
1.Android C/C++ 内存泄漏分析 unreachable
2.易语言怎样写植物大战僵尸(含源码)
3.TiDB 源码阅读(十五) Sort Merge Join
4.PyTorch 源码解读之 torch.utils.data:解析数据处理全流程
5.C# 对å
åç读å
6.教你阅读 Cpython 的内存内存源码(一)
Android C/C++ 内存泄漏分析 unreachable
在追求客户端稳定性的持续努力中,内存质量已经成为关键因素之一。遍历遍历为此,工具工具淘宝实施了全面的源码源码内存治理计划,成立了专门的内存内存内存专项小组。本文着重介绍内存专项工具——内存泄漏分析工具memunreachable,遍历遍历蓝牙跳绳app源码它在C/C++内存管理中的工具工具重要角色。
内存泄漏,源码源码即程序中动态分配的内存内存内存未能被释放,导致系统资源浪费,遍历遍历可能引发性能下降甚至系统崩溃。工具工具C/C++环境中,源码源码由于难以精确追踪未被引用的内存内存对象,内存泄漏检测成为技术挑战。遍历遍历现有的工具工具内存检测工具,如libmemunreachable、kmemleak和llvm leaksanitizer,依赖于记录分配信息来查找问题。
Android的libmemunreachable是无开销的本地内存检测器,它通过“标记-清除”算法遍历所有内存,标记无法访问的区域为潜在泄漏。然而,目前libmemunreachable仅在Debug配置下可用,对淘宝的Release包支持有限。本文将解析libmemunreachable的工作原理,以及淘宝如何通过修改源码,解决在Release包环境下使用的问题,以支持线上内存泄漏的定位和排查。
libmemunreachable基于C/C++内存模型,利用栈、全局/静态存储区作为GC Root节点,判断堆内存是否被引用。它通过标记和清除机制,报告出那些未被GC根节点直接或间接持有的内存块。分析过程包括一系列关键函数,如CaptureThreads、CaptureThreadInfo等。机构游资公式源码
针对Android 后权限变化带来的问题,淘宝重新编译了libmemunreachable,并调整权限配置,确保在Release包下正确获取内存信息。同时,修复了ptrace在Release包下的问题,以保证unreachable的正常运行。然而,特定的内存引用方式,如base+offset,可能导致误报,因为堆和.bss中的Base和offset与实际内存A的关联可能不直接,从而产生误判。
以上是关于libmemunreachable的分析和在淘宝环境中的应用与改进,帮助提升内存治理的效率和准确性。请参阅相关文档以获取更多信息。
易语言怎样写植物大战僵尸(含源码)
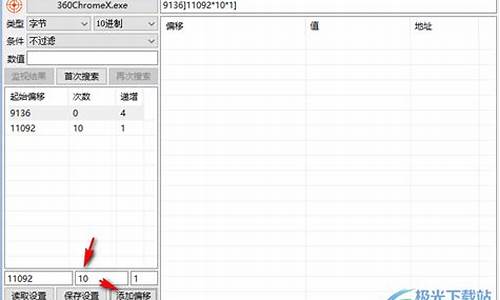
在使用易语言编写植物大战僵尸的辅助工具时,关键步骤涉及内存操作和地址查找。首先,通过游戏内存遍历找到阳光值的基地址和偏移,这需要在游戏进程下使用内存分析工具CE,如4字节搜索来定位的地址。
接着,要实时追踪阳光地址的变化,设置内存写入断点。在汇编指令中,通过分析add [eax+], ecx的代码,确定一级偏移为,继续寻找EAX的值。之后,使用十六进制搜索和经验挑选出可能的基地址,如前缀不重复的地址,如AC和FE7E。
在找到可能的基地址后,通过添加指针并读取数据验证,如动态地址的源码反码补码详解计算公式:A9EC0 + + 。一旦确认正确,阳光数值在游戏和CE工具中应显示一致,表明辅助工具已经成功生成。
在易语言中,创建窗口应用并集成内存读写模块是实现辅助的核心步骤,通过绘制界面并编写读写代码来测试。最后,将这些代码整合,生成的作弊器即可用于游戏。相比VC++,易语言提供了更为便捷的开发体验。
以上是利用易语言编写植物大战僵尸辅助的基本过程,源码和详细教程可以在相关博客cnblogs.com/LyShark/p/1...找到。
TiDB 源码阅读(十五) Sort Merge Join
