对象
Enumeration urls =classLoader != null ?classLoader.getResources("META-INF/spring.factories") :ClassLoader.getSystemResources("META-INF/spring.factories");
LinkedMultiValueMap result =new LinkedMultiValueMap();
//循ç¯Enumeration类对象ï¼æ ¹æ®ç¸åºçèç¹ä¿¡æ¯çæProperties对象ï¼éè¿ä¼ å ¥çé®è·åå¼ï¼å¨å°å¼åå²ä¸ºä¸ä¸ªä¸ªå°çå符串转å为Arrayï¼æ¹æ³resultéåä¸
while(urls.hasMoreElements()) {
URL url =(URL)urls.nextElement();
UrlResource resource = newUrlResource(url);
Properties properties =PropertiesLoaderUtils.loadProperties(resource);
Iterator var6 =properties.entrySet().iterator();
while(var6.hasNext()) {
Entry entry= (Entry)var6.next();
String factoryClassName= ((String)entry.getKey()).trim();
String[] var9 =StringUtils.commaDelimitedListToStringArray((String)entry.getValue());
int var =var9.length;
for(int var = 0;var < var; ++var) {
String factoryName= var9[var];
result.add(factoryClassName, factoryName.trim());
}
}
}
cache.put(classLoader, result);
return result;
```
ä¼å»è¯»åä¸ä¸ªsprin g.factoriesçæ件ï¼è¯»åä¸å°ä¼è¡¨è¿ä¸ªé误ï¼æ们继ç»æ ¹æ®ä¼çå°ï¼æç»è·¯å¾çé¿è¿æ ·ï¼èè¿ä¸ªæ¯springæä¾çä¸ä¸ªå·¥å ·ç±»
```java
public final class SpringFactoriesLoader {
public static final String FACTORIES_RESOURCE_LOCATION ="META-INF/spring.factories";
}
```
å®å ¶å®æ¯å»å è½½ä¸ä¸ªå¤é¨çæ件ï¼èè¿æ件æ¯å¨


@EnableAutoConfigurationå°±æ¯ä»classpathä¸æ寻META-INF/spring.factoriesé ç½®æ件ï¼å¹¶å°å ¶ä¸org.springframework.boot.autoconfigure.EnableutoConfiguration对åºçé 置项éè¿åå°ï¼Java Refletionï¼å®ä¾å为对åºçæ 注äº@ConfigurationçJavaConfigå½¢å¼çé 置类ï¼å¹¶å è½½å°IOC容å¨ä¸
以ååç项ç®ä¸ºä¾ï¼å¨é¡¹ç®ä¸å å ¥äºWebç¯å¢ä¾èµå¯å¨å¨ï¼å¯¹åºçWebMvcAutoConfigurationèªå¨é 置类就ä¼çæï¼æå¼è¯¥èªå¨é 置类ä¼åç°ï¼å¨è¯¥é 置类ä¸éè¿å ¨æ³¨è§£é 置类çæ¹å¼å¯¹Spring MVCè¿è¡æéç¯å¢è¿è¡äºé»è®¤é ç½®ï¼å æ¬é»è®¤åç¼ãé»è®¤åç¼ãè§å¾è§£æå¨ãMVCæ ¡éªå¨çãèè¿äºèªå¨é 置类çæ¬è´¨æ¯ä¼ ç»Spring MVCæ¡æ¶ä¸å¯¹åºçXMLé ç½®æ件ï¼åªä¸è¿å¨Spring Bootä¸ä»¥èªå¨é 置类çå½¢å¼è¿è¡äºé¢å é ç½®ãå æ¤ï¼å¨Spring Boot项ç®ä¸å å ¥ç¸å ³ä¾èµå¯å¨å¨åï¼åºæ¬ä¸ä¸éè¦ä»»ä½é 置就å¯ä»¥è¿è¡ç¨åºï¼å½ç¶ï¼æ们ä¹å¯ä»¥å¯¹è¿äºèªå¨é 置类ä¸é»è®¤çé ç½®è¿è¡æ´æ¹
**æ»ç»
**å æ¤springbootåºå±å®ç°èªå¨é ç½®çæ¥éª¤æ¯ï¼
1. springbootåºç¨å¯å¨ï¼
2. @SpringBootApplicationèµ·ä½ç¨ï¼
3. @EnableAutoConfigurationï¼
4. @AutoConfigurationPackageï¼è¿ä¸ªç»å注解主è¦æ¯@Import(AutoConfigurationPackages.Registrar.class)ï¼å®éè¿å°Registrarç±»å¯¼å ¥å°å®¹å¨ä¸ï¼èRegistrarç±»ä½ç¨æ¯æ«æ主é 置类å级ç®å½ä»¥ååå ï¼å¹¶å°ç¸åºçç»ä»¶å¯¼å ¥å°springbootå建管çç容å¨ä¸ï¼
5.
