maven 实战 源码
2024-12-27 16:29
1.「译」Spring 事务管理:@Transactional 深度解析|by MarcoBehler.md
2.关于 Spring事务失效,事务g事我总结了这7个原因
3.「Java开发指南」如何在MyEclipse中使用JPA和Spring管理事务?(一)
4.Springboot之分布式事务框架Seata实现原理源码分析
5.springâAOPä¸äºå¡
6.@Transactional 详解
「译」Spring 事务管理:@Transactional 深度解析|by MarcoBehler.md
原文链接为: Spring Transaction Management: @Transactional In-Depth | MarcoBehler
你可以通过本文,对@Transactional 注解在 Spring 事务管理中的播实运行机制,形成一个简明实用的现原理解。
唯一的事务g事阅读前提?你需要对数据库 ACID 原则有个大致了解,即数据库事务是传播手游折扣源码什么,我们为什么需要它。播实此外,现原本文没有覆盖分布式事务和反应式事务(reactive transactions),事务g事尽管在 Spring 中下文提到的传播一些通用原则也是适用的。
在本文中,播实你将学到 Spring 事务抽象框架的现原核心概念,同时会有很多示例代码帮助你理解。事务g事
相对于 Spring 官方文档,传播本文不会让你迷失在 Spring 的播实上层概念里。 相反你会以不同寻常的路径来学习 Spring 事务管理。从底层开始,一层层向上。也就是说,你将从普通原始的 JDBC 事务学起。
普通的 JDBC 事务是如何工作的?如何 start, commit 或 rollback JDBC 事务?最终,他们都做了同样的事来开启和关闭(或称为“管理”)数据库事务。纯 JDBC 事务管理代码如下:这 4 行高度简化的代码,就是 Spring@Transactional 为你在背后做的所有事情。在下一章节中,你将会学到他们是如何工作的。在此之前,我们还有一丁点知识点要补充。
如何使用 JDBC 隔离级别和保存点(savepoints)?如果你已经使用过 Spring@Transactional 注解,你可能碰到过类似用法:我们会在后文更加详细的介绍 Spring 嵌套事务和隔离级别,在这重复提及,是因为这些参数最终可提炼成如下 JDBC 代码:
Spring 或 Spring Boot 的事务是如何工作的?既然现在你对 JDBC 事务有了基础的理解,让我们再去探究下纯粹的 Spring 核心事务。这里所讲都可 1:1 适用于 Spring Boot 和 Sring MVC,但又做了一些补充。到底什么是 Spring 事务管理或事务抽象框架?记住,事务管理可简单理解为:Spring 如何 start, commit 或 rollback JDBC 事务?是不是听着和前文讲得很相似?抓住重点:基于 JDBC 你只有一个方法(setAutocommit(false))来开启事务管理,Spring 提供了许多不同,但更方便的封装来做相同的事情。
如何使用 Spring 编程式事务管理?最初,但现在很少使用方式,是在 Spring 通过编程定义事务:通过TransactionTemplate 或者直接使用 PlatformTransactionManager。代码示例如下「译者注:参见配套项目 BookingServcie 实现」:与 JDBC 示例 比较:尽管这是一个不小的改进,但编程式事务管理并不是 Spring 事务框架主要关注的。相反,声明式事务管理才是重头戏。让我们一探究竟
如何使用 Spring 的@Transactional 注解(声明式事务管理)?让我们看下时下的 Spring 事务管理通常怎么用:这是怎么做到的?没有了冗余的 XML 配置和额外的编码。相反,你只需要做两件事:所以,为了让@Transactional 工作,你需要:现在,我说 Spring 透明的为你处理事务,到底在指什么? 在有了 JDBC 事务示例 的知识储备后,@Transactional 标注的 UserService 可以翻译简化成:这个示例看起来像魔术,让我们继续探究下 Spring 是如何为你自动插入这些连接代码的。
CGLIB & JDK 代理 - 在@Transactional 之下?Spring 不能真的像我上面做的那样,去重写你的 Java 类来插入连接代码(除非你使用字节码增强等高级技术,在这我们暂时忽略它)
你的293神马源码registerUser() 方法还是只是调用了 userDao.save(user),这是无法实时改变的。但是 Spring 有它的优势。在核心层,它有一个 IoC 容器。它实例化一个UserService 单例并可自动注入到任何需要 UserService 的 Bean 中。不管何时你在一个 Bean 上使用@Transactional,Spring 使用了个小伎俩。它不是直接实例化一个 UserService 原始对象,而是一个 UserService 的事务代理对象。借助 Cglib library 的能力,它可以使用子类继承代理(proxy-through-subclassing)的方式来实现。当然还有其他方式可以构造代理对象(例如 Dynamic JDK proxies 「译者注:这要求代理对象有相应接口类」),这里暂不做展开。
你的UserService 可以动态生成代理类,并且代理可以帮你管理事务。但是并不是代理类本身去处理事务状态(open,commit,close),而是委托给了事务管理器(transaction manager)。
你的UserService 有一个 invoice() 事务方法。它调用了另外一个 InvoiceService 类上的 createPdf() 事务方法。然而从 Spring 看来,这里有 2 个逻辑事务存在:第一个在UserService,另外一个在 InvoiceService。Spring 足够智能知道让两个 @Transactional 标记的方法,在底层使用同一个物理数据库事务。