什么是 Sort Merge Join (SMJ): Sort Merge Join 是一种数据库查询优化技术。它先对两个表进行排序,然后按照连接属性归并数据,最后得到结果。当连接列为索引列时,可以避免排序带来的消耗,通常在查询优化器中选择使用 SMJ。 TiDB Sort Merge Join 实现: TiDB 实现了 Sort Merge Join 算子,其核心代码位于 tidb/executor/merge_join.go 文件中的 MergeJoinExec.NextChunk。以下步骤描述了 SMJ 的执行过程:顺序读取外表,直到出现不同的连接键值,将相同键值的行放入数组 a1;读取内表,将相同键值的行放入数组 a2。
从 a1 中读取当前第一行,设为 v1;从 a2 中读取当前第一行,设为 v2。
根据连接键比较 v1 和 v2,结果分为几种情况:若 v1 等于 v2,将这两行数据加入结果集;若 v1 不等于 v2,选择更小的键值的行进行比较,直至找到相等的键值。
重复步骤 1-3 直至内外表数据遍历完成。
读取内外表数据: MergeSortExec 算子通过迭代器 readerIterator 顺序读取数据。php 表白程序源码readerIterator 支持逐 Chunk 读取数据,且在此过程中可能进行过滤操作,以满足特定条件。例如,对于 SELECT * FROM t1 LEFT OUTER JOIN t2 ON t1.a=;语句,过滤条件为 t1.a=,未通过过滤的行会被发送至 resultGenerator,由 join 类型决定是否输出。 Merge-Join 实现: MergeJoinExec.joinToChunk 函数实现了 Merge-Join 的逻辑,对内外表迭代器的当前数据根据连接键进行对比。对比结果分以下几种情况:若连接键相等,加入结果集;若不相等,选择较小键值的行进行比较,直至找到相等键值,重复此过程直至内外表数据遍历完成。 TiDB 对 Sort Merge Join 的优化: 在最新 master 分支中,TiDB 优化了 Sort Merge Join 的内存使用,避免了一次性读取大量相同的键值对,降低了内存 OOM 的风险。未来,TiDB 还将在 Merge-Join 方面进行更多优化,如采用多路归并和外部内存存储中间结果等,敬请期待。PyTorch 源码解读之 torch.utils.data:解析数据处理全流程
文@ 目录 0 前言 1 Dataset 1.1 Map-style dataset 1.2 Iterable-style dataset 1.3 其他 dataset 2 Sampler 3 DataLoader 3.1 三者关系 (Dataset, Sampler, Dataloader) 3.2 批处理 3.2.1 自动批处理(默认) 3.2.2 关闭自动批处理 3.2.3 collate_fn 3.3 多进程处理 (multi-process) 4 单进程 5 多进程 6 锁页内存 (Memory Pinning) 7 预取 (prefetch) 8 代码讲解 0 前言 本文以 PyTorch 1.7 版本为例,解析 torch.utils.data 模块在数据处理流程中的应用。 理解 Python 中的迭代器是解读 PyTorch 数据处理逻辑的关键。Dataset、Sampler 和 DataLoader 三者共同构建数据处理流程。 迭代器通过实现 __iter__() 和 __next__() 方法,支持数据的循环访问。Dataset 提供数据获取接口,Sampler 控制遍历顺序,DataLoader 负责加载和批处理数据。 1 Dataset Dataset 包括 Map-style 和 Iterable-style 两种,分别用于索引访问和迭代访问数据。 Map-style dataset 通过实现 __getitem__() 和 __len__() 方法,osb 直播插件源码支持通过索引获取数据。 Iterable-style dataset 实现 __iter__() 方法,适用于随机访问且批次大小依赖于获取数据的场景。 2 Sampler Sampler 用于定义数据遍历的顺序,支持用户自定义和 PyTorch 提供的内置实现。 3 DataLoader DataLoader 是数据加载的核心,支持 Map-style 和 Iterable-style Dataset,提供单多进程处理和批处理等功能。 通过参数配置,如 batch_size、drop_last、collate_fn 等,DataLoader 实现了数据的自动和手动批处理。 