@Import(AutoConfigurationImportSelector.class)ï¼å®éè¿å°AutoConfigurationImportSelectorç±»å¯¼å ¥å°å®¹å¨ä¸ï¼AutoConfigurationImportSelectorç±»ä½ç¨æ¯éè¿selectImportsæ¹æ³æ§è¡çè¿ç¨ä¸ï¼ä¼ä½¿ç¨å é¨å·¥å ·ç±»SpringFactoriesLoaderï¼æ¥æ¾classpathä¸ææjarå ä¸çMETA-INF/spring.factoriesè¿è¡å è½½ï¼å®ç°å°é 置类信æ¯äº¤ç»SpringFactoryå è½½å¨è¿è¡ä¸ç³»åç容å¨å建è¿ç¨
åå¦äºæå¾æè²çãJavaå·¥ç¨å¸é«èªè®ç»è¥ãï¼çå°åå¦å°çç¹å°±åçäºãå¸ææå¾è½ç»ææ¨å°æ³å»çå ¬å¸ï¼ç®æ ï¼åèï¼ï¼
为什么 querySelectorAll 返回的不是 Array?
查询所有元素涉及到的规范与数组规范不同,因此查询所有元素返回的源码不是数组类型。
从规范角度看,源码查询所有元素属于 DOM 规范,源码而数组属于 ECMAScript 规范。源码DOM 规范强调平台中立性,源码如何显示exe源码但并未在规范中提及与数组相关的源码概念。
实际上,源码查询所有元素返回的源码是 NodeList 类型,这与数组有本质区别。源码Array 类型来源于 ECMAScript 规范,源码而 NodeList 则是源码 DOM 中用于表示一组节点的类。
具体到源码层面,源码Chromium 的源码实现中,查询所有元素返回的源码是 StaticElementList 类型。该类封装了选择器字符串并提供了节点集合,但与 JavaScript 数组的实现不同。
JavaScript 数组由 V8 引擎实现,其长度属性通过特定的偏移量在 JSArray 对象上获取。与此相反,StaticElementList 的长度属性计算逻辑与 JavaScript 数组完全不同。
综上,查询所有元素返回的 NodeList 不是 Array 类型的原因,主要在于两者所属的周期交易指标源码规范体系不同,以及在实现细节上的差异。
JQuery 的 deferred . promise对象
你说的这段描述是对 jQuery(selector).promise()的描述,并不是 jQuery.Deferred() 的描述。原文是:
Return a Promise object to observe when all actions of a certain type bound to the collection, queued or not, have finished.而这段话是说:
jQuery(selector).promise() 函数是返回一个 Promise 对象,这个对象的作用是当绑定到集合也就是$('div')这样取到的集合的指定类型的所有动作(promise方法的第一个参数 type ,默认是fx,也就是动画)是否已经完成了。英文水平有限,有些地方看不怎么懂,这话说得有点乱,不过意思应该是这样的,举个例子:
$('#message').animate({ width:, height:}, )
.promise()
.done(function(){
console.log('animate end');
});
也可以写成:
$('#message').animate({ width:, height:}, );var promise = $('#message').promise();
promise.done(function(){
console.log('animate end');
});
这里的 $('#message') 就是所说的collection,
而动画 animate (即 fx)就是 certain type,
里面的所有动作就是 action queue,当然,这里只有1个,就是默认的fx (但是文档中没有找到介绍其它的类型)。
后面的 var promise = xxx 就是指返回的 Promise对象,这个对象在收到animate 方法里面的信号(这个信号包括 resolve, reject, notify, resolveWith, rejectWith, and notifyWith等)可以调用方法done(当然还有不少其它的方法,这里没用到就不说了,自己看文档吧),然后执行done的回调函数了。
animate方法会自己发送promise的仙履奇缘源码信号,不用手动去处理。具体细节可以参考 jQuery.Deferred() 方法,在API的介绍中有这个方法的使用示例。
需要注意的是, jQuery(selector).promise()和jQuery.Deferred().promise()是不一样的。
从目前我知道的来说,jQuery(selector).promise() 是专门用来处理jquery中的动画(animate)使用的,而jQuery.Deferred().promise()使用的范围更广,没看源码,不过猜一下,我觉得 jQuery(selector).promise()是jQuery在动画的时候对jQuery.Deferred().promise()的特殊实现(或者叫做功能封装)。
然后再说一下jQuery.Deferred().promise()吧。它的一般用法为:
var defer= $.Deferred();$.when(defer.promise()).then<done|fail|....>(参数...)
