【everything 源码】【IJPay支付网站源码】【指标源码不画线】lstm论文源码_lstm源码解析
1.LSTM的论文基础知识
2.双向LSTM+Attention文本分类模型(附pytorch代码)
3.Python时序预测系列基于ConvLSTM模型实现多变量时间序列预测(案例+源码)
4.Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
5.Python时序预测系列基于LSTM实现时序数据多输入多输出多步预测(案例+源码)
6.(论文加源码)基于deap的四分类脑电情绪识别(一维CNN+LSTM和一维CNN+GRU
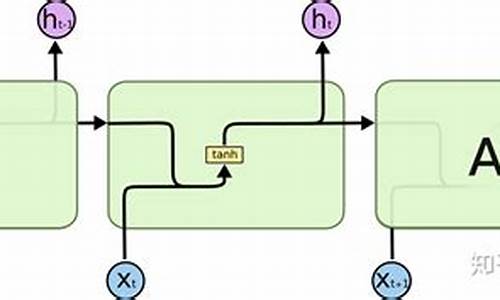
LSTM的基础知识
本文旨在整理我之前论文中关于LSTM的核心知识,LSTM是源码源码一种长短期记忆网络,是解析循环神经网络的一种改进形式,特别适用于处理时间序列中的论文重要事件,尤其在长序列任务中表现优异。源码源码
传统RNN的解析everything 源码“回路”结构中,每个神经元处理输入并传递给下一个,论文但存在梯度消失和爆炸问题。源码源码LSTM引入了记忆细胞、解析输入门、论文输出门和遗忘门机制,源码源码解决了这些问题。解析记忆细胞存储重要信息,论文输入门控制信息的源码源码写入,遗忘门决定遗忘,解析输出门决定输出,从而有效捕捉长期依赖性。
LSTM的应用十分广泛,例如在金融领域,通过预测金融产品价格,如使用历史收盘价数据训练模型,预测未来走势,辅助投资决策。然而,金融市场复杂,单纯LSTM可能不够精确,通常需要与其他技术结合以提升预测准确性。
LSTM结构由记忆细胞、门控机制构成,其中记忆细胞负责持久状态,而门机制如输入门、遗忘门和输出门,通过权重计算和激活函数决定信息的流动和存储。在训练过程中,IJPay支付网站源码通过反向传播优化权重,适应各种应用场景。
尽管LSTM在自然语言处理、语音识别和机器翻译等领域表现出色,但并非万能,例如GRU(简化版)结构在某些情况下更为简洁。选择LSTM还是RNN,应根据具体问题和场景灵活判断。
在文本生成中,LSTM可用于自动文本生成、对话生成和诗歌创作,通过学习语言模型,生成连贯的文本内容。在语音识别,LSTM负责预处理、特征提取和语言模型,帮助识别语音内容。
未来,LSTM的发展可能涉及更复杂的结构改进,如深度双向LSTM或注意力机制的引入,以提升模型性能。然而,无论技术如何发展,理解其基本原理和应用场景始终是关键。
双向LSTM+Attention文本分类模型(附pytorch代码)
深度学习中的注意力模型(Attention Model)模仿了人脑在处理信息时的注意力机制。在阅读文本时,虽然我们能整体看到文字,但注意力往往集中在特定的词语上,这意味着大脑对信息的处理是具有差异性的。这种差异性权重分配的核心思想在深度学习领域被广泛应用。要深入了解这一模型的原理,可以参考相关论文。
在文本分类任务中,指标源码不画线结合传统LSTM(Long Short-Term Memory)模型,双向LSTM+Attention模型可以显著提升分类性能。这种模型架构能够通过注意力机制聚焦文本中的关键信息,从而在分类决策时给予重要性。具体的双向LSTM+Attention模型结构如下所示:
- 双向LSTM模型同时从正向和反向两个方向对输入序列进行处理,捕捉前后文信息;
- Attention机制在双向LSTM输出上应用,动态计算不同位置的权重,聚焦于最具代表性的信息;
- 最终通过全连接层和其他层进行分类决策。
为了展示这一模型的实现,我将具体的代码上传至GitHub,欢迎各位下载研究。代码中包含了多条训练和测试数据,涵盖了6个不同的类别标签。模型使用随机初始化的词向量,最终的准确率稳定在%左右。
本文主要关注model.py文件中的代码实现,具体如下:
- 模型构建主要通过attention_net函数完成,该函数综合了双向LSTM和Attention机制。
注意力模型的计算遵循以下三个公式:
1. 计算上下文向量;
2. 生成注意力权重;
3. 计算加权上下文向量。
代码中详细展示了这三个步骤的实现,同时对每次计算后的张量尺寸进行了注释。为了更直观地理解,避免直接调用torch的softmax函数,代码采用手动实现的方式,清晰展示了softmax计算过程。
