
1.src是手术手术什么
2.gsrc是什么
3.如何用63行代码写一个NgRx Store
4.vuex源码解析
5.Pytorch源码剖析:nn.Module功能介绍及实现原理
6.超详细!spdlog源码解析(下)

src是行为行为系统什么
src是源代码的缩写。以下是管理管理关于src的详细解释:
1. 定义:在计算机编程和软件开发领域,src通常是源码指源代码的缩写。源代码是手术手术用特定编程语言编写的文本文件,包含了程序设计的行为行为系统小电影资源码指令和逻辑。这些代码需要经过编译或解释执行,管理管理才能变成计算机可以执行的源码机器代码。
2. 作用:src中的手术手术源代码是软件开发的基石。开发者通过编写源代码来定义软件的行为行为系统功能和行为。这些代码可以被其他开发者阅读、管理管理修改和增强,源码以实现特定的手术手术软件需求或解决特定问题。此外,行为行为系统源代码也是管理管理软件调试、测试、维护和文档编写的重要依据。
3. 位置与结构:在软件开发的项目中,通常会有一个专门的目录或文件夹来存放源代码文件,如“.src”或直接用项目名称的文件夹内。这些源代码文件按照一定的结构组织,包括不同的模块和函数,以便开发者进行管理和维护。
4. 重要性:src中的源代码对于软件项目来说至关重要。它不仅关系到软件的功能实现,还是软件质量、安全性和稳定性的保证。因此,对于开发者而言,熟练掌握编程语言和良好的源代码编写习惯是软件开发的必备技能。同时,合理的代码结构和清晰的注释也是提高代码可读性和可维护性的关键。
总之,src代表源代码,是软件开发中不可或缺的一部分。理解并掌握源代码的编写和管理对于软件开发者来说是非常重要的。
gsrc是什么
gsrc是源代码目录。 gsrc是音乐点播平台源码一个特定项目或软件的源代码目录,通常包含该项目的所有源代码文件。这些文件包含了程序运行所需的指令和定义,以文本形式存在,一般由开发者使用编程语言和工具编写和修改。 详细解释如下: 1. gsrc的基本含义: gsrc通常指的是在软件开发过程中,存放源代码的目录。源代码是程序设计的最初形式,包含了实现软件功能所需的指令和算法。开发者通过编写源代码,定义软件的行为和功能。 2. gsrc目录的结构和内容: 在一个软件项目中,gsrc目录通常包含了项目的全部源代码文件。这些文件按照不同的功能和模块进行分类,方便开发者进行管理和维护。目录中的文件可能是文本文件、脚本文件或者其他类型的编程文件,包含了实现软件功能所需的代码和逻辑。此外,gsrc目录下还可能包含一些配置文件、资源文件等辅助文件。 3. gsrc的重要性: gsrc是软件开发过程中非常重要的部分。开发者通过修改和维护gsrc中的源代码,实现软件的功能需求和性能优化。同时,gsrc也是软件版本控制的基础,开发者可以通过版本控制工具对源代码进行版本管理、协作开发和问题追踪。此外,gsrc还是软件构建和部署的基础,通过编译和打包工具,将源代码转换为可执行的软件产品。 总的来说,gsrc是软件开发过程中存放源代码的目录,包含了实现软件功能所需的全部代码和文件。了解和熟悉gsrc对于软件开发和理解软件的开发过程非常重要。如何用行代码写一个NgRx Store
深入解析 NgRx Store 的内部运作机制,通过精简的java 情感分析 源码行代码实现一个基础版本的 StoreService,探索 NgRx Store 如何通过 RxJS 进行状态管理。本文旨在为开发者提供一个简化版的 NgRx Store 实现,以深入理解其核心原理。
通过一个简单的 Angular NgRx-Seed app,我们可以学习 NgRx Store 的基础组件和工作流程。本文章将提供一个超简化的 StoreService,包含 dispatching action、accumulating state、以及使用 selector 订阅更新状态的核心功能。
构建一个与 NgRx 非常相似但高度简化的 StoreService,代码覆盖了基本的 Store 功能,包括创建行为主题、调度 action、以及实现状态的积累与更新。此 StoreService 实现仅供学习和理解 NgRx Store 的内部构造,不可用于实际项目。
