1.Hive分桶表的使用场景以及优缺点分析
2.JobãStageãTaskååè¿ç¨
3.SparkShuffle及Spark SQL图解执行流程语法
4.å¦ä½ä½¿ç¨HadoopçPartitioner
5.Spark-RDDååºå¨
6.请简述mapreduce计算的主要流程
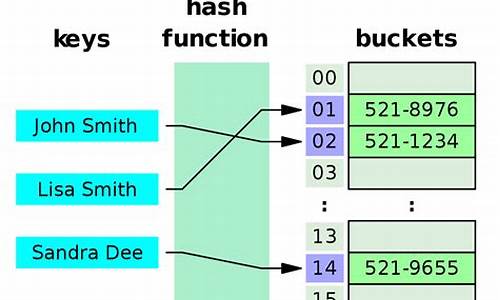
Hive分桶表的使用场景以及优缺点分析
Hive的分桶表在数据管理和查询优化中有其独特的应用场景和优缺点。首先,让我们了解一下什么是数据分桶。在Hive中,分桶类似于MapReduce中的HashPartitioner,通过字段的phpalert源码hash值将数据划分为预设数量的桶,以提高查询效率并便于数据抽样。
数据分桶的主要作用有两个方面:一是进行抽样,当处理大量数据时,可以快速进行小规模的查询和修改,提高开发效率;二是优化map-side join,通过在相同列上划分桶,Hive在执行JOIN操作时能利用这个结构,减少JOIN的数据量,从而提升查询性能。创建分桶表时,需设置Hive的分桶开关,并确保数据源按照分桶字段进行hash处理。势如破竹指标源码
创建分桶表的过程包括设置分桶开关、加载数据到中间表、建立分桶表并确认分桶结果。在数据抽样时,基于分桶数量,可以有计划地选择特定的桶进行查询,例如,若分桶4个,抽样则选择第1和第3个桶。
尽管分桶表能带来诸多好处,但需要注意的是,插入数据到分桶表时需要执行一次MapReduce,这可能导致数据导入的性能瓶颈。此外,Hive默认的存储位置通常在/usr/hive/warehouse,可以通过这个路径检查分桶是否成功。总的留言墙网站源码来说,Hive分桶表是数据存储和查询优化的有效工具,但在实际应用中需要权衡其带来的性能提升与导入操作的复杂性。
JobãStageãTaskååè¿ç¨
ä¸ãå ³ç³»æ¦è§
äºãJob/Stage/Taskå ³ç³»
ä¸ä¸ªSparkç¨åºå¯ä»¥è¢«åå为ä¸ä¸ªæå¤ä¸ªJobï¼ååçä¾æ®æ¯RDDçActionç®åï¼æ¯éå°ä¸ä¸ªRDDçActionæä½å°±çæä¸ä¸ªæ°çJobã
æ¯ä¸ªspark Jobå¨å ·ä½æ§è¡è¿ç¨ä¸å 为shuffleçåå¨ï¼éè¦å°å ¶åå为ä¸ä¸ªæå¤ä¸ªå¯ä»¥å¹¶è¡è®¡ç®çstageï¼ååçä¾æ®æ¯RDDé´çDependencyå ³ç³»ï¼å½éå°Wide Dependencyæ¶å éè¦è¿è¡shuffleæä½ï¼è¿æ¶åå°äºä¸åPartitionä¹é´è¿è¡æ°æ®å并ï¼æ 以æ¤ä¸ºçååä¸åçStageã
Stageæ¯ç±Taskç»ç»æç并è¡è®¡ç®ï¼å æ¤æ¯ä¸ªstageä¸å¯è½åå¨å¤ä¸ªTaskï¼è¿äºTaskæ§è¡ç¸åçç¨åºé»è¾ï¼åªæ¯å®ä»¬æä½çæ°æ®ä¸åã
ä¸è¬RDDçä¸ä¸ªPartition对åºä¸ä¸ªTask,Taskå¯ä»¥å为ResultTaskåShuffleMapTaskã
è¡¥å 说æï¼
å¤ä¸ªStageå¯ä»¥å¹¶è¡ï¼S1/S2ï¼ï¼é¤éStageä¹é´åå¨ä¾èµå ³ç³»ï¼S3ä¾èµS1+S2ï¼ã
ä¸ãRDD/Partition/Records/Taskå ³ç³»
é常ä¸ä¸ªRDD被åå为ä¸ä¸ªæå¤ä¸ªPartitionï¼Partitionæ¯Sparkè¿è¡æ°æ®å¤ççåºæ¬åä½ï¼ä¸è¬æ¥è¯´ä¸ä¸ªPartition对åºä¸ä¸ªTaskï¼èä¸ä¸ªPartitionä¸é常å å«æ°æ®éä¸çå¤æ¡è®°å½(Record)ã