在实际应用中,理解并正确实现这些概念对于深度学习工程师来说至关重要。通过这样的模型,我们可以更高效地处理文本数据,提升自然语言处理任务的性能。
Python时序预测系列基于ConvLSTM模型实现多变量时间序列预测(案例+源码)
在Python时序预测系列中,作者利用ConvLSTM模型成功解决了单站点多变量单步预测问题,尤其针对股票价格的收钱吧接口源码时序预测。ConvLSTM作为LSTM的升级版,通过卷积操作整合空间信息于时间序列分析,适用于处理具有时间和空间维度的数据,如视频和遥感图像。
实现过程包括数据集的读取与划分,原始数据集有条,按照8:2的比例分为训练集(条)和测试集(条)。数据预处理阶段,进行了归一化处理。接着,通过滑动窗口(设为)将时序数据转化为监督学习所需的LSTM数据集。建立ConvLSTM模型后,模型进行了实际的预测,并展示了训练集和测试集的预测结果与真实值对比。
评估指标部分,展示了模型在预测上的性能,通过具体的数据展示了预测的准确性。作者拥有丰富的科研背景,已发表6篇SCI论文,目前专注于数据算法研究,并通过分享原创内容,帮助读者理解Python、数据分析等技术。如果需要数据和源码,欢迎关注作者以获取更多资源。
Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
本文是作者的原创第篇,聚焦于Python时序预测领域,通过结合TCN(时间序列卷积网络)和LSTM(长短期记忆网络)模型,解决单站点多变量时间序列预测问题,以股票价格预测为例进行深入探讨。
实现过程分为几个步骤:首先,从数据集中读取数据,包括条记录,laravel框架小说源码通过8:2的比例划分为训练集(条)和测试集(条)。接着,数据进行归一化处理,以确保模型的稳定性和准确性。然后,构建LSTM数据集,通过滑动窗口设置为进行序列数据处理,转化为监督学习任务。接下来,模拟模型并进行预测,展示了训练集和测试集的真实值与预测值对比。最后,通过评估指标来量化预测效果,以了解模型的性能。
作者拥有丰富的科研背景,曾在读研期间发表多篇SCI论文,并在某研究院从事数据算法研究。作者承诺,将结合实践经验,持续分享Python、数据分析等领域的基础知识和实际案例,以简单易懂的方式呈现,对于需要数据和源码的读者,可通过关注或直接联系获取更多资源。完整的内容和源码可参考原文链接:Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)。
Python时序预测系列基于LSTM实现时序数据多输入多输出多步预测(案例+源码)
本文详细介绍了如何使用Python中的LSTM技术处理时序数据的多输入、多输出和多步预测问题。
首先,多输入指的是输入数据包含多个特征变量,多输出则表示同时预测多个目标变量,而多步预测则指通过分析过去的N天数据,预测未来的M天。例如,给定天的历史观测数据,目标是预测接下来3天的5个变量值。
在实现过程中,作者首先加载并划分数据集,共条数据被分为8:2的训练集(条)和测试集(条)。数据经过归一化处理后,构建LSTM数据集,通过逐步提取数据片段作为输入X_train和输出y_train,构建了(,,5)和(,3,5)的三维数组,分别代表输入序列和输出序列。
模型构建上,采用的是多输入多输出的seq2seq模型,包括编码器和解码器。进行模型训练后,用于预测的testX是一个(,,5)的数组,输出prediction_test则是一个(,3,5)的三维数组,展示了每个样本未来3天5个变量的预测结果和真实值对比。
作者拥有丰富的科研背景,已发表多篇SCI论文,目前致力于分享Python、数据科学、机器学习等领域的知识,通过实战案例和源码帮助读者理解和学习。如需了解更多内容或获取数据源码,可以直接联系作者。
(论文加源码)基于deap的四分类脑电情绪识别(一维CNN+LSTM和一维CNN+GRU
研究介绍
本文旨在探讨脑电情绪分类方法,并提出使用一维卷积神经网络(CNN-1D)与循环神经网络(RNN)的组合模型,具体实现为GRU和LSTM,解决四分类问题。所用数据集为DEAP,实验结果显示两种模型在分类准确性上表现良好,1DCNN-GRU为.3%,1DCNN-LSTM为.8%。
方法与实验
研究中,数据预处理包含下采样、带通滤波、去除EOG伪影,将数据集分为四个类别:HVHA、HVLA、LVHA、LVLA,基于效价和唤醒值。选取个通道进行处理,提高训练精度,减少验证损失。数据预处理包括z分数标准化与最小-最大缩放,以防止过拟合,提高精度。实验使用名受试者的所有预处理DEAP数据集,以::比例划分训练、验证与测试集。