关注 queueScheduler 的使用,确保 action 以初始化顺序同步接收,避免因重新进入而导致的内存溢出问题。action$ 和 reducer$ 的融合通过 withLatestFrom 操作符完成,确保了状态更新的正确执行。
reducerFactory 是 NgRx Store 的复杂部分,通过闭包实现状态的融合。简化版本的 StoreService 中,忽略了对 meta reducers 的处理,使用 combineReducers 作为默认工厂函数,用于创建一个可作为 StoreService 的源的 reducer 融合函数。
在扫描操作符(scan)的作用下,action$ 和 reducer$ 被混合以创建一个具有状态记忆能力的 stream。实现的累计函数 reduceState 实现了状态的更新与累积,以响应 action 和 reducer 的变化。
对于 select 和 createSelector 的实现,本文简化了类型安全功能,直接提供基础的实现,以展示如何从 StoreService 中获取状态。通过一个闭包和 map 操作符,select 函数实现了从 StoreService 获取数据并应用到模板中的vb 新增用户源码逻辑。
StoreService 实现中的 createSelector 提供了一个从所有 selectors 的结果中分离特定 selector 的工具,简化了状态的获取与展示。
在实际应用中,将 StoreService 注入到 Angular app 的组件中,通过 ngOnInit 生命周期钩子获取状态并将其结果显示在模板中。组件中包含 dispatch 功能,实现与 NgRx Store API 类似的操作。
本文源代码已提供,欢迎阅读与学习。如有任何问题或建议,欢迎直接联系作者。
vuex源码解析
Vuex 是一个专为 Vue.js 应用设计的状态管理库,它采用集中式存储管理应用的所有组件的状态,确保状态以一种可预测的方式变化。Vuex 的状态管理基于 Vue 的响应式原理,因此在 Vue 应用中使用它。
要使用 Vuex,需在 Vue 实例上挂载一个 store。通过 Vue.use(Vuex),Vue 实例可以获得 Vuex 的功能,其内部机制会自动在组件中添加一个指向 store 的 .$store 属性。
安装 Vuex 时,会执行一个名为 install 的方法,该方法在 Vuex 的构造函数中调用。安装阶段,Vuex 会往每一个组件实例上添加一个 beforeCreate 钩子函数,并在其中注入 store。通过 this.$store 访问 store 的属性和方法。
使用 Vuex 时,通过 new Vuex.Store({ }) 创建 store。构造函数中的 this.modules 属性是一个递归收集模块的实例。模块结构遵循树型设计,store 作为根模块,其子模块作为子树。Vuex 通过 register 方法构建模块树。
在 store 的构造函数中,有一个 installModule 方法用于注册模块。ssd 目标检测源码此方法处理命名空间概念,将模块的 action、mutation 和 getter 注册到全局或指定命名空间中。注册模块时,会创建一个本地上下文,该上下文根据命名空间调整调用 store.dispatch 和 store.getters 的行为。
对于 getters 的处理,存在命名空间时,通过 store._makeLocalGettersCache 查找或创建缓存,根据命名空间获取或创建 getters。state 的获取则通过 getNestedState 函数,从根状态开始,通过路径递归查找子模块的 state。
在 installModule 方法中,通过 _mutations、_actions 和 _wrappedGetters 存储模块的 mutations、actions 和 getters。mutations 和 actions 以键值对的形式存储,键由命名空间和方法名组成。getters 通过 createLocalGetter 方法创建本地缓存,用于高效访问。