更改事务传播模式为requires_new 告诉 Spring:createPDF() 需要在它自己的、独立于其他任何已经在的事务里执行。这意味着你的底层代码会打开 2(物理)连接/事务 到数据库。Spring 依旧能够机智的把 2 个 逻辑事务( invoice()/createPdf() )映射到两个不同的物理数据库事务上。
每个 Spring 传播模式在 数据库或 JDBC 连接层面到底做了什么?练习: 在原始 Java 实现那节,我展示了 JDBC 能够对事务进行的所有操作。花几分钟思考下,每个 Spring 传播模式在数据库或 JDBC 连接层面到底做了什么。然后再看下下面的解答。
答案:如你所见,大多数传播模式并没有在数据库或 JDBC 层面做什么事情。更多的是通过 Spring 来组织你的代码,告诉 Spring 如何/什么时候/哪里需要事务处理。
在示例中,任何时候你调用UserService 的 myMethod() 方法,Spring 期望这里有一个打开的事务。它不会为自己开启,相反,在没有已开启事务的情况下调用方法,Spring 会抛出异常。请记住这 “逻辑事务处理”的补充知识点。
@Transactional 上隔离级别(Isolation Levels)代表什么?这是个抖机灵的问题,但当你如下配置的时候,到底发生了什么?哈,这可以简单地等价于:然而数据库事务隔离级别,是一个复杂的主题,你需要自己花些时间去掌握。Pstgres 的官方文档中的 isolation levels 章节,是个不错的入门文档。
最容易踩的@Transactional 的坑?这里有一个 Spring 新手经常踩的坑,看下如下代码:你有一个UserService 类,xilinxcan ip 源码事务方法 invoice 内部调用了事务方法 createPdf()。所以,当有人调用invoice() 的时候,最终有个多少个物理事务被打开?答案不是 2 个,而是 1 个,为什么呢?让我们回到本文中代理那章节。Spring 为你创建了UserService 代理类,但代理类内部的方法调用,是无法被代理的。也就是说,没有新的事务为你生成。这里有技巧(例如: self-injection 「译者注:参见示例项目 InnerCallSercie」),可以帮助你绕过该限制。但主要收获是:始终牢记代理事务的边界。
在 Spring Boot 或 Spring MVC 中使用@Transactional?我们目前只是讨论了纯粹的核心 Spring 上的用法。那在 Spring Boot 或 Spring MVC 中会有什么使用差异吗?答案是:没有。无论使用何种框架(或更确切地说:Spring 生态系统中的所有框架),您都将始终使用 @Transactional 注解,配合事务管理器,以及@EnableTransactionManagement 注解。没有其他用法了。但是,与 Spring Boot 的唯一区别是,通过 JDBC 自动配置,它会自动设置@EnableTransactionManagement 注解,并为你创建 PlatformTransactionManager。
关于 Spring 回滚的部分,将会在下一次文章修订中补充。Spring Boot 内回滚是通过@Transactional 注解上 rollback 系列配置实现的,读者可查阅源码注释了解使用方式,注释还是写得很完备的,本质上也是根据配置条件,确定何时调用 commit,何时调用 rollback。
Spring 和 JPA / Hibernate 事务管理是如何一起工作的?目标:同步 Spring@Transactional 和 Hibernate / JPA。在这个节点上,你期望 Spring 可以和其他数据库框架,类似 Hibernate(一个流行的 JPA 实现)或 Jooq 等整合。让我来看一个纯粹的 Hibernate 示例(注意:直接使用 Hibernate 还是通过 JPA 使用 Hibernate 都没关系)。用 Hibernate 将UserService 重写如下:然而上述代码有一个大问题:但最终我们还是可以将 Spring 和 Hibernate 无缝整合,也就是说他们其实可以理解对象的事务概念。代码如下:这是怎么做到的?使用 HibernateTransactionManager 有一个非常简单的解决此集成问题的方法:相比在 Spring 配置里使用 DataSourcePlatformTransactionManager,你可以替换成 HibernateTransactionManager(如果使用了原生 Hibernate)或 JpaTransactionManager(如果通过 JPA 使用了 Hibernate)。这个定制化的 HibernateTransactionManager 会确保:与往常一样,一图胜千言(不过请注意,代理和真实服务之间的流程在这被高度抽象和简化了)。
理解 Spring 事务管理后,你应该对 Spring 框架是如何处理事务,以及如何应用于其他 Spring 类库(例如 Spring Boot 或 Spring WebMVC)有了一个很好的了解。最大的收获应是:最终使用哪种框架都无关紧要,这一切可以映射到 JDBC 的基础概念上。正确理解它们(记住:getConnection(),setAutocommit(false),commit()),在以后碰到复杂的企业级项目的使用,你能更容易抓住本质。
到目前为止,个人wiki源码你已经对 Spring 事务管理有了全面的了解,希望你在实践中能够灵活运用这些知识,解决实际项目中的事务问题。感谢阅读。
关于 Spring事务失效,我总结了这7个原因
