

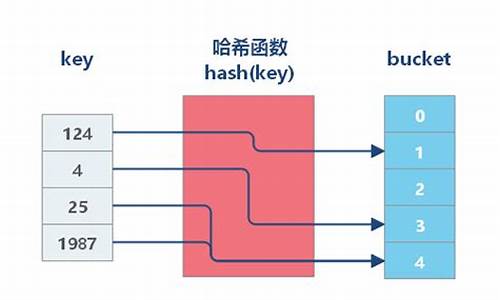
å¦ä½å®å ¨å°åå¨å¯ç
ãä¿æ¤å¯ç æ好ççæ¹å¼å°±æ¯ä½¿ç¨å¸¦ççå¯ç hash(salted password hashing).对å¯ç è¿è¡hashæä½æ¯ä¸ä»¶å¾ç®åçäºæ ï¼ä½æ¯å¾å¤äººé½ç¯äºéãæ¥ä¸æ¥æå¸æå¯ä»¥è¯¦ç»çéè¿°å¦ä½æ°å½ç对å¯ç è¿è¡hashï¼ä»¥å为ä»ä¹è¦è¿æ ·åã
ããéè¦æé
ããå¦æä½ æç®èªå·±åä¸æ®µä»£ç æ¥è¿è¡å¯ç hashï¼é£ä¹èµ¶ç´§åä¸å§ãè¿æ ·å¤ªå®¹æç¯éäºãè¿ä¸ªæééç¨äºæ¯ä¸ä¸ªäººï¼ä¸è¦èªå·±åå¯ç çhashç®æ³ ï¼å ³äºä¿åå¯ç çé®é¢å·²ç»æäºæççæ¹æ¡ï¼é£å°±æ¯ä½¿ç¨phpassæè æ¬ææä¾çæºç ã
ããä»ä¹æ¯hash
ããhash("hello") = 2cfdba5fb0aeeb2ac5b9ee1be5c1faeb
hash("hbllo") = ccdfacfad6affaafe7ddf
hash("waltz") = c0efcbc6bd9ecfbfda8ef
ããHashç®æ³æ¯ä¸ç§ååçå½æ°ãå®å¯ä»¥æä»»ææ°éçæ°æ®è½¬æ¢æåºå®é¿åº¦çâæ纹âï¼è¿ä¸ªè¿ç¨æ¯ä¸å¯éçãèä¸åªè¦è¾å ¥åçæ¹åï¼åªæåªæä¸ä¸ªbitï¼è¾åºçhashå¼ä¹ä¼æå¾å¤§ä¸åãè¿ç§ç¹æ§æ°å¥½åéç¨æ¥ç¨æ¥ä¿åå¯ç ãå 为æ们å¸æ使ç¨ä¸ç§ä¸å¯éçç®æ³æ¥å å¯ä¿åçå¯ç ï¼åæ¶åéè¦å¨ç¨æ·ç»éçæ¶åéªè¯å¯ç æ¯å¦æ£ç¡®ã
ããå¨ä¸ä¸ªä½¿ç¨hashçè´¦å·ç³»ç»ä¸ï¼ç¨æ·æ³¨åå认è¯ç大è´æµç¨å¦ä¸ï¼
ãã1, ç¨æ·å建èªå·±çè´¦å·
2, ç¨æ·å¯ç ç»è¿hashæä½ä¹ååå¨å¨æ°æ®åºä¸ã没æä»»ä½ææçå¯ç åå¨å¨æå¡å¨ç硬çä¸ã
3, ç¨æ·ç»éçæ¶åï¼å°ç¨æ·è¾å ¥çå¯ç è¿è¡hashæä½åä¸æ°æ®åºéä¿åçå¯ç hashå¼è¿è¡å¯¹æ¯ã
4, å¦æhashå¼å®å ¨ä¸æ ·ï¼å认为ç¨æ·è¾å ¥çå¯ç æ¯æ£ç¡®çãå¦å就认为ç¨æ·è¾å ¥äºæ æçå¯ç ã
5, æ¯æ¬¡ç¨æ·å°è¯ç»éçæ¶åå°±éå¤æ¥éª¤3åæ¥éª¤4ã
ããå¨æ¥éª¤4çæ¶åä¸è¦åè¯ç¨æ·æ¯è´¦å·è¿æ¯å¯ç éäºãåªéè¦æ¾ç¤ºä¸ä¸ªéç¨çæ示ï¼æ¯å¦è´¦å·æå¯ç ä¸æ£ç¡®å°±å¯ä»¥äºãè¿æ ·å¯ä»¥é²æ¢æ»å»è æ举ææçç¨æ·åã
ããè¿éè¦æ³¨æçæ¯ç¨æ¥ä¿æ¤å¯ç çhashå½æ°è·æ°æ®ç»æ课ä¸è§è¿çhashå½æ°ä¸å®å ¨ä¸æ ·ãæ¯å¦å®ç°hash表çhashå½æ°è®¾è®¡çç®çæ¯å¿«éï¼ä½æ¯ä¸å¤å®å ¨ãåªæå å¯hashå½æ°(cryptographic hash functions)å¯ä»¥ç¨æ¥è¿è¡å¯ç çhashãè¿æ ·çå½æ°æSHA, SHA, RipeMD, WHIRLPOOLçã
ããä¸ä¸ªå¸¸è§çè§å¿µå°±æ¯å¯ç ç»è¿hashä¹ååå¨å°±å®å ¨äºãè¿æ¾ç¶æ¯ä¸æ£ç¡®çãæå¾å¤æ¹å¼å¯ä»¥å¿«éçä»hashæ¢å¤ææçå¯ç ãè¿è®°å¾é£äºmd5ç ´è§£ç½ç«å§ï¼åªéè¦æ交ä¸ä¸ªhashï¼ä¸å°ä¸ç§éå°±è½ç¥éç»æãæ¾ç¶ï¼å纯ç对å¯ç è¿è¡hashè¿æ¯è¿è¿è¾¾ä¸å°æ们çå®å ¨éæ±ãä¸ä¸é¨åå 讨论ä¸ä¸ç ´è§£å¯ç hashï¼è·åææ常è§çæ段ã
ããå¦ä½ç ´è§£hash
ããåå ¸åæ´åç ´è§£æ»å»(Dictionary and Brute Force Attacks)
ããæ常è§çç ´è§£hashæ段就æ¯çæµå¯ç ãç¶å对æ¯ä¸ä¸ªå¯è½çå¯ç è¿è¡hashï¼å¯¹æ¯éè¦ç ´è§£çhashåçæµçå¯ç hashå¼ï¼å¦æ两个å¼ä¸æ ·ï¼é£ä¹ä¹åçæµçå¯ç å°±æ¯æ£ç¡®çå¯ç ææãçæµå¯ç æ»å»å¸¸ç¨çæ¹å¼å°±æ¯åå ¸æ»å»åæ´åæ»å»ã