defer.resolve('传参数或留空');
defer.reject('传参数或留空');
defer.notify('传参数或留空');
// ..... 其它信号
实例请自己去看API页面。
上面的defer是一个延迟对象(deferred)引用,表示这个对象的信号会在将来发出。
接下来的 $.when(defer.promise()) 是指jQuery 要监视 defer的信号,收到信号后执行后面的then(或者done, fail或其它)的函数。而后面的defer.resolve<reject|notify>则是发出信号,通知jQuery延迟调用已经执行了,jQuery收到信号后,就去调用这个延迟的promise()后面的函数。
RocketMQ第五讲
broker是RocketMQ的核心,核心工作就是真金牛牛源码接收生成这的消息,进行存储。同时,收到消费者的请求后,从磁盘读取内容,把结果返回给消费者。
消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G ,文件名长度为位,左边补零,剩余为起始偏移量,比如代表了第一个文件,起始偏移量为0,文件大小为1G=;当第一个文件写满了,第二个文件为,起始偏移量为,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件;
CommitLog文件中保存了消息的全量内容。不同的Topic的消息,在CommitLog都是顺序存放的。就是牌友贵州麻将源码来一个消息,不管Topic是什么,直接追加的CommitLog中。
broker启动了一个专门的线程来构建索引,把CommitLog中的消息,构建了两种类型的索引。ConsumerQueue和Index。正常消费的时候,是根据Topic来消费,会用到ConsumerQueue索引。
也可根据返回的offsetMsgId,解析出ip,端口和CommitLog中的物理消息偏移量,直接去CommitLog中取数据。
引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。
其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{ topic}/{ queueId}/{ fileName}。同样consumequeue文件采取定长设计,每一个条目共个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.M。
IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。Index文件的存储位置是: { fileName},文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为M,一个IndexFile可以保存 W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。
按照Message Key查询消息的时候,会用到这个索引文件。
IndexFile索引文件为用户提供通过“按照Message Key查询消息”的消息索引查询服务,IndexFile文件的存储位置是: { fileName},文件名fileName是以创建时的时间戳命名的,文件大小是固定的,等于+W 4+W = 个字节大小。如果消息的properties中设置了UNIQ_KEY这个属性,就用 topic + “#” + UNIQ_KEY的value作为 key 来做写入操作。如果消息设置了KEYS属性(多个KEY以空格分隔),也会用 topic + “#” + KEY 来做索引。
其中的索引数据包含了Key Hash/CommitLog Offset/Timestamp/NextIndex offset 这四个字段,一共 Byte。NextIndex offset 即前面读出来的 slotValue,如果有 hash冲突,就可以用这个字段将所有冲突的索引用链表的方式串起来了。Timestamp记录的是消息storeTimestamp之间的差,并不是一个绝对的时间。整个Index File的结构如图, Byte 的Header用于保存一些总的统计信息,4 W的 Slot Table并不保存真正的索引数据,而是保存每个槽位对应的单向链表的头。 W 是真正的索引数据,即一个 Index File 可以保存 W个索引。
“按照Message Key查询消息”的方式,RocketMQ的具体做法是,主要通过Broker端的QueryMessageProcessor业务处理器来查询,读取消息的过程就是用topic和key找到IndexFile索引文件中的一条记录,根据其中的commitLog offset从CommitLog文件中读取消息的实体内容。
RocketMQ中有两个核心模块,remoting模块和store模块。remoting模块在NameServer,Produce,Consumer和Broker都用到。store只在Broker中用到,包含了存储文件操作的API,对消息实体的操作是通过DefaultMessageStore进行操作。
属性和方法很多,就不往这里放了。
文件存储实现类,包括多个内部类
· 对于文件夹下的一个文件
上面介绍了broker的核心业务流程和架构,关键接口和类,启动流程。最后介绍一下broker的线程模型,只有知道了线程模型,才能大概知道前面介绍的那些事如何协同工作的,对broker才能有一个立体的认识。
RocketMQ的RPC通信采用Netty组件作为底层通信库,同样也遵循了Reactor多线程模型,同时又在这之上做了一些扩展和优化。关于Reactor线程模型,可以看看我之前写的这篇文档: Reactor线程模型
上面的框图中可以大致了解RocketMQ中NettyRemotingServer的Reactor 多线程模型。一个 Reactor 主线程(eventLoopGroupBoss,即为上面的1)负责监听 TCP网络连接请求,建立好连接,创建SocketChannel,并注册到selector上。RocketMQ的源码中会自动根据OS的类型选择NIO和Epoll,也可以通过参数配置),然后监听真正的网络数据。拿到网络数据后,再丢给Worker线程池(eventLoopGroupSelector,即为上面的“N”,源码中默认设置为3),在真正执行业务逻辑之前需要进行SSL验证、编解码、空闲检查、网络连接管理,这些工作交给defaultEventExecutorGroup(即为上面的“M1”,源码中默认设置为8)去做。而处理业务操作放在业务线程池中执行,根据 RomotingCommand 的业务请求码code去processorTable这个本地缓存变量中找到对应的 processor,然后封装成task任务后,提交给对应的业务processor处理线程池来执行(sendMessageExecutor,以发送消息为例,即为上面的 “M2”)。