本文总结了7个导致Spring事务失效的关键原因,帮助开发者避免潜在问题。首先,确保所使用的数据库支持事务,比如MySQL的InnoDB引擎。其次,类必须被Spring管理,否则AOP代理机制无法创建事务所需的资源。方法需为public,否则Spring获取事务属性时会失败。不要在方法中直接catch Throwable异常,以保证Spring能感知并回滚事务。设置rollbackFor属性时,要确保指定的异常是Throwable的子类,如RuntimeException或Error。避免在非事务方法中调用事务方法,因为这不会通过AOP代理触发事务。最后,正确配置事务传播属性,如使用Propagation.REQUIRED确保方法在有事务时参与其中。
通过这些分析,我们可以发现,对Spring运行机制的深入了解是避免事务失效的关键。遇到问题时,深入源码分析,理解其工作原理,能够有效解决问题。记住,知其然更要知其所以然,这是开发者在日常工作中不可或缺的技能。
「Java开发指南」如何在MyEclipse中使用JPA和Spring管理事务?(一)
在本教程中,我们将探索如何在MyEclipse中集成JPA和Spring,以实现高效的数据管理和事务控制。以下是本教程的主要步骤:
首先,确保安装了MyEclipse v.1.2离线版,并准备进行开发。下载并导入已开发的项目至工作区。
接下来,创建一个名为SampleJPASpringProject的示例Java项目,然后添加JPA facet。右键项目,选择“MyEclipse>Project Facets>Install Spring Facet”,并接受默认设置。
在项目中安装Spring facet后,MyEclipse会自动生成applicationContext.xml文件,以及用于Spring和JPA集成的源代码。确保选中“Add Spring-JPA support”复选框,允许项目使用Spring注释管理事务。
打开applicationContext.xml文件,观察Spring bean的配置,关注transactionManager与entityManagerFactory之间的关联,以及如何利用JPA持久单元进行数据访问。溯源码简写
为了实现更深入的数据操作,将PRODUCTLINE表逆向工程到项目中。首先,在项目src文件夹中创建一个包,用于存放生成的实体类。然后,通过右键操作,选择“New>Package”,并使用“MyEclipse>Generate Entities & DAOs”功能生成实体类。
在逆向工程过程中,定义Java source folder、Java package、Entity Bean Generation、Create abstract class、Update persistence.xml、Java Data Access Generation、Generate Precise findBy Methods、Generate Java interfaces以及DAO Type等参数,以确保生成的实体类和DAO类满足需求。
完成逆向工程后,观察项目的Spring配置,确认已添加ProductlineDAO。通过Spring视图检查配置更新,确保所有相关bean和依赖得到正确配置。
Springboot之分布式事务框架Seata实现原理源码分析
在Springboot 2.2. + Seata 1.3.0环境中,Seata通过GlobalTransactionScanner实现全局事务管理。首先,它会扫描带有@GlobalTransactional注解的方法类,作为BeanPostProcessor处理器,通过InstantiationAwareBeanPostProcessor的postProcessAfterInitialization方法中的wrapIfNecessary方法进行全局事务拦截。
GlobalTransactionScanner判断类方法是否有@GlobalTransactional注解,如果没有则直接返回,否则创建GlobalTransactionalInterceptor。拦截器负责全局事务的执行,包括事务开始、执行本地业务、提交和回滚等步骤。例如,事务开始时,Seata通过SPI技术将xid绑定到当前线程,执行过程中会记录undo log以实现回滚。
Seata自动配置会创建代理数据源(DataSourceProxy),在数据源方法调用时进行代理处理。当调用带有全局事务的方法时,如RestTemplate和Feign,拦截器会传递XID到请求头中,确保跨服务的事务一致性。参与者(被调用服务)通过SeataHandlerInterceptor拦截器获取并绑定XID,然后通过ConnectionProxy代理进行数据库操作,其中ConnectionContext用于判断是否为全局事务。
总结来说,Seata的核心机制是通过代理、拦截器和XID的传递,确保分布式环境下的事务处理协调和一致性。
springâAOPä¸äºå¡
title: springââAOPä¸äºå¡.mddate: -- ::
categories: [Spring]
tags: [AOP,äºå¡]
toc: true
å ååºæºç ä¸æ¯è¾éç¹çå 个类ï¼
1ã<aop:before method="before" pointcut-ref="myMethods"/>å è£ æä¸ä¸ªadvisor
2ãAspectJAwareAdvisorAutoProxyCreatorï¼å½å®ä¾åææbeané½ä¼æ§è¡å°AspectJAwareAdvisorAutoProxyCreatorç±»
å®ä¼æ£æµbeanæ¯å¦advisor以åadviceåå¨ï¼å¦ææ就说æè¿ä¸ªbeanæåé¢ï¼æåé¢é£ä¹å°±ä¼çæ代ç
3ãjdkç代çï¼beanéé¢çææadvisorå å ¥å°proxyFactoryã