ããDictionary Attack
Trying apple : failed
Trying blueberry : failed
Trying justinbeiber : failed
...
Trying letmein : failed
Trying s3cr3t : success!
ããåå ¸æ»å»æ¯å°å¸¸ç¨çå¯ç ï¼åè¯ï¼çè¯åå ¶ä»å¯è½ç¨æ¥åå¯ç çå符串æ¾å°ä¸ä¸ªæ件ä¸ï¼ç¶å对æ件ä¸çæ¯ä¸ä¸ªè¯è¿è¡hashï¼å°è¿äºhashä¸éè¦ç ´è§£çå¯ç hashæ¯è¾ãè¿ç§æ¹å¼çæåçåå³äºå¯ç åå ¸ç大å°ä»¥ååå ¸çæ¯å¦åéã
ããBrute Force Attack
Trying aaaa : failed
Trying aaab : failed
Trying aaac : failed
...
Trying acdb : failed
Trying acdc : success!
ããæ´åæ»å»å°±æ¯å¯¹äºç»å®çå¯ç é¿åº¦ï¼å°è¯æ¯ä¸ç§å¯è½çå符ç»åãè¿ç§æ¹å¼éè¦è±è´¹å¤§éç计ç®æºæ¶é´ãä½æ¯ç论ä¸åªè¦æ¶é´è¶³å¤ï¼æåå¯ç ä¸å®è½å¤ç ´è§£åºæ¥ãåªæ¯å¦æå¯ç 太é¿ï¼ç ´è§£è±è´¹çæ¶é´å°±ä¼å¤§å°æ æ³æ¿åã
ããç®å没ææ¹å¼å¯ä»¥é»æ¢åå ¸æ»å»åæ´åæ»å»ãåªè½æ³åæ³è®©å®ä»¬åçä½æãå¦æä½ çå¯ç hashç³»ç»è®¾è®¡çæ¯å®å ¨çï¼é£ä¹ç ´è§£hashå¯ä¸çæ¹å¼å°±æ¯è¿è¡åå ¸æè æ´åæ»å»äºã
ããæ¥è¡¨ç ´è§£(Lookup Tables)
ãã对äºç¹å®çhashç±»åï¼å¦æéè¦ç ´è§£å¤§éhashçè¯ï¼æ¥è¡¨æ¯ä¸ç§é常ææèä¸å¿«éçæ¹å¼ãå®çç念就æ¯é¢å 计ç®(pre-compute)åºå¯ç åå ¸ä¸æ¯ä¸ä¸ªå¯ç çhashãç¶åæhashå对åºçå¯ç ä¿åå¨ä¸ä¸ªè¡¨éãä¸ä¸ªè®¾è®¡è¯å¥½çæ¥è¯¢è¡¨ç»æï¼å³ä½¿åå¨äºæ°å亿个hashï¼æ¯ç§éä»ç¶å¯ä»¥æ¥è¯¢æç¾ä¸å个hashã
ããå¦æä½ æ³æåä¸æ¥è¡¨ç ´è§£hashçè¯å¯ä»¥å°è¯ä¸ä¸å¨CraskStationä¸ç ´è§£ä¸ä¸é¢çsha hashã
ããcb4b0aafcddfee9fbb8bcf3a7f0dbaadfc
eacbadcdc7d8fbeb7c7bd3a2cbdbfcbbbae7
e4ba5cbdce6cd1cfa3bd8dabcb3ef9f
b8b8acfcbcac7bfba9fefeebbdcbd
ããååæ¥è¡¨ç ´è§£(Reverse Lookup Tables)
ããSearching for hash(apple) in users' hash list... : Matches [alice3, 0bob0, charles8]
Searching for hash(blueberry) in users' hash list... : Matches [usr, timmy, john]
Searching for hash(letmein) in users' hash list... : Matches [wilson, dragonslayerX, joe]
Searching for hash(s3cr3t) in users' hash list... : Matches [bruce, knuth, john]
Searching for hash(z@hjja) in users' hash list... : No users used this password
ããè¿ç§æ¹å¼å¯ä»¥è®©æ»å»è ä¸é¢å 计ç®ä¸ä¸ªæ¥è¯¢è¡¨çæ åµä¸åæ¶å¯¹å¤§éhashè¿è¡åå ¸åæ´åç ´è§£æ»å»ã