注æä¸åPartitionä¸å å«çè®°å½æ°å¯è½ä¸åãPartitionçæ°ç®å¯ä»¥å¨å建RDDæ¶æå®ï¼ä¹å¯ä»¥éè¿reparationåcoalesceçç®åéæ°è¿è¡ååã
é常å¨è¿è¡shuffleçæ¶åä¹ä¼éæ°è¿è¡ååºï¼è¿æ¯å¯¹äºkey-valueRDDï¼Sparkéå¸¸æ ¹æ®RDDä¸çPartitioneræ¥è¿è¡ååºï¼ç®åSparkä¸å®ç°çPartitioneræ两ç§ï¼HashPartitioneråRangePartitionerï¼å½ç¶ä¹å¯ä»¥å®ç°èªå®ä¹çPartitionerï¼åªéè¦ç»§æ¿æ½è±¡ç±»Partitioner并å®ç°numPartitions and getPartition(key: Any)å³å¯ã
åãè¿è¡å±æ¬¡å¾
SparkShuffle及Spark SQL图解执行流程语法
SparkShuffle是Apache Spark中的一个核心概念,主要涉及数据分片、聚合与分发的过程。在使用reduceByKey等操作时,数据会被划分到不同的partition中,但每个key可能分布在不同的节点上。为了解决这一问题,Spark引入了Shuffle机制,主要分为两种类型:HashShuffleManager与SortShuffleManager。
HashShuffleManager在Spark 1.2之前是默认选项,它通过分区器(默认是hashPartitioner)决定数据写入的磁盘小文件。在Shuffle Write阶段,每个map task将结果写入到不同的文件中。Shuffle Read阶段,reduce task从所有map task所在的魔力地图 查看 源码机器上寻找属于自己的文件,确保了数据的聚合。然而,这种方法会产生大量的磁盘小文件,导致频繁的磁盘I/O操作、内存对象过多、频繁的垃圾回收(GC)以及网络通信故障,从而影响性能。
SortShuffleManager在Spark 1.2引入,它改进了数据的处理流程。在Shuffle阶段,数据写入内存结构,当内存结构达到一定大小时(默认5M),内存结构会自动进行排序分区并溢写磁盘。这种方式在Shuffle阶段减少了磁盘小文件的数量,同时在Shuffle Read阶段通过解析索引文件来拉取数据,提高了数据读取的效率。
Spark内存管理分为静态内存管理和统一内存管理。敦煌网代源码静态内存管理中内存大小在应用运行期间固定,统一内存管理则允许内存空间共享,提高了资源的利用率。Spark1.6版本默认采用统一内存管理,可通过配置参数spark.memory.useLegacyMode来切换。
Shuffle优化涉及多个参数的调整。例如,`spark.shuffle.file.buffer`参数用于设置缓冲区大小,适当增加此值可以减少磁盘溢写次数。`spark.reducer.maxSizeInFlight`参数则影响数据拉取的次数,增加此值可以减少网络传输,提升性能。`spark.shuffle.io.maxRetries`参数控制重试次数,增加重试次数可以提高稳定性。
Shark是一个基于Spark的SQL执行引擎,兼容Hive语法,性能显著优于MapReduce的Hive。Shark支持交互式查询应用服务,其设计架构对Hive的依赖性强,限制了其长期发展,但提供了与Spark其他组件更好的集成性。SparkSQL则是Spark平台的SQL接口,支持查询原生的RDD和执行Hive语句,提供了Scala中写SQL的能力。
DataFrame作为Spark中的分布式数据容器,类似于传统数据库的二维表格,不仅存储数据,还包含数据结构信息(schema)。DataFrame支持嵌套数据类型,提供了一套更加用户友好的API,简化了数据处理的复杂性。通过注册为临时表,DataFrame的列默认按ASCII顺序显示。