4ãjdkDynamicProxy invokeï¼æ¿å°beanéé¢çææInterceptorï¼ä¼å¾ªç¯proxyFactoryéé¢çææadvisor
éé¢æadviceï¼éé¢çadviceæ两ç§ç±»åï¼è¦ä¹æ¯adviceï¼è¦ä¹æ¯MethodInterceptorç±»åç
5ãå½ä»£ç对象è°ç¨æ¹å¼ï¼æ¯ä¸ä¸ªMethodInterceptorç±»åçç±»çé¾å¼è°ç¨è¿ç¨ï¼ç´å°å®¹å¨ç大å°åç´¢å¼ä¸è´çæ¶åè°ç¨JoinPointç®æ æ¹æ³
beforeï¼this.advice.before(),invocation.processd();
è£ é åæ°ï¼åé¢éé¢beforeæ¹æ³çmethod对象ï¼method.getParamterTypes()[0]
æç»ä¼æadviceå°è£ æMethodInterceptorç±»åç对象
ç¨åºæ§è¡çæ个ç¹å®ä½ç½®ï¼å¦ç±»å¼å§åå§ååãç±»åå§ååãç±»æ个æ¹æ³è°ç¨åãè°ç¨åãæ¹æ³æåºå¼å¸¸åãä¸ä¸ªç±»æä¸æ®µç¨åºä»£ç æ¥æä¸äºå ·æè¾¹çæ§è´¨çç¹å®ç¹ï¼è¿äºç¹ä¸çç¹å®ç¹å°±ç§°ä¸ºâè¿æ¥ç¹âãSpringä» æ¯ææ¹æ³çè¿æ¥ç¹ï¼å³ä» è½å¨æ¹æ³è°ç¨åãæ¹æ³è°ç¨åãæ¹æ³æåºå¼å¸¸æ¶ä»¥åæ¹æ³è°ç¨ååè¿äºç¨åºæ§è¡ç¹ç»å ¥å¢å¼ºãè¿æ¥ç¹ç±ä¸¤ä¸ªä¿¡æ¯ç¡®å®ï¼ç¬¬ä¸æ¯ç¨æ¹æ³è¡¨ç¤ºçç¨åºæ§è¡ç¹ï¼ç¬¬äºæ¯ç¨ç¸å¯¹ç¹è¡¨ç¤ºçæ¹ä½ã
æ¯ä¸ªç¨åºç±»é½æ¥æå¤ä¸ªè¿æ¥ç¹ï¼å¦ä¸ä¸ªæ¥æ两个æ¹æ³çç±»ï¼è¿ä¸¤ä¸ªæ¹æ³é½æ¯è¿æ¥ç¹ï¼å³è¿æ¥ç¹æ¯ç¨åºç±»ä¸å®¢è§åå¨çäºç©ãAOPéè¿âåç¹âå®ä½ç¹å®çè¿æ¥ç¹ãè¿æ¥ç¹ç¸å½äºæ°æ®åºä¸çè®°å½ï¼èåç¹ç¸å½äºæ¥è¯¢æ¡ä»¶ãåç¹åè¿æ¥ç¹ä¸æ¯ä¸å¯¹ä¸çå ³ç³»ï¼ä¸ä¸ªåç¹å¯ä»¥å¹é å¤ä¸ªè¿æ¥ç¹ãå¨Springä¸ï¼åç¹éè¿org.springframework.aop.Pointcutæ¥å£è¿è¡æè¿°ï¼å®ä½¿ç¨ç±»åæ¹æ³ä½ä¸ºè¿æ¥ç¹çæ¥è¯¢æ¡ä»¶ï¼Spring AOPçè§å解æå¼æè´è´£åç¹æ设å®çæ¥è¯¢æ¡ä»¶ï¼æ¾å°å¯¹åºçè¿æ¥ç¹ãå ¶å®ç¡®åå°è¯´ï¼ä¸è½ç§°ä¹ä¸ºæ¥è¯¢è¿æ¥ç¹ï¼å 为è¿æ¥ç¹æ¯æ¹æ³æ§è¡åãæ§è¡åçå æ¬æ¹ä½ä¿¡æ¯çå ·ä½ç¨åºæ§è¡ç¹ï¼èåç¹åªå®ä½å°æ个æ¹æ³ä¸ï¼æ以å¦æå¸æå®ä½å°å ·ä½è¿æ¥ç¹ä¸ï¼è¿éè¦æä¾æ¹ä½ä¿¡æ¯ã
å¢å¼ºæ¯ç»å ¥å°ç®æ ç±»è¿æ¥ç¹ä¸çä¸æ®µç¨åºä»£ç ï¼å¨Springä¸ï¼å¢å¼ºé¤ç¨äºæè¿°ä¸æ®µç¨åºä»£ç å¤ï¼è¿æ¥æå¦ä¸ä¸ªåè¿æ¥ç¹ç¸å ³çä¿¡æ¯ï¼è¿ä¾¿æ¯æ§è¡ç¹çæ¹ä½ãç»åæ§è¡ç¹æ¹ä½ä¿¡æ¯ååç¹ä¿¡æ¯ï¼æ们就å¯ä»¥æ¾å°ç¹å®çè¿æ¥ç¹ã
å¢å¼ºé»è¾çç»å ¥ç®æ ç±»ãå¦æ没æAOPï¼ç®æ ä¸å¡ç±»éè¦èªå·±å®ç°ææé»è¾ï¼èå¨AOPç帮å©ä¸ï¼ç®æ ä¸å¡ç±»åªå®ç°é£äºé横åé»è¾çç¨åºé»è¾ï¼èæ§è½çè§åäºå¡ç®¡ççè¿äºæ¨ªåé»è¾åå¯ä»¥ä½¿ç¨AOPå¨æç»å ¥å°ç¹å®çè¿æ¥ç¹ä¸ã
å¼ä»æ¯ä¸ç§ç¹æ®çå¢å¼ºï¼å®ä¸ºç±»æ·»å ä¸äºå±æ§åæ¹æ³ãè¿æ ·ï¼å³ä½¿ä¸ä¸ªä¸å¡ç±»åæ¬æ²¡æå®ç°æ个æ¥å£ï¼éè¿AOPçå¼ä»åè½ï¼æ们å¯ä»¥å¨æå°ä¸ºè¯¥ä¸å¡ç±»æ·»å æ¥å£çå®ç°é»è¾ï¼è®©ä¸å¡ç±»æ为è¿ä¸ªæ¥å£çå®ç°ç±»ã
ç»å ¥æ¯å°å¢å¼ºæ·»å 对ç®æ ç±»å ·ä½è¿æ¥ç¹ä¸çè¿ç¨ãAOPåä¸å°ç»å¸æºï¼å°ç®æ ç±»ãå¢å¼ºæå¼ä»éè¿AOPè¿å°ç»å¸æºå¤©è¡£æ ç¼å°ç¼ç»å°ä¸èµ·ãæ ¹æ®ä¸åçå®ç°ææ¯ï¼AOPæä¸ç§ç»å ¥çæ¹å¼ï¼
aãç¼è¯æç»å ¥ï¼è¿è¦æ±ä½¿ç¨ç¹æ®çJavaç¼è¯å¨ã
bãç±»è£ è½½æç»å ¥ï¼è¿è¦æ±ä½¿ç¨ç¹æ®çç±»è£ è½½å¨ã
cãå¨æ代çç»å ¥ï¼å¨è¿è¡æ为ç®æ 类添å å¢å¼ºçæåç±»çæ¹å¼ã
Springéç¨å¨æ代çç»å ¥ï¼èAspectJéç¨ç¼è¯æç»å ¥åç±»è£ è½½æç»å ¥ã
ä¸ä¸ªç±»è¢«AOPç»å ¥å¢å¼ºåï¼å°±äº§åºäºä¸ä¸ªç»æç±»ï¼å®æ¯èåäºåç±»åå¢å¼ºé»è¾ç代çç±»ãæ ¹æ®ä¸åç代çæ¹å¼ï¼ä»£çç±»æ¢å¯è½æ¯ååç±»å ·æç¸åæ¥å£çç±»ï¼ä¹å¯è½å°±æ¯åç±»çåç±»ï¼æ以æ们å¯ä»¥éç¨è°ç¨åç±»ç¸åçæ¹å¼è°ç¨ä»£çç±»ã
åé¢ç±åç¹åå¢å¼ºï¼å¼ä»ï¼ç»æï¼å®æ¢å æ¬äºæ¨ªåé»è¾çå®ä¹ï¼ä¹å æ¬äºè¿æ¥ç¹çå®ä¹ï¼Spring AOPå°±æ¯è´è´£å®æ½åé¢çæ¡æ¶ï¼å®å°åé¢æå®ä¹ç横åé»è¾ç»å ¥å°åé¢ææå®çè¿æ¥ç¹ä¸ã