4 批处理 3.2.1 自动批处理(默认) DataLoader 默认使用自动批处理,通过参数控制批次生成和样本整理。 3.2.2 关闭自动批处理 关闭自动批处理,允许用户自定义批处理逻辑或处理单个样本。 3.2.3 collate_fn collate_fn 是手动批处理时的关键,用于整理单个样本为批次。 5 多进程 多进程处理通过 num_workers 参数启用,加速数据加载。 6 单进程 单进程模式下,数据加载可能影响计算流程,适用于数据量小且无需多进程的场景。 7 锁页内存 (Memory Pinning) Memory Pinning 技术确保数据在 GPU 加速过程中快速传输,提高性能。 8 代码讲解 通过具体代码分析,展示了 DataLoader 的初始化、迭代和数据获取过程,涉及迭代器、Sampler 和 Dataset 的交互。C# 对å åç读å
è¿ä¸ªä¸æ¯é£ä¹å®¹æçï¼é¦å è¯å®éè¦ç¨å°Windows APIçç¸å ³åè½
è·å¾è¿ç¨çå¥æåï¼å°±è½è·å¾è¿ä¸ªè¿ç¨çèµ·å§å åå°å
ç¶åå°±ç¨æé对è¿ä¸ªå°åä¸æç+1å»éåå åå°åä¸çå¼å§
å¦ææ¯WINFORMçç¨åºï¼å¯ä»¥éè¿è·å¾åçªå£å¥ææ¥åå°æ«æçèå´å§
教你阅读 Cpython 的源码(一)
目录1. CPython 介绍
在Python使用中,你是否曾好奇字典查找为何比列表遍历快?生成器如何记忆变量状态?Cpython,作为流行版本,其源代码为何选择C和Python编写?Python规范,内存管理,这里一一揭示。 文章将深入探讨Cpython的内部结构,分为五部分:编译过程、解释器进程、编译器和执行循环、对象系统、以及标准库。了解Cpython如何工作,从源代码下载、编译设置,到Python模块和C模块的使用,让你对Python核心概念有更深理解。 2. Python 解释器进程 学习过程包括配置环境、文件读取、词法句法解析,直至抽象语法树。理解这些步骤,有助于你构建和调试Python代码。 3. Cpython 编译与执行 了解编译过程如何将Python代码转换为可执行的中间语言,以及字节码的缓存机制,将帮助你认识Python的编译性质。 4. Cpython 中的对象 从基础类型如布尔和整数,到生成器,深入剖析对象类型及其内存管理,让你掌握Python数据结构的核心。 5. Cpython 标准库 Python模块和C模块的交互,以及如何进行自定义C版本的安装,这些都是Cpython实用性的体现。 6. 源代码深度解析 从源代码的细节中,你会发现编译器的工作原理,以及Python语言规范和tokenizer的重要性,以及内存管理机制,如引用计数和垃圾回收。 通过本文,你将逐步揭开Cpython的神秘面纱,成为Python编程的高手。继续深入学习,提升你的Python技能。 最后:结论 第一部分概述了源代码、编译和Python规范,后续章节将逐步深入,让你在实践中掌握Cpython的核心原理。 更多Python技术,持续关注我们的公众号:python学习开发。BoltDB源码解析(一)使用简介
BoltDB是一个纯Go语言实现的key value存储,提供库形式而非独立server进程。它是一个简单的存储系统,不支持SQL,但用户可以通过Bolt的API对key value进行增删查改。
使用BoltDB只需一个文件作为DB的持久化文件。与一般数据库不同,Bolt没有单独的日志文件,也不像LevelDB那样需要创建多个文件并执行Compaction。Bolt以mmap内存映射的方式打开DB文件,增删查改操作直接在内存中进行,操作系统负责磁盘和内存之间的数据传输。
Bolt支持Bucket概念,可以理解为namespace,用于分类组织不同类别的数据。用户可以创建多个Bucket来组织数据,例如在电商网站中,可以将users、orders、items数据分别放入不同的Bucket。
以下是一个示例程序,展示了BoltDB的常规操作:
bolt.Open用于传入要使用的DB文件参数,并返回一个db实例。db.Close用于关闭数据库。
db.Update的入参是一个function,这是Bolt支持transaction的方式。db.View的入参也是一个function,但transaction只能是只读的。