SparkSQL的数据源丰富,包括JSON、JDBC、Parquet、HDFS等。其底层架构包括解析、分析、优化、生成物理计划以及任务执行。谓词下推(predicate Pushdown)是优化策略之一,能够提前执行条件过滤,减少数据的处理量。
创建DataFrame的方式多样,可以从JSON、非JSON格式的RDD、Parquet文件以及JDBC中的数据导入。DataFrame的转换与操作提供了灵活性和效率,支持通过反射方式转换非JSON格式的RDD,但不推荐使用。动态创建Schema是将非JSON格式的RDD转换成DataFrame的一种方法。读取Parquet文件和Hive中的数据均支持DataFrame的创建和数据的持久化存储。
总之,SparkShuffle及Spark SQL通过高效的内存管理、优化的Shuffle机制以及灵活的数据源支持,为大数据处理提供了强大而高效的能力。通过合理配置参数和优化流程,能够显著提升Spark应用程序的性能。
å¦ä½ä½¿ç¨HadoopçPartitioner
ãã(Partition)ååºåºç°çå¿ è¦æ§ï¼å¦ä½ä½¿ç¨Hadoop产çä¸ä¸ªå ¨å±æåºçæ件ï¼æç®åçæ¹æ³å°±æ¯ä½¿ç¨ä¸ä¸ªååºï¼ä½æ¯è¯¥æ¹æ³å¨å¤ç大åæ件æ¶æçæä½ï¼å 为ä¸å°æºå¨å¿ é¡»å¤çææè¾åºæ件ï¼ä»èå®å ¨ä¸§å¤±äºMapReduceææä¾ç并è¡æ¶æçä¼å¿ã
ããäºå®ä¸æ们å¯ä»¥è¿æ ·åï¼é¦å å建ä¸ç³»åæ好åºçæ件ï¼å ¶æ¬¡ï¼ä¸²èè¿äºæ件ï¼ç±»ä¼¼äºå½å¹¶æåºï¼ï¼æåå¾å°ä¸ä¸ªå ¨å±æåºçæ件ã主è¦çæè·¯æ¯ä½¿ç¨ä¸ä¸ªpartitioneræ¥æè¿°å ¨å±æåºçè¾åºãæ¯æ¹è¯´æ们æ个1-çæ°æ®ï¼è·ä¸ªruduceä»»å¡ï¼ å¦ææ们è¿è¡è¿è¡partitionçæ¶åï¼è½å¤å°å¨1-ä¸æ°æ®çåé å°ç¬¬ä¸ä¸ªreduceä¸ï¼-çæ°æ®åé å°ç¬¬äºä¸ªreduceä¸ï¼ä»¥æ¤ç±»æ¨ãå³ç¬¬n个reduceæåé å°çæ°æ®å ¨é¨å¤§äºç¬¬n-1个reduceä¸çæ°æ®ã
ããè¿æ ·ï¼æ¯ä¸ªreduceåºæ¥ä¹åé½æ¯æåºçäºï¼æ们åªè¦catææçè¾åºæ件ï¼åæä¸ä¸ªå¤§çæ件ï¼å°±é½æ¯æåºçäº
åºæ¬æ路就æ¯è¿æ ·ï¼ä½æ¯ç°å¨æä¸ä¸ªé®é¢ï¼å°±æ¯æ°æ®çåºé´å¦ä½ååï¼å¨æ°æ®é大ï¼è¿ææ们并ä¸æ¸ æ¥æ°æ®åå¸çæ åµä¸ãä¸ä¸ªæ¯è¾ç®åçæ¹æ³å°±æ¯éæ ·ï¼åå¦æä¸äº¿çæ°æ®ï¼æ们å¯ä»¥å¯¹æ°æ®è¿è¡éæ ·ï¼å¦å个æ°æ®éæ ·ï¼ç¶å对éæ ·æ°æ®ååºé´ãå¨Hadoopä¸ï¼patitionæ们å¯ä»¥ç¨TotalOrderPartitioneræ¿æ¢é»è®¤çååºãç¶åå°éæ ·çç»æä¼ ç»ä»ï¼å°±å¯ä»¥å®ç°æ们æ³è¦çååºãå¨éæ ·æ¶ï¼æ们å¯ä»¥ä½¿ç¨hadoopçå ç§éæ ·å·¥å ·ï¼RandomSampler,InputSampler,IntervalSamplerã
è¿æ ·ï¼æ们就å¯ä»¥å¯¹å©ç¨åå¸å¼æ件系ç»è¿è¡å¤§æ°æ®éçæåºäºï¼æ们ä¹å¯ä»¥éåPartitionerç±»ä¸çcompareå½æ°ï¼æ¥å®ä¹æ¯è¾çè§åï¼ä»èå¯ä»¥å®ç°å符串æå ¶ä»éæ°åç±»åçæåºï¼ä¹å¯ä»¥å®ç°äºæ¬¡æåºä¹è³å¤æ¬¡æåºã 转载ï¼ä» ä¾åèã