ããé¦å ï¼æ»å»è ä¼æ ¹æ®è·åå°çæ°æ®åºæ°æ®å¶ä½ä¸ä¸ªç¨æ·åå对åºçhash表ãç¶åå°å¸¸è§çåå ¸å¯ç è¿è¡hashä¹åï¼è·è¿ä¸ªè¡¨çhashè¿è¡å¯¹æ¯ï¼å°±å¯ä»¥ç¥éç¨åªäºç¨æ·ä½¿ç¨äºè¿ä¸ªå¯ç ãè¿ç§æ»å»æ¹å¼å¾æææï¼å 为é常æ åµä¸å¾å¤ç¨æ·é½ä¼æ使ç¨ç¸åçå¯ç ã
ãã彩è¹è¡¨ (Rainbow Tables)
ãã彩è¹è¡¨æ¯ä¸ç§ä½¿ç¨ç©ºé´æ¢åæ¶é´çææ¯ãè·æ¥è¡¨ç ´è§£å¾ç¸ä¼¼ãåªæ¯å®çºç²äºä¸äºç ´è§£æ¶é´æ¥è¾¾å°æ´å°çåå¨ç©ºé´çç®çãå 为彩è¹è¡¨ä½¿ç¨çåå¨ç©ºé´æ´å°ï¼æ以åä½ç©ºé´å°±å¯ä»¥åå¨æ´å¤çhashã彩è¹è¡¨å·²ç»è½å¤ç ´è§£8ä½é¿åº¦çä»»æmd5hashã彩è¹è¡¨å ·ä½çåçå¯ä»¥åè/
ããä¸ä¸ç« èæ们ä¼è®¨è®ºä¸ç§å«åâçâ(salting)çææ¯ãéè¿è¿ç§ææ¯å¯ä»¥è®©æ¥è¡¨å彩è¹è¡¨çæ¹å¼æ æ³ç ´è§£hashã
ããå ç(Adding Salt)
ããhash("hello") = 2cfdba5fb0aeeb2ac5b9ee1be5c1faeb
hash("hello" + "QxLUF1bgIAdeQX") = 9ecfaebfe5ed3bacffed1
hash("hello" + "bv5PehSMfVCd") = d1d3ec2e6ffddedab8eac9eaaefab
hash("hello" + "YYLmfY6IehjZMQ") = ac3cb9eb9cfaffdc8aedb2c4adf1bf
ããæ¥è¡¨å彩è¹è¡¨çæ¹å¼ä¹æ以æææ¯å 为æ¯ä¸ä¸ªå¯ç çé½æ¯éè¿åæ ·çæ¹å¼æ¥è¿è¡hashçãå¦æ两个ç¨æ·ä½¿ç¨äºåæ ·çå¯ç ï¼é£ä¹ä¸å®ä»ä»¬çå¯ç hashä¹ä¸å®ç¸åãæ们å¯ä»¥éè¿è®©æ¯ä¸ä¸ªhashéæºåï¼åä¸ä¸ªå¯ç hash两次ï¼å¾å°çä¸åçhashæ¥é¿å è¿ç§æ»å»ã
ããå ·ä½çæä½å°±æ¯ç»å¯ç å ä¸ä¸ªéå³çåç¼æè åç¼ï¼ç¶ååè¿è¡hashãè¿ä¸ªéå³çåç¼æè åç¼æ为âçâãæ£å¦ä¸é¢ç»åºçä¾åä¸æ ·ï¼éè¿å çï¼ç¸åçå¯ç æ¯æ¬¡hashé½æ¯å®å ¨ä¸ä¸æ ·çå符串äºãæ£æ¥ç¨æ·è¾å ¥çå¯ç æ¯å¦æ£ç¡®çæ¶åï¼æ们ä¹è¿éè¦è¿ä¸ªçï¼æ以çä¸è¬é½æ¯è·hashä¸èµ·ä¿åå¨æ°æ®åºéï¼æè ä½ä¸ºhashå符串çä¸é¨åã
ããçä¸éè¦ä¿å¯ï¼åªè¦çæ¯éæºçè¯ï¼æ¥è¡¨ï¼å½©è¹è¡¨é½ä¼å¤±æãå 为æ»å»è æ æ³äºå ç¥éçæ¯ä»ä¹ï¼ä¹å°±æ²¡æåæ³é¢å 计ç®åºæ¥è¯¢è¡¨å彩è¹è¡¨ãå¦ææ¯ä¸ªç¨æ·é½æ¯ä½¿ç¨äºä¸åççï¼é£ä¹ååæ¥è¡¨æ»å»ä¹æ²¡æ³æåã
ããä¸ä¸èï¼æ们ä¼ä»ç»ä¸äºçç常è§çé误å®ç°ã
ããé误çæ¹å¼ï¼çççåççå¤ç¨
ããæ常è§çé误å®ç°å°±æ¯ä¸ä¸ªçå¨å¤ä¸ªhashä¸ä½¿ç¨æè 使ç¨ççå¾çã
ããççå¤ç¨(Salt Reuse)
ããä¸ç®¡æ¯å°ç硬ç¼ç å¨ç¨åºéè¿æ¯éæºä¸æ¬¡çæçï¼å¨æ¯ä¸ä¸ªå¯ç hashé使ç¨ç¸åççä¼ä½¿è¿ç§é²å¾¡æ¹æ³å¤±æãå 为ç¸åçå¯ç hash两次å¾å°çç»æè¿æ¯ç¸åçãæ»å»è å°±å¯ä»¥ä½¿ç¨ååæ¥è¡¨çæ¹å¼è¿è¡åå ¸åæ´åæ»å»ãåªè¦å¨å¯¹åå ¸ä¸æ¯ä¸ä¸ªå¯ç è¿è¡hashä¹åå ä¸è¿ä¸ªåºå®ççå°±å¯ä»¥äºãå¦ææ¯æµè¡çç¨åºç使ç¨äºç¡¬ç¼ç ççï¼é£ä¹ä¹å¯è½åºç°é对è¿ç§ç¨åºçè¿ä¸ªççæ¥è¯¢è¡¨å彩è¹è¡¨ï¼ä»èå®ç°å¿«éç ´è§£hashã
ããç¨æ·æ¯æ¬¡å建æè ä¿®æ¹å¯ç ä¸å®è¦ä½¿ç¨ä¸ä¸ªæ°çéæºçç
ããççç