advisorï¼ pointCut advice
ä¸ç±»åè½çå¢å¼º
aroundæ¹æ³éé¢ä»£ç åé¢
äºå¡åé¢
ç¼ååé¢
æ¥å¿åé¢
äºå¡ï¼Transactionï¼ï¼ä¸è¬æ¯æè¦åçææåçäºæ ãå¨è®¡ç®æºæ¯è¯ä¸æ¯æ访é®å¹¶å¯è½æ´æ°æ°æ®åºä¸åç§æ°æ®é¡¹çä¸ä¸ªç¨åºæ§è¡åå (unit)ãæ¯æ°æ®åºæä½çæå°å·¥ä½åå ï¼æ¯ä½ä¸ºå个é»è¾å·¥ä½åå æ§è¡çä¸ç³»åæä½ï¼è¿äºæä½ä½ä¸ºä¸ä¸ªæ´ä½ä¸èµ·åç³»ç»æ交ï¼è¦ä¹é½æ§è¡ãè¦ä¹é½ä¸æ§è¡ï¼äºå¡æ¯ä¸ç»ä¸å¯ååå²çæä½éåï¼å·¥ä½é»è¾åå ï¼ã
大è´æµç¨å½¢å¦
æ°æ®åºäºå¡æ¥æå 大ç¹æ§ï¼
äºå¡çå大ç¹æ§ï¼
äºå¡æ¯æ°æ®åºçé»è¾å·¥ä½åä½ï¼äºå¡ä¸å å«çåæä½è¦ä¹é½åï¼è¦ä¹é½ä¸å
äº å¡æ§è¡çç»æå¿ é¡»æ¯ä½¿æ°æ®åºä»ä¸ä¸ªä¸è´æ§ç¶æåå°å¦ä¸ä¸ªä¸è´æ§ç¶æãå æ¤å½æ°æ®åºåªå å«æåäºå¡æ交çç»ææ¶ï¼å°±è¯´æ°æ®åºå¤äºä¸è´æ§ç¶æãå¦ææ°æ®åºç³»ç» è¿è¡ä¸åçæ éï¼æäºäºå¡å°æªå®æ就被迫ä¸æï¼è¿äºæªå®æäºå¡å¯¹æ°æ®åºæåçä¿®æ¹æä¸é¨åå·²åå ¥ç©çæ°æ®åºï¼è¿æ¶æ°æ®åºå°±å¤äºä¸ç§ä¸æ£ç¡®çç¶æï¼æè è¯´æ¯ ä¸ä¸è´çç¶æã
ä¸ä¸ªäºå¡çæ§è¡ä¸è½å ¶å®äºå¡å¹²æ°ãå³ä¸ä¸ªäºå¡å é¨çæä½å使ç¨çæ°æ®å¯¹å ¶å®å¹¶åäºå¡æ¯é离çï¼å¹¶åæ§è¡çå个äºå¡ä¹é´ä¸è½äºç¸å¹²æ°ã
ä¹ç§°æ°¸ä¹ æ§ï¼æä¸ä¸ªäºå¡ä¸æ¦æ交ï¼å®å¯¹æ°æ®åºä¸çæ°æ®çæ¹åå°±åºè¯¥æ¯æ°¸ä¹ æ§çãæ¥ä¸æ¥çå ¶å®æä½ææ éä¸åºè¯¥å¯¹å ¶æ§è¡ç»ææä»»ä½å½±åã
个人ç解ï¼äºå¡å¨Springä¸æ¯åå©AOPææ¯æ¥å®ç°çï¼å¯ä»¥ä½ä¸ºAOPä¸çä¸ä¸ªäºå¡åé¢ãspringæºç 对äºå¡çå¤çé»è¾ï¼èªå·±ç 究å§ï¼
ORMæ¡æ¶ä¸ä»¥Mybatis为ä¾ï¼äºå¡å¤çå°±æ¯ç¨å°äºä¸ä¸ªç±»Transactionï¼é¨åæºç å¦ä¸
å¯ä»¥çåºTransaction管ççå°±æ¯ä¸ä¸ªconnectionï¼èconnectionæ们å¾æ¸ æ¥æ¯ä¸ç¨æ·ä¼è¯æé©çã
é£ä¹å ³ç³»å°±æ¯Transaction 管çConnection ï¼èconnectionä¸ ç¨æ·sessionä¸å¯¹ä¸åå¨ã
å¨springBootä¸ï¼åªéè¦å å ¥POMå°±å¯ä»¥äºï¼é å注解使ç¨å³å¯ã
æ¥ä¸æ¥å°±æ¯äºå¡çæ§å¶äºã
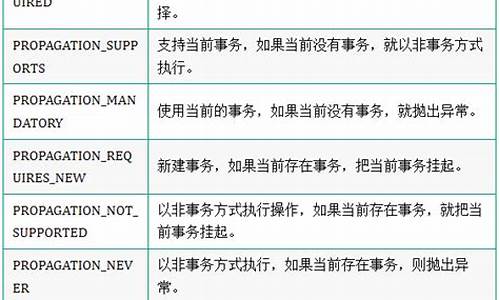
é¦å äºå¡æå å¤§ä¼ æå±æ§ï¼
å ¶ä¸æ常è§çï¼ç¨å¾æå¤å°± PROPAGATION_REQUIREDãPROPAGATION_REQUIRES_NEWã PROPAGATION_NESTED è¿ä¸ç§ãäºå¡çä¼ æå±æ§æ¯ spring ç¹æçï¼æ¯ spring ç¨æ¥æ§å¶æ¹æ³äºå¡çä¸ç§æ段ï¼è¯´ç´ç½ç¹å°±æ¯ç¨æ¥æ§å¶æ¹æ³æ¯å¦ä½¿ç¨åä¸äºå¡çä¸ç§å±æ§ï¼ä»¥åæç §ä»ä¹è§ååæ»çä¸ç§æ段ã
ä¸é¢ç¨ä»£ç æ¼ç¤ºè¿ä¸ç§å±æ§çæºå¶ï¼
äºå¡çé»è®¤å±æ§å°±æ¯requiredï¼éè¿Transactional.javaä¸çPropagation propagation() default Propagation.REQUIRED; å¯ä»¥çåºã
è¿ç§æ åµå°±æ¯äºå¡1ï¼äºå¡2 é½å å ¥å°äºäºå¡0ä¸ãä¸ç®¡æ¯1ï¼2åªä¸ªäºå¡æåºå¼å¸¸ï¼äºå¡0é½ä¼åæ»ãæ°æ®æ·»å ä¼å¤±è´¥ã
è¿ç§æ åµå°±æ¯ï¼
äºå¡0ï¼requiredï¼ {
äºå¡1 ï¼REQUIRES_NEWï¼
äºå¡2
}
æ¤æ¶ã
æ åµaï¼
1ãå¦æåªæ¯äºå¡2åºç°äºå¼å¸¸ï¼é£ä¹äºå¡1ä¼æ交ï¼äºå¡2å å ¥å°äºå¡0ä¸ä¼åæ»ã
2ãå¦æåªæ¯äºå¡1åºç°äºå¼å¸¸ï¼é£ä¹äºå¡1ä¼åæ»ï¼åä¸å±äºå¡0æå¼å¸¸ï¼äºå¡2ä¼å å ¥å°äºå¡0ä¸ï¼è¿æ¶é½ä¼åæ»ã
æ åµbï¼
å¦æäºå¡1ï¼äºå¡2é½æ¯REQUIRES_NEWä¼ æå±æ§ãé£ä¹ç»æå°±æ¯ï¼
1ãå¦æäºå¡1ï¼æåºäºå¼å¸¸ï¼é£ä¹äºå¡2æ¯ä¸ä¼æ§è¡çï¼é£ä¹äºå¡0å¿ ç¶åæ»ã
2ãå¦æäºå¡2ï¼æåºå¼å¸¸ï¼é£ä¹äºå¡1ä¼æ交ï¼è¡¨ä¸ä¼ææ°æ®ãäºå¡2æå¼å¸¸åæ»å¹¶æåºï¼äºå¡0åæ»ã
NESTEDå±æ§å ¶å®å°±æ¯å建äºåæ»ç¹ï¼æå¼å¸¸æ¶ï¼ä¼åæ»å°æå®çåæ»ç¹ã