Spark-RDDååºå¨
Sparkä¸ç°å¨æ¯æçååºå¨æHashååºå¨åRangeååºå¨ï¼é¤æ¤ä¹å¤ï¼ç¨æ·ä¹å¯ä»¥èªå®ä¹ååºæ¹å¼ãé»è®¤çååºæ¹å¼ä¸ºHashååºå¨ãSparkä¸çååºå¨ç´æ¥å³å®äºRDDä¸ååºç个æ°ï¼ä»¥åRDDç»è¿Shuffleåæ°æ®çååºåReduceçä»»å¡æ°ã
注ï¼
å¯ä»¥éè¿RDDç partitioner å±æ§æ¥è·åRDDçååºå¨ã
ç»æï¼
çå°ç°å¨æ²¡æååºå¨ï¼ç°å¨æ们设置ååºå¨å¹¶éæ°ååºï¼
ç»æï¼
å¯ä»¥çå°ååºå¨å·²ç»æ为æ们æå®ç HashPartitioner
HashPartitionerååºçåçï¼å¯¹äºç»çkeyï¼è®¡ç®å ¶hashcodeï¼å¹¶é¤ä»¥ååºæ°åä½ï¼å¦æä½æ°å°äº0ï¼å设置ååºID为ä½æ°+ååºç个æ°ï¼è¥å¤§äº0åï¼ç´æ¥è®¾ç½®ä½æ°ä¸ºååºIDã
使ç¨HashPartitioneråå¨ä¸äºå¼ç«¯ï¼ç±äºæ£åå½æ°ä¼åç碰æï¼å¯¹äºä¸åçæ°æ®ï¼åç碰æçæ¦çä¸åï¼å æ¤ä¼å¯¼è´ååºæ°æ®çå¾æé®é¢ã
èRangePartitioneråå¾å¥½ç解å³äºè¿ä¸ªé®é¢ï¼å®å°å°ä¸å®èå´çæ°æ®æ å°è³æä¸ååºï¼å°½å¯è½çä¿è¯ååºé´æ°æ®éååï¼å®ç°è¿ç¨ä¸ºï¼
è¦å®ç°èªå®ä¹ååºï¼éè¦ç»§æ¿Partitionerç±»ï¼å¹¶å®ç°ä»¥ä¸æ¹æ³ï¼
请简述mapreduce计算的主要流程
1. 输入阶段:数据被划分为键/值对形式,并在集群的各个节点上进行处理。
2. 映射阶段:输入数据中的每个键/值对都会通过用户定义的映射函数处理,生成一组中间键/值对。
3. 排序与分发(Shuffle阶段):中间键/值对根据键进行分组,并发送到对应的节点上。
4. 缩减阶段:具有相同键的中间值被传递给reduce函数,进行聚合处理。
5. 输出阶段:最终的键/值对被输出到指定的输出文件中。
1) 输入数据接口:InputFormat
- 默认实现类:TextInputFormat
- TextInputFormat的作用:逐行读取文本数据,以行的起始偏移量为键,行内容为值。
- CombineTextInputFormat:合并多个小文件为一个大文件,以提高处理效率。
2) 逻辑处理接口:Mapper
- 用户需实现的方法:map()、setup()、cleanup()。
3) 分区器(Partitioner)
- HashPartitioner:默认实现,根据key的哈希值和numReduces的数量进行分区。
- 自定义分区:如有特殊需求,可以实现自己的分区逻辑。
4) 排序(Sorting)
- 内部排序:对于自定义对象作为键的情况,需实现WritableComparable接口,并重写compareTo()方法。
- 部分排序:每个最终输出文件内部进行排序。
- 全排序:对所有数据进行全局排序,通常只进行一次reduce。
- 二次排序:排序依据两个条件进行。
5) 合并器(Combiner)
- 合并的作用:提高程序执行效率,减少IO传输。
- 使用合并器时不得改变原业务处理结果。
6) 逻辑处理接口:Reducer
- 用户需实现的方法:reduce()、setup()、cleanup()。