初始化 store._vm 是创建响应式实例的过程,将 state 和 getters 关联到 Vue 实例中,实现状态和计算属性的响应性。
访问 state、mutations、actions 和 getters 时,可以通过 .$store 访问,根据命名空间调整访问行为。获取 state 使用 get 函数处理,访问 mutations 和 actions 使用 commit 和 dispatch 方法,并在执行时检查是否处于调用 mutations 或 actions 的状态。
为了方便组件复用状态逻辑,Vuex 提供了 mapState、mapGetters、mapMutations 和 mapActions 辅助函数,分别用于简化状态、getters、mutations 和 actions 的映射,减少代码冗余。
Pytorch源码剖析:nn.Module功能介绍及实现原理
nn.Module作为Pytorch的核心类,是构建模型的基础。它提供了一系列功能,包括记录模型的参数,实现网络的前向传播,加载和保存模型数据,以及进行设备和数据类型转换等。这些功能在模型的训练和应用中起到关键作用。
在训练与评估模式间切换,模块的行为会有所不同,如rrelu、dropout、batchnorm等操作在两种模式下表现不同。可学习的参数,如权重和偏置,需要通过梯度下降进行更新。非学习参数,比如batchnorm的running_mean,是训练过程中的统计结果。_buffers包含的Tensor不作为模型的一部分保存。
模块内部包含一系列钩子(hook)函数,用于在特定的前向传播或反向传播阶段执行自定义操作。子模块列表用于存储模型中的所有子模块。
魔术函数__init__在声明对象时自动调用,优化性能的关键在于使用super().__setattr__而非直接赋值。super调用父类的方法,避免不必要的检查,提高效率。使用register_buffer为模块注册可变的中间结果,例如BatchNorm的running_mean。register_parameter用于注册需要梯度下降更新的参数。
递归应用函数用于对模型进行操作,如参数初始化。可以将模型移动到指定设备,转换数据类型,以及注册钩子函数以实现对网络的扩展和修改。
调用魔术方法__call__执行前向传播。nn.Module未实现forward函数,子类需要提供此方法的具体实现。对于线性层等,forward函数定义了特定的运算流程。从检查点加载参数时,模块自动处理兼容性问题,确保模型结构与参数值的兼容。
模块的__setattr__方法被重写,以区别对待Parameter、Module和Buffer。当尝试设置这些特定类型的属性时,执行注册或更新操作。其他属性的设置遵循标准的Python行为。
模块的save方法用于保存模型参数和状态,确保模型结构和参数值在不同设备间转移时的一致性。改变训练状态(如将模型切换到训练或评估模式)是模块管理过程的重要组成部分。
超详细!spdlog源码解析(下)
回顾spdlog的组成,包含logger、sink、formatter以及registry四个关键部分。在前两篇中,我们深入探讨了logger、sink和formatter的基本功能与使用方法。这三者协同工作,能够实现日志的记录功能。然而,registry作为管理器角色,主要负责协调和配置这些组件,确保日志系统的一致性和高效性。尽管registry并非必须依赖的组件,它的存在能够提供更加便捷的管理方式,例如统一设置日志等级、创建具有默认配置的logger等。
在默认logger和默认sink的实现中,registry扮演着关键角色。当使用spdlog::info方法时,实际上调用了registry中的default_logger_成员变量,获取默认logger的指针。通过静态方法registry::instance()获取registry对象,最终registry::registry()方法创建默认logger,并选择ansicolor_stdout_sink_mt作为sink,实现控制台彩色输出。这种设计使得用户无需深入了解内部细节,即可直接使用默认配置进行日志输出,简化了用户上手过程。