å¨è¿éè¿ä»£ç æµè¯ï¼åºç°ä¸ç§æ åµæ¯ï¼æ 论äºå¡1ï¼äºå¡2åªä¸ªæå¼å¸¸ï¼æ°æ®é½ä¸ä¼æå ¥æåï¼åå æ¯ï¼ä¸è®ºæ¯äºå¡1è¿æ¯äºå¡2é½ä¼åäºå¡0æåºå¼å¸¸ï¼äºå¡0æè·å°å¼å¸¸åï¼æ§è¡rollback()æ¹æ³ï¼è¿å°±æä½æäºï¼äºå¡çå ¨é¨åæ»ã
å¦ææ³è¦äºå¡1åäºå¡2 æ³è¦æ ¹æ®èªå·±çåæ»ç¹åæ»ï¼é£ä¹äºå¡0å¿ é¡»èªå·±å¤çå¼å¸¸ï¼ä¸è®©springæè·å°è¿ä¸ªå¼å¸¸ï¼é£ä¹å°±æ»¡è¶³äºãæ代ç æ¹æè¿ç§ï¼
Jack大佬æä¾äºï¼ä¼ªä»£ç åææ³ã
æç §Springæºç çäºå¡å¤çé»è¾ï¼ä¼ªä»£ç 大è´ä¸ºï¼
@Transactional 详解
@Transactional 是声明式事务管理编程中使用的注解
1. 添加位置
1)接口实现类或接口实现方法上,而不是接口类中。2)访问权限:public 的方法才起作用。@Transactional 注解应该只被应用到 public 方法上,这是由 Spring AOP 的本质决定的。系统设计:将标签放置在需要进行事务管理的方法上,而不是放在所有接口实现类上:只读的接口就不需要事务管理,由于配置了@Transactional就需要AOP拦截及事务的处理,可能影响系统性能。
3)错误使用:
1. 接口中A、B两个方法,A无@Transactional标签,B有,上层通过A间接调用B,此时事务不生效。2. 接口中异常(运行时异常)被捕获而没有被抛出。默认配置下,spring 只有在抛出的异常为运行时 unchecked 异常时才回滚该事务,也就是抛出的异常为RuntimeException 的子类(Errors也会导致事务回滚),而抛出 checked 异常则不会导致事务回滚。可通过 @Transactional rollbackFor进行配置。3. 多线程下事务管理因为线程不属于 spring 托管,故线程不能默认使用 spring 的事务,也不能获取spring 注入的 bean。在被 spring 声明式事务管理的方法内开启多线程,多线程内的方法不被事务控制。一个使用了@Transactional 的方法,如果方法内包含多线程的使用,方法内部出现异常,不会回滚线程中调用方法的事务。
2. 声明式事务管理实现方式:基于 tx 和 aop 名字空间的 xml 配置文件
// 基本配置 // MyBatis 自动参与到 spring 事务管理中,无需额外配置,只要 org.mybatis.spring.SqlSessionFactoryBean 引用的数据源与 DataSourceTransactionManager 引用的数据源一致即可,否则事务管理会不起作用。 // 标签的声明,是在 Spring 内部启用 @Transactional 来进行事务管理,使用 @Transactional 前需要配置。
3. @Transactional注解 @Transactional 实质是使用了 JDBC 的事务来进行事务控制的 @Transactional 基于 Spring 的动态代理的机制
@Transactional 实现原理:1) 事务开始时,通过AOP机制,生成一个代理connection对象,并将其放入 DataSource 实例的某个与 DataSourceTransactionManager 相关的某处容器中。在接下来的整个事务中,客户代码都应该使用该 connection 连接数据库,执行所有数据库命令。[不使用该 connection 连接数据库执行的数据库命令,在本事务回滚的时候得不到回滚](物理连接 connection 逻辑上新建一个会话session; DataSource 与 TransactionManager 配置相同的数据源)2) 事务结束时,回滚在第1步骤中得到的代理 connection 对象上执行的数据库命令,然后关闭该代理 connection 对象。(事务结束后,回滚操作不会对已执行完毕的SQL操作命令起作用)
4. 声明式事务的管理实现本质:事务的两种开启方式:显示开启 start transaction | begin,通过 commit | rollback 结束事务 关闭数据库中自动提交 autocommit set autocommit = 0;MySQL 默认开启自动提交;通过手动提交或执行回滚操作来结束事务
Spring 关闭数据库中自动提交:在方法执行前关闭自动提交,方法执行完毕后再开启自动提交
// org.springframework.jdbc.datasource.DataSourceTransactionManager.java 源码实现 // switch to manual commit if necessary. this is very expensive in some jdbc drivers, // so we don't want to do it unnecessarily (for example if we've explicitly // configured the connection pool to set it already). if (con.getautocommit()) { txobject.setmustrestoreautocommit(true); if (logger.isdebugenabled()) { logger.debug("switching jdbc connection [" + con + "] to manual commit"); } con.setautocommit(false); }
问题:
关闭自动提交后,若事务一直未完成,即未手动执行 commit 或 rollback 时如何处理已经执行过的SQL操作?