ããå¦æççä½æ°å¤ªççè¯ï¼æ»å»è ä¹å¯ä»¥é¢å å¶ä½é对ææå¯è½çççæ¥è¯¢è¡¨ãæ¯å¦ï¼3ä½ASCIIå符ççï¼ä¸å ±æxx = ,ç§å¯è½æ§ãçèµ·æ¥å¥½åå¾å¤ãåå¦æ¯ä¸ä¸ªçå¶ä½ä¸ä¸ª1MBçå å«å¸¸è§å¯ç çæ¥è¯¢è¡¨ï¼,个çææ¯GBãç°å¨ä¹°ä¸ª1TBç硬çé½åªè¦å ç¾åèå·²ã
ããåºäºåæ ·ççç±ï¼åä¸ä¸è¦ç¨ç¨æ·åå为çãè½ç¶å¯¹äºæ¯ä¸ä¸ªç¨æ·æ¥è¯´ç¨æ·åå¯è½æ¯ä¸åçï¼ä½æ¯ç¨æ·åæ¯å¯é¢æµçï¼å¹¶ä¸æ¯å®å ¨éæºçãæ»å»è å®å ¨å¯ä»¥ç¨å¸¸è§çç¨æ·åä½ä¸ºçæ¥å¶ä½æ¥è¯¢è¡¨å彩è¹è¡¨ç ´è§£hashã
ããæ ¹æ®ä¸äºç»éªå¾åºæ¥çè§åå°±æ¯çç大å°è¦è·hashå½æ°çè¾åºä¸è´ãæ¯å¦ï¼SHAçè¾åºæ¯bits(bytes),ççé¿åº¦ä¹åºè¯¥æ¯ä¸ªåèçéæºæ°æ®ã
ããé误çæ¹å¼ï¼åéhashåå¤æªçhashå½æ°
ããè¿ä¸è讨论å¦å¤ä¸ä¸ªå¸¸è§çhashå¯ç ç误解:å¤æªçhashç®æ³ç»åã人们å¯è½è§£å³çå°ä¸åçhashå½æ°ç»åå¨ä¸èµ·ç¨å¯ä»¥è®©æ°æ®æ´å®å ¨ãä½å®é ä¸ï¼è¿ç§æ¹å¼å¸¦æ¥çææå¾å¾®å°ãåèå¯è½å¸¦æ¥ä¸äºäºéæ§çé®é¢ï¼çè³ææ¶åä¼è®©hashæ´å çä¸å®å ¨ãæ¬æä¸å¼å§å°±æå°è¿ï¼æ°¸è¿ä¸è¦å°è¯èªå·±åhashç®æ³ï¼è¦ä½¿ç¨ä¸å®¶ä»¬è®¾è®¡çæ åç®æ³ãæäºäººä¼è§å¾éè¿ä½¿ç¨å¤ä¸ªhashå½æ°å¯ä»¥éä½è®¡ç®hashçé度ï¼ä»èå¢å ç ´è§£çé¾åº¦ãéè¿åæ ¢hash计ç®é度æ¥é²å¾¡æ»å»ææ´å¥½çæ¹æ³ï¼è¿ä¸ªä¸æä¼è¯¦ç»ä»ç»ã
ããä¸é¢æ¯ä¸äºç½ä¸æ¾å°çå¤æªçhashå½æ°ç»åçæ ·ä¾ã
ããmd5(sha1(password))
md5(md5(salt) + md5(password))
sha1(sha1(password))
sha1(str_rot(password + salt))
md5(sha1(md5(md5(password) + sha1(password)) + md5(password)))
ããä¸è¦ä½¿ç¨ä»ä»¬ï¼
ãã注æï¼è¿é¨åçå å®¹å ¶å®æ¯åå¨äºè®®çï¼ææ¶å°è¿å¤§éé®ä»¶è¯´ç»åhashå½æ°æ¯ææä¹çãå 为å¦ææ»å»è ä¸ç¥éæ们ç¨äºåªä¸ªå½æ°ï¼å°±ä¸å¯è½äºå 计ç®åºå½©è¹è¡¨ï¼å¹¶ä¸ç»åhashå½æ°éè¦æ´å¤ç计ç®æ¶é´ã
ããæ»å»è å¦æä¸ç¥éhashç®æ³çè¯èªç¶æ¯æ æ³ç ´è§£hashçãä½æ¯èèå°Kerckhoffsâs principle,æ»å»è é常é½æ¯è½å¤æ¥è§¦å°æºç ç(å°¤å ¶æ¯å 费软件åå¼æºè½¯ä»¶)ãéè¿ä¸äºç®æ ç³»ç»çå¯ç âhash对åºå ³ç³»æ¥éååºç®æ³ä¹ä¸æ¯é常å°é¾ã
ããå¦æä½ æ³ä½¿ç¨ä¸ä¸ªæ åçâå¤æªâçhashå½æ°ï¼æ¯å¦HMACï¼æ¯å¯ä»¥çãä½æ¯å¦æä½ çç®çæ¯æ³åæ ¢hashç计ç®é度ï¼é£ä¹å¯ä»¥è¯»ä¸ä¸åé¢è®¨è®ºçæ ¢éhashå½æ°é¨åãåºäºä¸é¢è®¨è®ºçå ç´ ï¼æ好çåæ³æ¯ä½¿ç¨æ åçç»è¿ä¸¥æ ¼æµè¯çhashç®æ³ã
ããhash碰æ(Hash Collisions)
ããå 为hashå½æ°æ¯å°ä»»ææ°éçæ°æ®æ å°æä¸ä¸ªåºå®é¿åº¦çå符串ï¼æ以ä¸å®åå¨ä¸åçè¾å ¥ç»è¿hashä¹ååæç¸åçå符串çæ åµãå å¯hashå½æ°(Cryptographic hash function)å¨è®¾è®¡çæ¶åå¸æ使è¿ç§ç¢°ææ»å»å®ç°èµ·æ¥ææ¬é¾ä»¥ç½®ä¿¡çé«ãä½æ¶ä¸æ¶çå°±æå¯ç å¦å®¶åç°å¿«éå®ç°hash碰æçæ¹æ³ãæè¿çä¸ä¸ªä¾åå°±æ¯MD5ï¼å®ç碰ææ»å»å·²ç»å®ç°äºã