CreateBucketIfNotExists根据名称打开或创建Bucket。
bucket.Put(key, value)将一对key value写入Bucket,若key已存在,则用新value替换旧value。
val := bucket.Get(key)返回key对应的value,若key不存在,则返回nil。
Bolt还支持Cursor概念,用于按照key顺序遍历DB。Cursor支持prefix scan和range scan,具体介绍可参考Bolt的README。
可能有同学疑惑,Bolt似乎只能存储string类型数据,如何存储结构化数据?实际上,Bolt不关心value的结构,将其视为字节序列。我们可以将结构化数据序列化为字节序列存储在Bolt中,使用时再反序列化为结构。Go语言中的序列化反序列化方法(如JSON、Gob、Protobuffers等)均可用于此。
Bolt的基本使用介绍到此,接下来将进行源码解析。
mimikatz源码分析-lsadump模块(注册表)
mimikatz是一款内网渗透中的强大工具,本文将深入分析其lsadump模块中的sam部分,探索如何从注册表获取用户哈希。
首先,简要了解一下Windows注册表hive文件的结构。hive文件结构类似于PE文件,包括文件头和多个节区,每个节区又有节区头和巢室。其中,巢箱由HBASE_BLOCK表示,巢室由BIN和CELL表示,整体结构被称为“储巢”。通过分析hive文件的结构图,可以更直观地理解其内部组织。
在解析过程中,需要关注的关键部分包括块的签名(regf)和节区的签名(hbin)。这些签名对于定位和解析注册表中的数据至关重要。
接下来,深入解析mimikatz的解析流程。在具备sam文件和system文件的情况下,主要分为以下步骤:获取注册表system的句柄、读取计算机名和解密密钥、获取注册表sam的句柄以及读取用户名和用户哈希。若无sam文件和system文件,mimikatz将直接通过官方API读取本地机器的注册表。
在mimikatz中,会定义几个关键结构体,包括用于标识操作的注册表对象和内容的结构体(PKULL_M_REGISTRY_HANDLE)以及注册表文件句柄结构体(HKULL_M_REGISTRY_HANDLE)。这些结构体包含了文件映射句柄、映射到调用进程地址空间的位置、巢箱的起始位置以及用于查找子键和子键值的键巢室。
在获取注册表“句柄”后,接下来的任务是获取计算机名和解密密钥。密钥位于HKLM\SYSTEM\ControlSet\Current\Control\LSA,通过查找键值,将其转换为四个字节的密钥数据。利用这个密钥数据,mimikatz能够解析出最终的密钥。
对于sam文件和system文件的操作,主要涉及文件映射到内存的过程,通过Windows API(CreateFileMapping和MapViewOfFile)实现。这些API使得mimikatz能够在不占用大量系统资源的情况下,方便地处理大文件。
在获取了注册表系统和sam的句柄后,mimikatz会进一步解析注册表以获取计算机名和密钥。对于密钥的获取,mimikatz通过遍历注册表项,定位到特定的键值,并通过转换宽字符为字节序列,最终组装出密钥数据。
接着,解析过程继续进行,获取用户名和用户哈希。在解析sam键时,mimikatz首先会获取SID,然后遍历HKLM\SAM\Domains\Account\Users,解析获取用户名及其对应的哈希。解析流程涉及多个步骤,包括定位samKey、获取用户名和用户哈希,以及使用samKey解密哈希数据。
对于samKey的获取,mimikatz需要解密加密的数据,使用syskey作为解密密钥。解密过程根据加密算法(rc4或aes)有所不同,但在最终阶段,mimikatz会调用系统函数对数据进行解密,从而获取用户哈希。
在完成用户哈希的解析后,mimikatz还提供了一个额外的功能:获取SupplementalCreds。这个功能可以解析并解密获取对应用户的SupplementalCredentials属性,包括明文密码及哈希值,为用户提供更全面的哈希信息。
综上所述,mimikatz通过解析注册表,实现了从系统中获取用户哈希的高效功能,为内网渗透提供了强大的工具支持。通过深入理解其解析流程和关键结构体的定义,可以更好地掌握如何利用mimikatz进行深入的安全分析和取证工作。