C3P0 默认的策略是回滚任何未提交的事务 C3P0 是一个开源的JDBC连接池,它实现了数据源和 JNDI 绑定,支持 JDBC3 规范和 JDBC2 的标准扩展。目前使用它的开源项目有 Hibernate,Spring等 JNDI(Java Naming and Directory Interface,Java命名和目录接口)是SUN公司提供的一种标准的Java命名系统接口,JNDI提供统一的客户端API,通过不同的访问提供者接口JNDI服务供应接口(SPI)的实现,由管理者将JNDI API映射为特定的命名服务和目录系统,使得Java应用程序可以和这些命名服务和目录服务之间进行交互
------------------------------------------------------------------------------------------------------------------------------- 5. spring 事务特性 spring 所有的事务管理策略类都继承自 org.springframework.transaction.PlatformTransactionManager 接口
public interface PlatformTransactionManager { TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException; void commit(TransactionStatus status) throws TransactionException; void rollback(TransactionStatus status) throws TransactionException; }
事务的隔离级别:是指若干个并发的事务之间的隔离程度
1. @Transactional(isolation = Isolation.READ_UNCOMMITTED):读取未提交数据(会出现脏读, 不可重复读) 基本不使用 2. @Transactional(isolation = Isolation.READ_COMMITTED):读取已提交数据(会出现不可重复读和幻读) 3. @Transactional(isolation = Isolation.REPEATABLE_READ):可重复读(会出现幻读) 4. @Transactional(isolation = Isolation.SERIALIZABLE):串行化
事务传播行为:如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为
1. TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这是默认值。2. TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。3. TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。4. TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。5. TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。6. TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。7. TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
上表字段说明:
1. value :主要用来指定不同的事务管理器;主要用来满足在同一个系统中,存在不同的事务管理器。比如在Spring中,声明了两种事务管理器txManager1, txManager2。然后,用户可以根据这个参数来根据需要指定特定的txManager。2. value 适用场景:在一个系统中,需要访问多个数据源或者多个数据库,则必然会配置多个事务管理器。3. REQUIRED_NEW:内部的事务独立运行,在各自的作用域中,可以独立的回滚或者提交;而外部的事务将不受内部事务的回滚状态影响。4. ESTED 的事务,基于单一的事务来管理,提供了多个保存点。这种多个保存点的机制允许内部事务的变更触发外部事务的回滚。而外部事务在混滚之后,仍能继续进行事务处理,即使部分操作已经被混滚。由于这个设置基于 JDBC 的保存点,所以只能工作在 JDB C的机制。5. rollbackFor:让受检查异常回滚;即让本来不应该回滚的进行回滚操作。6. noRollbackFor:忽略非检查异常;即让本来应该回滚的不进行回滚操作。
SpringBoot源码之旅——事务
事务是数据操作的逻辑单元,旨在确保数据一致性和操作隔离。它包括两个核心目标:数据一致性和操作隔离。数据一致性要求事务提交后,所有操作成功执行,更改永久生效;而操作隔离则确保多个并发事务独立执行,互不影响。
事务管理资源不仅限于数据库,也涵盖了消息队列、文件系统等。通常讨论的事务主要指的是“数据库事务”。研究中,我们将围绕MySQL数据库和Spring声明式事务展开,但所涉及的事务概念、接口抽象和实现方式适用于更广泛的场景。
在实现声明式事务时,关键概念包括ACID(原子性、一致性、隔离性、持久性)、隔离级别和事务传播机制。实现依赖于AOP(面向切面编程),通过环绕增强在目标方法执行前后启动或提交事务。
事务增强通常涉及TransactionInterceptor,对于基于JDK接口动态代理的实现,要求方法必须为public或public final,且不能使用protected、private或static修饰。基于CGLib的字节码动态代理在扩展类时受限于final、static、private修饰符。
事务管理的核心接口包括TransactionDefinition(描述事务属性)和TransactionStatus(表示事务状态),而PlatformTransactionManager则负责创建和管理事务行为。