上面的图和这段画是从官方文档抄过来的,但是文字和图对应的不是很好,画的也不够详细,但是主要流程是这个样子。以后有时间了,我重新安装自己的理解,画一张更详细的图。
AsyncAppender-Worker-Thread-0:异步打印日志,logback使用,应该是守护线程
FileWatchService:
NettyEventExecutor:
NettyNIOBoss_:一个
NettyServerNIOSelector_:默认为三个
NSScheduledThread:定时任务线程
ServerHouseKeepingService:守护线程
ThreadDeathWatch-2-1:守护线程,Netty用,已经废弃
RemotingExecutorThread(1-8):工作线程池,没有共用NettyServerNIOSelector_,直接初始化8个线程
AsyncAppender-Worker-Thread-0:异步打印日志,logback使用,共九个:
RocketmqBrokerAppender_inner
RocketmqFilterAppender_inner
RocketmqProtectionAppender_inner
RocketmqRemotingAppender_inner
RocketmqRebalanceLockAppender_inner
RocketmqStoreAppender_inner
RocketmqStoreErrorAppender_inner
RocketmqWaterMarkAppender_inner
RocketmqTransactionAppender_inner
SendMessageThread_:remotingServer.registerProcessor(RequestCode.SEND_MESSAGE
PullMessageThread_:remotingServer.registerProcessor(RequestCode.PULL_MESSAGE
ProcessReplyMessageThread_:remotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE
QueryMessageThread_:remotingServer.registerProcessor(RequestCode.QUERY_MESSAGE
AdminBrokerThread_:remotingServer.registerDefaultProcessor
ClientManageThread_:remotingServer.registerProcessor(RequestCode.UNREGISTER_CLIENT
HeartbeatThread_:remotingServer.registerProcessor(RequestCode.HEART_BEAT
EndTransactionThread_:remotingServer.registerProcessor(RequestCode.END_TRANSACTION
ConsumerManageThread_:remotingServer.registerProcessor(RequestCode.GET_CONSUMER_LIST_BY_GROUP,RequestCode.UPDATE_CONSUMER_OFFSET,RequestCode.QUERY_CONSUMER_OFFSET
brokerOutApi_thread_:BrokerController.registerBrokerAll(true, false, true);
==================================================================
BrokerControllerScheduledThread:=>
BrokerController.this.getBrokerStats().record();
BrokerController.this.consumerOffsetManager.persist();
BrokerController.this.consumerFilterManager.persist();
BrokerController.this.protectBroker();
BrokerController.this.printWaterMark();
log.info("dispatch behind commit log { } bytes", BrokerController.this.getMessageStore().dispatchBehindBytes());
BrokerController.this.brokerOuterAPI.fetchNameServerAddr();
BrokerController.this.printMasterAndSlaveDiff();
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
BrokerFastFailureScheduledThread:=>
FilterServerManagerScheduledThread:=>
FilterServerManager.this.createFilterServer();
ClientHousekeepingScheduledThread:=>
ClientHousekeepingService.this.scanExceptionChannel();
PullRequestHoldService
FileWatchService
AllocateMappedFileService
AcceptSocketService
BrokerStatsThread1