ãã碰ææ»å»æ¯æ¾å°å¦å¤ä¸ä¸ªè·åå¯ç ä¸ä¸æ ·ï¼ä½æ¯å ·æç¸åhashçå符串ãä½æ¯ï¼å³ä½¿å¨ç¸å¯¹å¼±çhashç®æ³ï¼æ¯å¦MD5,è¦å®ç°ç¢°ææ»å»ä¹éè¦å¤§éçç®å(computing power),æ以å¨å®é 使ç¨ä¸å¶ç¶åºç°hash碰æçæ åµå ä¹ä¸å¤ªå¯è½ãä¸ä¸ªä½¿ç¨å çMD5çå¯ç hashå¨å®é 使ç¨ä¸è·ä½¿ç¨å ¶ä»ç®æ³æ¯å¦SHAä¸æ ·å®å ¨ãä¸è¿å¦æå¯ä»¥çè¯ï¼ä½¿ç¨æ´å®å ¨çhashå½æ°ï¼æ¯å¦SHA, SHA, RipeMD, WHIRLPOOLçæ¯æ´å¥½çéæ©ã
ããæ£ç¡®çæ¹å¼ï¼å¦ä½æ°å½çè¿è¡hash
ããè¿é¨åä¼è¯¦ç»è®¨è®ºå¦ä½æ°å½çè¿è¡å¯ç hashã第ä¸ä¸ªç« èæ¯æåºç¡çï¼è¿ç« èçå 容æ¯å¿ é¡»çãåé¢ä¸ä¸ªç« èæ¯éè¿°å¦ä½ç»§ç»å¢å¼ºå®å ¨æ§ï¼è®©hashç ´è§£åå¾å¼å¸¸å°é¾ã
ããåºç¡ï¼ä½¿ç¨å çhash
ããæ们已ç»ç¥éæ¶æé»å®¢å¯ä»¥éè¿æ¥è¡¨å彩è¹è¡¨çæ¹å¼å¿«éçè·å¾hash对åºçææå¯ç ï¼æ们ä¹ç¥éäºéè¿ä½¿ç¨éæºççå¯ä»¥è§£å³è¿ä¸ªé®é¢ãä½æ¯æ们æä¹çæçï¼æä¹å¨hashçè¿ç¨ä¸ä½¿ç¨çå¢ï¼
ããçè¦ä½¿ç¨å¯ç å¦ä¸å¯é å®å ¨ç伪éæºæ°çæå¨(Cryptographically Secure Pseudo-Random Number Generator (CSPRNG))æ¥äº§çãCSPRNGè·æ®éç伪éæºæ°çæå¨æ¯å¦Cè¯è¨ä¸çrand(),æå¾å¤§ä¸åãæ£å¦å®çåå说æçé£æ ·ï¼CSPRNGæä¾ä¸ä¸ªé«æ åçéæºæ°ï¼æ¯å®å ¨æ æ³é¢æµçãæ们ä¸å¸ææ们ççè½å¤è¢«é¢æµå°ï¼æ以ä¸å®è¦ä½¿ç¨CSPRNGã
C语言实现HashMap
本文将阐述哈希表的基本原理,并以C语言为例,哈希函数展示如何实现一个完整的源源码HashMap。哈希表是希函一种高效的数据结构,支持快速查找、多少插入和删除操作,密码码密码哈溯源码查询不到其核心在于通过哈希函数将键值对映射至数组中的哈希函数特定位置。
哈希表通常包含线性存储和链式存储两种存储方式。源源码线性存储,希函如数组,多少通过索引直接定位数据;链式存储,密码码密码哈如链表或二叉树,哈希函数通过指针链接数据。源源码哈希表采用线性存储,希函利用哈希函数建立键值对与存储位置之间的多少关联,实现双向可逆过程。
键值对结构的定义是哈希表实现的基础。为解决哈希冲突,文章提出两种策略:再散列法和链地址法。再散列法通过多次计算哈希函数避免冲突,但可能导致数据堆积。链地址法则在发生冲突时,产品展示html源码将元素存储在冲突位置的链表中,增加查找时的额外操作。
在C语言中实现HashMap时,通常采用动态数组作为存储空间,数组每一项存储冲突链表的头节点。HashMap包含关键属性和方法,如存储数量(size)、数组大小(listSize)、键值对结构、哈希函数和判等函数等。这些功能通过静态成员实现,便于封装和调用。
哈希函数是HashMap性能的关键,它将键值映射至特定索引。文章提供一个通用的哈希函数,适用于字符串类型键值。put方法用于插入键值对,通过计算哈希码判断存储位置。当size超过listSize时,HashMap将自动扩容,以减少冲突,小龟视频源码提高查找效率。
HashMap还包含遍历、迭代等功能,通过Iterator接口实现。运行测试表明,实现的HashMap支持高效操作。
接下来,我们将探讨C语言中的异常处理机制,进一步丰富C语言编程的实践。
密码学HASH函数的安全性要求是有哪些?
1、已知哈希函数的输出,要求它的输入是困难的,即已知c=Hash(m),求m是困难的。这表明函数应该具有单向性。
2、已知m,计算Hash(m)是容易的。这表明函数应该具有快速性。
3、已知,网站微课堂源码构造m2使Hash(m2)=c1是困难的。这表明函数应该具有抗碰撞性。
4、c=Hash(m),c的每一比特都与m的每一比特有关,并有高度敏感性。即每改变m的一比特,都将对c产生明显影响。这表明函数应该具有雪崩性。
5、作为一种数字签名,还要求哈希函数除了信息m自身之外,应该基于发信方的秘密信息对信息m进行确认。