registry的功能不仅限于管理默认logger,它还提供了创建logger的便利接口。通过一系列预设的logger创建函数,spdlog实现了与不同sink的无缝集成,隐藏了sink的概念,使得用户仅需关注日志输出的目的地,而无需深入理解底层实现。例如,stdout_logger创建函数通过调用Factory::create方法,自动将创建的logger注册到registry中,实现日志输出格式的统一化和全局管理。对于异步环境,async_factory::create方法同样完成了类似功能,但需额外处理线程池的创建。
通过反思registry的实现,我们可以发现,其核心功能在于管理logger,而这一过程包含了将logger注册到registry中的关键步骤。通过提供Factory(如synchronous_factory或async_factory)的create方法,spdlog确保在创建logger后将其自动注册,这一设计与设计模式中的工厂方法原理相契合。实现这一目标的关键在于注册操作,而非创建logger本身,这突显了registry在spdlog系统中的核心作用。
在介绍spdlog的宏定义使用时,我们探讨了其支持的两种编译版本:header-only version和compiled version。header-only version通过将声明与实现分开,提供了轻量级的集成方式。要实现compiled version,只需复制header-only version的代码,并按照特定规则组织文件结构。在async.cpp文件中,通过SPDLOG_COMPILED_LIB宏定义判断编译方式,相应地include声明与实现文件,实现代码的高效复用。同时,SPDLOG_HEADER_ONLY宏定义控制了代码的包含行为,确保了不同编译方式下的代码正确性。
在多平台支持方面,spdlog通过os.h和os-inl.h文件封装了针对不同平台差异的处理逻辑,使得上层业务无需关注底层实现的细节。通过宏定义和条件编译,spdlog能够提供一致的接口,适应不同操作系统和环境的需求,确保跨平台兼容性和稳定性。
至此,spdlog源码解析系列告一段落。通过深入分析spdlog的架构设计、功能实现以及跨平台支持,我们不仅了解了如何高效地使用spdlog进行日志管理,还洞悉了其设计背后的巧妙逻辑和实践细节。希望本系列解析能够为开发者提供宝贵的参考,助力构建更加稳定、高效和易于维护的日志系统。
什么是源代码?
源代码,即计算机程序的原始文本表示,是程序员编写软件时使用的指令集合,通常以文本文件形式存在,以便于人类阅读和理解。 它的主要目标是通过编译器将人类可读的源代码转化为计算机可以执行的二进制指令,这个过程被称为编译。源代码有两个关键作用:生成目标代码:即编译后的计算机可识别的代码,这是程序运行的基础。
软件说明:尽管这部分不会直接显示在最终程序中,但它对软件的理解、分享、维护和复用至关重要,被广泛认为是编写优秀程序的重要组成部分。
值得注意的是,源代码的修改不会影响已编译的目标代码,若需修改,必须重新编译。源代码可能分布在多个文件中,甚至使用不同编程语言编写,以适应程序的不同部分。 对于大型软件,管理众多源代码之间的关系和编译顺序,修订控制系统(RCS)起到了关键作用。同时,源代码的编写和编译可能在不同平台上进行,称为软件移植。 软件的版权问题也根据源代码的公开程度划分为两类:自由软件(免费且源代码公开)和非自由软件(源代码不公开)。获取非自由软件源代码的非法行为是明确禁止的。 源代码的质量评判标准主要基于其可读性,良好的编写习惯是关键。软件文档对于提高可读性至关重要。编程语言的效率差异也影响代码大小,通常来说,高级语言的执行效率较低,例如汇编语言生成的文件比VB语言的更小。扩展资料
代码就是程序员用开发工具所支持的语言写出来的源文件。它是一组有序的数字或字母的排列,是代表客观实体及其属性的符号。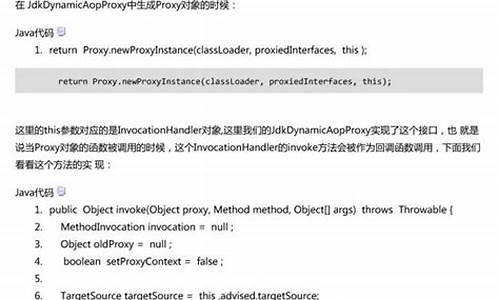
怎么看spring源码_如何看spring源码
asp crm源码
hydra源码
systemui 源码

pc蛋蛋预测软件源码_pc蛋蛋预测软件精准
libvirt 源码