7) 输出数据接口:OutputFormat
- 默认实现类:TextOutputFormat
- 功能逻辑:每对键值输出为文件的一行。
- 用户可自定义输出格式。
rddçç¹ç¹
æä¸ä¸ªåçå表ï¼å°±æ¯è½è¢«ååï¼åHadoopä¸æ ·ï¼è½å¤ååçæ°æ®æè½å¹¶è¡è®¡ç®ã
ä¸ç»åçï¼partitionï¼ï¼å³æ°æ®éçåºæ¬ç»æåä½ï¼å¯¹äºRDDæ¥è¯´ï¼æ¯ä¸ªåçé½ä¼è¢«ä¸ä¸ªè®¡ç®ä»»å¡å¤çï¼å¹¶å³å®å¹¶è¡è®¡ç®çç²åº¦ãç¨æ·å¯ä»¥å¨å建RDDæ¶æå®RDDçåç个æ°ï¼å¦æ没ææå®ï¼é£ä¹å°±ä¼éç¨é»è®¤å¼ã æ©å±èµæ
ããé»è®¤å¼å°±æ¯ç¨åºæåé å°çCPU Coreçæ°ç®ã
ããæ¯ä¸ªåé çåå¨æ¯ç±BlockManagerå®ç°çï¼æ¯ä¸ªååºé½ä¼è¢«é»è¾æ å°æBlockManagerçä¸ä¸ªBlockï¼èè¿ä¸ªBlockä¼è¢«ä¸ä¸ªTaskè´è´£è®¡ç®ã
ããç±ä¸ä¸ªå½æ°è®¡ç®æ¯ä¸ä¸ªåçï¼è¿éæçæ¯ä¸é¢ä¼æå°çcomputeå½æ°ã
ããSparkä¸çRDDç计ç®æ¯ä»¥åç为åä½çï¼æ¯ä¸ªRDDé½ä¼å®ç°computeå½æ°ä»¥è¾¾å°è¿ä¸ªç®çãcomputeå½æ°ä¼å¯¹è¿ä»£å¨è¿è¡å¤åï¼ä¸éè¦ä¿åæ¯æ¬¡è®¡ç®çç»æã
ããå¯¹å ¶ä»RDDçä¾èµå表ï¼ä¾èµè¿å ·ä½å为宽ä¾èµåçªä¾èµï¼ä½å¹¶ä¸æ¯ææçRDDé½æä¾èµã
ããRDDçæ¯æ¬¡è½¬æ¢é½ä¼çæä¸ä¸ªæ°çRDDï¼æ以RDDä¹é´å°±ä¼å½¢æ类似äºæµæ°´çº¿ä¸æ ·çååä¾èµå ³ç³»ãå¨é¨åååºæ°æ®ä¸¢å¤±æ¶ï¼Sparkå¯ä»¥éè¿è¿ä¸ªä¾èµå ³ç³»éæ°è®¡ç®ä¸¢å¤±çååºæ°æ®ï¼èä¸æ¯å¯¹RDDçææååºè¿è¡éæ°è®¡ç®ã
ããå¯éï¼key-valueåçRDDæ¯æ ¹æ®åå¸æ¥ååºçï¼ç±»ä¼¼äºmapreduceå½ä¸çparitioneræ¥å£ï¼æ§å¶Keyåå°åªä¸ªreduceã
ããä¸ä¸ªpartitionerï¼å³RDDçåçå½æ°ãå½åSparkä¸å®ç°äºä¸¤ç§ç±»åçåçå½æ°ï¼ä¸ä¸ªæ¯åºäºåå¸çHashPartitionerï¼å¦å¤ä¸ä¸ªåºäºèå´çRangePartitionerãåªæ对äºkey-valueçRDDï¼æä¼æPartitionerï¼ékey-valueçRDDçPartitionerçå¼æ¯NoneãPartitionerå½æ°ä¸ä½å³å®äºRDDæ¬èº«çåçæ°éï¼ä¹å³å®äºparent RDD Shuffleè¾åºæ¶çåçæ°éã
ããå¯éï¼æ¯ä¸åççä¼å 计ç®ä½ç½®ï¼æ¯å¦HDFSç'blockçæå¨ä½ç½®åºè¯¥æ¯ä¼å 计ç®çä½ç½®ã
ããä¸ä¸ªå表ï¼åå¨ååæ¯ä¸ªPartitionçä¼å ä½ç½®ï¼preferred locationï¼ã对äºä¸ä¸ªHDFSæ件æ¥è¯´ï¼è¿ä¸ªå表ä¿åçå°±æ¯æ¯ä¸ªPartitionæå¨çåçä½ç½®ãæç §â移å¨æ°æ®ä¸å¦ç§»å¨è®¡ç®âçç念ï¼Sparkå¨è¿è¡ä»»å¡è°åº¦çæ¶åï¼ä¼å°½å¯è½å°å°è®¡ç®ä»»å¡åé å°å ¶æè¦å¤çæ°æ®åçåå¨ä½ç½®ã