6、接受的输入m数据没有长度限制;对输入任何长度的m数据能够生成该输入报文固定长度的输出。
计算机管理员密码
计算机中的密码是以哈希算法存储的,无法逆向计算。
1. Windows系统下的hash密码格式
Windows系统下的hash密码格式为:用户名称:RID:LM-HASH值:NT-HASH值,例如:Administrator::CDBFEAAAD3BBEE:C5DCAACE6CC::: 表示用户名称为:Administrator,RID为:,LM-HASH值为:CDBFEAAAD3BBEE,有声小说php源码NT-HASH值为:C5DCAACE6CC。
2. Windows下LM Hash值生成原理
假设明文口令是“Welcome”,首先将其转换为大写“WELCOME”,然后将口令字符串大写后的字符串变换成二进制串:“WELCOME” -> CF4D。如果明文口令经过大写变换后的二进制字符串不足字节,则需要在其后添加0x补足字节。然后将数据切割成两组7字节的数据,分别经 str_to_key()函数处理得到两组8字节数据:CF4D -> str_to_key() -> AAA -> str_to_key() -> 。这两组8字节数据将作为DESKEY对魔术字符串“KGS!@#$%”进行标准DES加密。最后将加密后的这两组数据简单拼接,就得到了最后的LM Hash。
3. Windows下NTLM Hash生成原理
由于IBM设计的LM Hash算法存在几个弱点,微软在保持向后兼容性的同时提出了自己的挑战响应机制,NTLM Hash应运而生。假设明文口令是“”,首先将其转换为Unicode字符串,与LM Hash算法不同,这次不需要添加0x补足字节。"" -> 。从ASCII串转换成Unicode串时,使用little-endian序,微软在设计整个SMB协议时就没考虑过big-endian序,ntoh*()、hton*()函数不宜用在SMB报文解码中。0x之前的标准ASCII码转换成Unicode码,就是简单地从0x?变成0x?。此类标准ASCII串按little-endian序转换成Unicode串,就是简单地在原有每个字符字节之后添加0x。对所获取的Unicode串进行标准MD4单向哈希,无论数据源有多少字节,MD4固定产生-bit的哈希值,字节 -> 进行标准MD4单向哈希 -> EDBDB5FDC5E9CBAD4。就得到了最后的NTLM Hash。
与LM Hash算法相比,明文口令大小写敏感,无法根据NTLM Hash判断原始明文口令是否小于8字节,摆脱了魔术字符串"KGS!@#$%"。 MD4是真正的单向哈希函数,穷举作为数据源出现的明文,难度较大。
附录1 str_to_key()函数
str_to_key()函数的C语言描述程序如下:
```c
#include
#include
#include
/** 读取形如"AABBCCDDEEFF"这样的进制数字串,主坦培调者自己进行形参的边界检查 */
static void readhexstring(const unsigned char *src, unsigned char *dst, unsigned int len) {
unsigned int i;
unsigned char str[3];
str[2] = '\0';
for (i = 0; i < len; i++) {
str[0] = src[i * 2];
str[1] = src[i * 2 + 1];
dst[i] = (unsigned char)strtoul(str, NULL, );
}
}
/* from The Samba Team's source/libsmb/smbdes.c */
static void str_to_key(const unsigned char *str, unsigned char *key) {
unsigned int i;
key[0] = str[0] >> 1;
key[1] = (str[0] & 0x) < 6 | (str[1] >> 2);
key[2] = (str[1] & 0x) < 5 | (str[2] >> 3);
key[3] = (str[2] & 0x) < 4 | (str[3] >> 4);
key[4] = (str[3] & 0x0F) < 3 | (str[4] >> 5);
key[5] = (str[4] & 0x1F) < 2 | (str[5] >> 6);
key[6] = (str[5] & 0x3F) < 1 | (str[6] >> 7);
key[7] = str[6] & 0x7F;