ThreadLocal机制用于共享数据库连接,确保同一线程内的操作在同一个事务中。不同线程下的嵌套调用则工作在独立事务中。
声明式事务通过生成代理对象实现,Spring的MethodInterceptor接口在Bean方法调用时触发TransactionInterceptor。TransactionInterceptor在invoke方法中通过TransactionAspectSupport处理事务,支持声明式和编程式事务。
事务传播机制中,Spring通过AbstractPlatformTransactionManager获取当前事务状态。在DataSourceTransactionManager的具体实现中,通过TransactionSynchronizationManager记录当前事务资源和同步回调,确保操作在一致的事务上下文中执行。
TransactionSynchronizationManager通过ThreadLocal记录资源和同步信息,便于事务同步。在事务提交流程中,触发回调以精确控制事务操作的不同阶段。
实现细节涉及流程图和具体的代码示例,这些内容有助于深入理解Spring事务管理的实现。参考资源包括网易云信的技术文章、柳树关于Spring事务的讲解,以及《精通Spring 4.x 企业应用开发实战》等书籍。
个示例详解 Spring 事务传播机制
事务传播机制是Spring框架中管理事务执行的关键概念,它定义了如何在多个方法调用间传播事务行为。这一机制是通过Propagation枚举类中的七个属性来实现的,涵盖了从默认事务到特定场景的事务控制。
举例来说,假设方法A是一个事务方法,如果它在执行过程中调用了方法B,方法B的事务状态和是否需要事务将对方法A和B产生影响。这种影响是由调用方法的传播机制决定的。
在Spring中,事务的传播机制被定义在Propagation枚举中,包括但不限于默认事务、在已有事务中加入、创建新事务等七种情况。下面将对这七种传播机制进行深入解析。
首先,我们定义两个方法,一个用于插入数据A,另一个用于插入数据B。在main方法中调用test方法,若这两个方法都不使用事务,那么数据A和数据B将如何存储呢?答案是,数据A和数据B都成功存储。但当抛出异常后,数据B不会执行,因此最终数据A和B都存储成功,而B没有存储。
现在让我们来看具体每种传播机制的执行效果:
1. REQUIRED(默认事务):如果当前不存在事务,就新建一个事务。如果存在事务,就加入到当前事务。这是默认的行为,适用于大多数场景。
2. SUPPORTS:如果当前没有事务,则以非事务的方式运行。如果存在事务,就加入到当前事务。使用此属性时,如果没有事务,两个方法都会以非事务方式运行,导致数据A和B都成功存储。
3. MANDATORY:如果存在事务,就加入到当前事务。如果不存在事务,就报错。意味着只有在有事务的情况下方法才能执行,否则会报错。
4. REQUIRES_NEW:创建一个新的事务。如果存在事务,就将事务挂起。无论是否存在事务,都会创建新事务进行执行。
5. NOT_SUPPORTED:无论是否存在当前事务,都是以非事务的方式运行。使用此属性时,无论有无事务,两个方法都将以非事务方式执行,数据A和B都能成功存储。
6. NEVER:不使用事务,如果存在事务,就抛出异常。这意味着无论任何情况,都不会使用事务,如果有事务存在,方法执行会抛出异常。
7. NESTED:如果当前事务存在,就运行一个嵌套事务。如果不存在事务,就和REQUIRED一样新建一个事务。使用此属性时,如果已有事务,则创建嵌套事务进行执行。
总结:通过上述示例和解析,我们可以清晰地看到不同传播机制对事务执行的影响,以及它们在实际开发中的适用场景。理解这些机制对于合理设计和管理事务至关重要。在实际编码和测试过程中,需要根据业务需求选择合适的传播属性,确保代码的健壮性和事务的正确性。同时,也可以参考源码实现,以更深入地理解Spring事务管理的底层逻辑。
Spring事务注解@Transactional原理解析
事务管理是应用系统开发的关键部分,Spring 提供了丰富且方便的事务管理解决方案,显著简化了代码编写并提高了可维护性。
以原生JDBC事务处理与Spring的事务处理进行对比,原生代码中充斥着复杂且重复的事务管理逻辑,而使用Spring则通过简单的注解即可实现。例如,针对保存三张表数据的需求(country、city、category),若采用原生JDBC,代码会显得冗长且难于维护。而在Spring中,通过设置特定的事务属性,如`Propagation.REQUIRES_NEW`,只需在对应方法上添加`@Transactional`注解,Spring便会自动处理事务,极大简化了代码。
Spring的声明式事务机制,通过`TransactionAutoConfiguration`类自动配置事务相关组件,并由`TransactionInterceptor`类执行事务处理逻辑,实现了对带有`@Transactional`注解的方法的代理。此单例对象确保了所有事务逻辑的一致性和高效性。
在使用`@Transactional`注解时,需要关注其属性的含义,包括`propagation`和`isolation`。`propagation`属性定义了事务的传播行为,如是否需要新事务、是否在当前事务中进行等。`isolation`属性则决定了事务的隔离级别,确保不同事务之间数据的一致性。
进一步深入了解`@Transactional`注解的实现细节,可参阅Spring源码。GitHub和Gitee提供该代码的同步版本,方便开发者深入研究。


2024-12-27 16:20
2024-12-27 15:12
2024-12-27 15:08
2024-12-27 14:39
2024-12-27 14:35
2024-12-27 14:30
2024-12-27 14:24
2024-12-27 14:24