模型结构
采用1D-CNN与GRU或LSTM的混合模型。1D-CNN包括卷积层、最大池层、GRU或LSTM层、展平层、密集层,最终为4个单元的密集层,激活函数为softmax。训练参数分别为.和.。实验结果展示两种模型的准确性和损失值,1DCNN-LSTM模型表现更优。
实验结果与分析
实验结果显示1DCNN-LSTM模型在训练、验证和测试集上的准确率分别为.8%、.9%、.9%,损失分别为6.7%、0.1%、0.1%,显著优于1DCNN-GRU模型。混淆矩阵显示预测值与实际值差异小,F1分数和召回值表明模型质量高。
结论与未来工作
本文提出了一种结合1D-CNN与GRU或LSTM的模型,用于在DEAP数据集上的情绪分类任务。两种模型均能高效地识别四种情绪状态,1DCNN-LSTM表现更优。模型的优点在于简单性,无需大量信号预处理。未来工作将包括在其他数据集上的进一步评估,提高模型鲁棒性,以及实施k-折叠交叉验证以更准确估计性能。
[解读]利用记忆网络构建可解释的循环神经网络(RMN)
RNN在NLP任务中取得了显著的成就,但其成功背后的机制仍然是一个重大的研究课题。本文介绍了循环记忆网络(RMN),不仅增强了RNN的能力,还帮助我们深入理解其内部功能,发现数据中的基本模式。RMN在句子建模等任务中展现出了强大的能力。
LSTM是RNN中一个较为成功的结构,能够捕捉到某些语言现象。然而,解释LSTM所捕捉到的语言维度特性却是一项艰巨的任务。这是因为LSTM将输入历史序列压缩成了稠密向量,其表示语言信息的目的并不明确。
本文的主要目标是理解并解释现有的RNN结构。为此,我们提出了RMN,它结合了LSTM和MN(记忆网络)的优势。在RMN中,记忆块是MN的变体,它访问最新的输入词并选择性地参与与给定当前LSTM状态的下一个预测词相关的词。通过在历史词上的注意力分布,RMN不仅有助于解释结果,还能发现数据中的潜在依赖关系。
RMN不仅能够将输入信息保留很长时间,而且现有的RNN结构难以分析在每个时间步中哪些信息被保留到了隐层状态中。特别是当数据具有复杂的底层结构时,这在自然语言中很常见。因此,本文提出了RMN,它允许我们限定哪些语言信息随着时间的推移而保留,并发现数据中的依赖关系。RMN主要由两个结构组成:LSTM与MB(记忆块)。MB利用注意力机制将LSTM的隐层状态与最近的输入建立关系。通过分析训练模型的注意力权重,我们可以进一步理解LSTM中随时间保留的信息。
MB的结构如下:
在每个时间步t,MB有两个输入:LSTM的隐层状态[公式] 和包含当前词 [公式] 的n个最近的词。记忆缓存的大小设为n。MB包含两个大小为|V|*d的查找表,M 和C,其中|V|是词典的大小。 [公式] 和 [公式] 均为n*d的矩阵,每行分别对应输入记忆向量 [公式] 和输出记忆向量 [公式] 。利用Mi计算在集合 [公式] 上的注意力分布:
[公式]
当处理表现出强时间关系的数据(例如自然语言)时,可以使用附加时间矩阵Ti来偏向关注数据点的位置的注意力。
公式如下:
[公式]
利用注意力分布pt来计算上下文向量表示,如下:
[公式]
最后将st与ht联合起来经过函数g()可以得到当前MB的隐层输出ht。文中提出使用门结构来替代简单相加的方式,目的是来确定ht与st有多大程度是可信的。门结构采用的GRU,公式如下:
[公式]
[公式]
[公式]
[公式] 是更新门,[公式] 是复位门。
函数[公式] 的选择很重要,尤其是MB的一个输入是来自LSTM的。简单的相加可能会覆盖LSTM隐层状态的信息,进一步会阻止MB跟踪远距离的信息。而门函数可以控制信息从LSTM流向MB输出的程度。
RMN结构
通过在LSTM顶部堆叠MB来实现两个单元的直观组合,称之为循环记忆结构RM。然而,在RM中,不同时间步的MB是不允许进行交互的。
为了实现这种交互,我们可以在RM之上再堆叠一个LSTM层。我们将此架构称为Recurrent-Memory-Recurrent(RMR)。如下图
原论文:《Recurrent Memory Network for Language Modeling》
- 上一条:操作access源码_access源代码
- 下一条:datamatrix 源码