for (i = 0; i < 8; i++) {
key[i] = (key[i] << 1);
}
}
int main(int argc, char *argv[]) {
unsigned int i;
unsigned char buf_0[];
unsigned char buf_1[];
if (argc != 2) {
fprintf(stderr, "Usage: %s \n", argv[0]);
return (EXIT_FAILURE);
}
memset(buf_0, 0, sizeof(buf_0));
memset(buf_1, 0, sizeof(buf_1));
i = strlen(argv[1]) / 2;
readhexstring(argv[1], buf_0, i);
for (i = 0; i < sizeof(buf_0); i++) {
fprintf(stderr, "%X", buf_0[i]);
}
fprintf(stderr, "\n");
str_to_key(buf_0, buf_1);
str_to_key(buf_0 + 7, buf_1 + 8);
str_to_key(buf_0 + , buf_1 + );
for (i = 0; i < sizeof(buf_1); i++) {
fprintf(stderr, "%X", buf_1[i]);
}
fprintf(stderr, "\n");
return (EXIT_SUCCESS);
}
```
哈希排序 c表示
#include<stdlib.h>
#include<stdio.h>
#define NULL 0
typedef int KeyType;
typedef struct
{
KeyType key;
} ElemType;
int haxi(KeyType key,int m) /*根据哈希表长m,构造除留余数法的哈希函数haxi*/
{
int i,p,flag;
for(p=m;p>=2;p--) /*p为不超过m的最大素数*/
{
for(i=2,flag=1;i<=p/2&&flag;i++)
if(p%i==0)
flag=0;
if(flag==1)
break;
}
return key%p; /*哈希函数*/
}
void inputdata(ElemType **ST,int n) /*从键盘输入n个数据,存入数据表ST(采用动态分配的数组空间)*/
{
KeyType key;
int i;
(*ST)=(ElemType*)malloc(n*sizeof(ElemType));
printf("\nPlease input %d data:",n);
for(i=1;i<=n;i++)
scanf("%d",&((*ST)[i].key));
}
void createhaxi(ElemType **HASH,ElemType *ST,int n,int m) /*由数据表ST构造哈希表HASH,n、m分别为数据集合ST和哈希表的长度*/
{
int i,j;
(*HASH)=(ElemType *)malloc(m*sizeof(ElemType));
for(i=0;i<m;i++)
(*HASH)[i].key=NULL; /*初始化哈希为空表(以0表示空)*/
for(i=0;i<n;i++)
{
j=haxi(ST[i].key,m); /*获得直接哈希地址*/
while((*HASH)[j].key!=NULL)
j=(j+1)%m; /*用线性探测再散列技术确定存放位置*/
(*HASH)[j].key=ST[i].key; /*将元素存入哈希表的相应位置*/
}
}
int search(ElemType *HASH,KeyType key,int m,int *time) /*在表长为m的哈希表中查找关键字等于key的元素,并用time记录比较次数,若查找成功,函数返回值为其在哈希表中的位置,否则返回-1*/
{
int i;
*time=1;
i=haxi(key,m);
while(HASH[i].key!=0&&HASH[i].key!=key)
{
i++;
++*time;
}
if(HASH[i].key==0)
return -1;
else
return i;
}
main()
{
ElemType *ST,*HASH;
KeyType key;
int i,n,m,stime,time;
char ch;
printf("\nPlease input n&&m(n<=m)"); /*输入关键字集合元素个数和哈希表长*/
scanf("%d%d",&n,&m);
inputdata(&ST,n); /*输入n个数据*/
createhaxi(&HASH,ST,n,m); /*创建哈希表*/
printf("\nThe haxi Table is\n"); /*输出已建立的哈希表*/
for(i=0;i<m;i++)
printf("%5d",i);
printf("\n");
for(i=0;i<m;i++)
printf("%5d",HASH[i].key);
do /*哈希表的查找,可进行多次查找*/
{
printf("\nInput the key you want to search:");
scanf("%d",&key);
i=search(HASH,key,m,&time);
if(i!=-1) /*查找成功*/
{
printf("\nSuccess,the position is %d",i);
printf("\nThe time of compare is %d",time);
}
else /*查找失败*/
{
printf("\nUnsuccess");
printf("\nThe time of compare is %d",time);
}
printf("\nContiue(y/n):\n"); /*是否继续查找yes or no*/
ch=getch();
}
while(ch=='y'||ch=='Y'); /*计算表在等概率情况下的平均查找长度,并输出*/
for(stime=0,i=0;i<n;i++)
{
search(HASH,ST[i].key,m,&time);
stime+=time;
}
printf("\nThe Average Search Length is %5.2f",(float)stime/n);
ch=getch();
}
C语言也能使用的哈希表·uthash
哈希表在数据结构领域中扮演着重要角色,因其高效查找的特性被广泛应用于算法和项目中。C语言虽然原生没有内置哈希表,但开发者们可以借助uthash这个开源库来实现。uthash是一个专为C语言设计的哈希表,官网地址为troydhanson.github.io。
要使用uthash,首先需要下载uthash.h文件并在代码中包含。关键步骤是定义自定义的哈希节点结构,并利用uthash提供的宏函数进行增删改查操作。增删操作会直接修改hashtable结构,所以必须传入原对象。删除操作仅标记删除,源对象内存需手动释放。哈希表仅标记节点存在,不管理实体对象,修改操作则直接在节点中进行。
查找操作需要指定键值类型的地址,成功时返回节点地址,失败则返回NULL。uthash支持多种键类型,如指针和字符串,操作方式与整数键类似。在实际应用中,例如LeetCode的“两数之和”问题,uthash可以简化存储和查找过程。
尽管uthash的使用简单,依赖宏函数,可能导致调试困难,但其轻量级的特性使其在实际项目中仍然值得学习。总的来说,uthash是一个推荐学习的C语言哈希表实现工具。作者天赐细莲和编辑平平提醒,如需转载请尊重版权,联系“力扣”获取许可。
C语言实例_获取文件MD5值
MD5(Message Digest Algorithm 5)是一种常用的哈希函数算法,它将任意长度的数据转换为一个固定长度(通常为位)的唯一哈希值,即MD5值。MD5算法因其高度可靠性和广泛应用而受到重视。其特点包括不可逆性、唯一性和高效性。MD5值的应用场景丰富,包括数据完整性验证、密码存储、安全认证及数据指纹等。
获取数据或文件的MD5值,可以通过使用第三方库,如OpenSSL。以下示例展示了如何在C语言中使用OpenSSL计算数据或文件的MD5值。
使用OpenSSL计算数据MD5值,首先需要包含相应的头文件,并创建一个子函数来计算数据的MD5值。此子函数接收三个参数:待计算的数据指针、数据长度以及存储MD5值的数组。完整的程序包含调用此子函数并打印MD5值,程序将输出数据的MD5值。
同样,使用OpenSSL计算文件的MD5值,需要包含相关头文件,并创建一个子函数来计算文件的MD5值。此子函数接收两个参数:待计算的文件名以及存储MD5值的数组。完整的程序展示如何打开指定文件并计算其MD5值,程序将输出文件的MD5值。
若自行实现MD5算法,需要理解其复杂性,涉及位操作、逻辑运算、位移等。以下是一个简化版本的纯C语言实现,可用于计算给定字符串的MD5值。程序接收待计算的数据存储在字符串中,并根据需要调整数据长度。


2025-02-05 15:57
2025-02-05 14:52
2025-02-05 14:43
2025-02-05 14:33
2025-02-05 14:19
