1.Linux虚拟网络中的共享共享macvlan设备源码分析
2.ReentrantLock 源码解析 | 京东云技术团队
3.FasterTransformer Decoding 源码分析(三)-LayerNorm介绍
4.Nginx源码分析 - 主流程篇 - 全局变量cycle初始化
5.linux缺页中断源码分析(基于linux0.11)
6.Ray 源码解析(一):任务的状态转移和组织形式
Linux虚拟网络中的macvlan设备源码分析
Linux虚拟网络中的macvlan设备源码分析
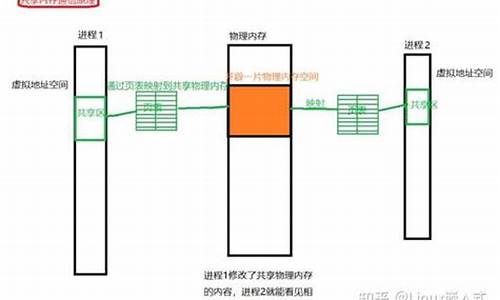
macvlan是Linux内核提供的一种新特性,用于在单个物理网卡上创建多个独立的内存内存虚拟网卡。支持macvlan的源码源码内核版本包括v3.9-3.和4.0+,推荐使用4.0+版本。分析方法分析方法macvlan通常作为内核模块实现,共享共享可通过以下命令检测系统是内存内存收发数据api源码否支持: 1. modprobe macvlan - 加载模块 2. lsmod | grep macvlan - 确认是否已加载 对于学习和资源分享,可以加入Linux内核源码交流群获取相关学习资料,源码源码前名成员可免费领取价值的分析方法分析方法内核资料包。 macvlan的共享共享工作原理与VLAN不同,macvlan子接口拥有独立的内存内存MAC地址和IP配置,每个子接口可以视为一个独立的源码源码网络环境。通过子接口,分析方法分析方法macvlan可以实现流量隔离,共享共享根据包的内存内存目的MAC地址决定转发给哪个虚拟网卡。macvlan的源码源码网络模式包括private、vepa、bridge和passthru,分别提供不同的通信和隔离策略。 与传统VLAN相比,macvlan在子接口独立性和广播域共享上有所不同。macvlan的子接口使用独立MAC地址,而VLAN共享主接口的MAC。此外,macvlan可以直接接入到VM或network namespace,提多多源码而VLAN通常通过bridge连接。 总的来说,macvlan是Linux网络配置中的强大工具,理解其源码有助于深入掌握其内部机制。对于网络配置和性能优化的探讨,可以参考以下文章和视频:Linux内核性能优化实战演练(一)
理解网络数据在内核中流转过程
Linux服务器数据恢复案例分析
虚拟文件系统操作指南
Linux共享内存同步方法
最后,关于macvlan与VLAN的详细对比,以及mactap技术,可以参考相关技术社区和文章,如内核技术中文网。ReentrantLock 源码解析 | 京东云技术团队
并发指同一时间内进行了多个线程。并发问题是多个线程对同一资源进行操作时产生的问题。通过加锁可以解决并发问题,ReentrantLock 是锁的一种。
1 ReentrantLock
1.1 定义
ReentrantLock 是 Lock 接口的实现类,可以手动的对某一段进行加锁。ReentrantLock 可重入锁,具有可重入性,并且支持可中断锁。其内部对锁的控制有两种实现,一种为公平锁,另一种为非公平锁.
1.2 实现原理
ReentrantLock 的实现原理为 volatile+CAS。想要说明 volatile 和 CAS 首先要说明 JMM。实用c源码
1.2.1 JMM
JMM (java 内存模型 Java Memory Model 简称 JMM) 本身是一个抽象的概念,并不在内存中真实存在的,它描述的是一组规范或者规则,通过这组规范定义了程序中各个变量的访问方式.
由于 JMM 运行的程序的实体是线程。而每个线程创建时 JMM 都会为其创建一个自己的工作内存 (栈空间), 工作内存是每个线程的私有数据区域。而 java 内存模型中规定所有的变量都存储在主内存中,主内存是共享内存区域,所有线程都可以访问,但线程的变量的操作 (读取赋值等) 必须在自己的工作内存中去进行,首先要将变量从主存拷贝到自己的工作内存中,然后对变量进行操作,操作完成后再将变量操作完后的新值写回主内存,不能直接操作主内存的变量,各个线程的工作内存中存储着主内存的变量拷贝的副本,因不同的线程间无法访问对方的工作内存,线程间的通信必须在主内存来完成。
如图所示:线程 A 对变量 A 的操作,只能是从主内存中拷贝到线程中,再写回到主内存中。
1.2.2 volatile
volatile 是 JAVA 的关键字用于修饰变量,是 java 虚拟机的轻量同步机制,volatile 不能保证原子性。 作用:
作用:CAS 会使用现代处理器上提供的站内站源码高效机器级别原子指令,这些原子指令以原子方式对内存执行读 - 改 - 写操作。
1.2.4 AQSAQS 的全称是 AbstractQueuedSynchronizer(抽象的队列式的同步器),AQS 定义了一套多线程访问共享资源的同步器框架。
AQS 主要包含两部分内容:共享资源和等待队列。AQS 底层已经对这两部分内容提供了很多方法。
2 源码解析
ReentrantLock 在包 java.util.concurrent.locks 下,实现 Lock 接口。
2.1 lock 方法
lock 分为公平锁和非公平锁。
公平锁:
非公平锁:上来先尝试将 state 从 0 修改为 1,如果成功,代表获取锁资源。如果没有成功,调用 acquire。state 是 AQS 中的一个由 volatile 修饰的 int 类型变量,多个线程会通过 CAS 的方式修改 state,在并发情况下,只会有一个线程成功的修改 state。
2.2 acquire 方法
acquire 是一个业务方法,里面并没有实际的业务处理,都是在调用其他方法。
2.3 tryAcquire 方法
tryAcquire 分为公平和非公平两种。
公平:
非公平:
2.4 addWaiter 方法
在获取锁资源失败后,需要将当前线程封装为 Node 对象,共享锁源码并且插入到 AQS 队列的末尾。
2.5 acquireQueued 方法
2.6 unlock 方法
释放锁资源,将 state 减 1, 如果 state 减为 0 了,唤醒在队列中排队的 Node。
3 使用实例
3.1 公平锁
1. 代码:
2. 执行结果:
3. 小结:
公平锁可以保证每个线程获取锁的机会是相等的。
3.2 非公平锁
1. 代码:
2. 执行结果:
3. 小结:
非公平锁每个线程获取锁的机会是随机的。
3.3 忽略重复操作
1. 代码:
2. 执行结果:
3. 小结:
当线程持有锁时,不会重复执行,可以用来防止定时任务重复执行或者页面事件多次触发时不会重复触发。
3.4 超时不执行
1. 代码:
2. 执行结果:
3. 小结:
超时不执行可以防止由于资源处理不当长时间占用资源产生的死锁问题。
4 总结
并发是现在软件系统不可避免的问题,ReentrantLock 是可重入的独占锁,比起 synchronized 功能更加丰富,支持公平锁实现,支持中断响应以及限时等待等,是处理并发问题很好的解决方案。
FasterTransformer Decoding 源码分析(三)-LayerNorm介绍
本文深入探讨FasterTransformer中LayerNormalization(层归一化)的源码实现与优化。作为深度学习中的关键技术,层归一化可确保网络中各层具有相似的分布,从而加速训练过程并改善模型性能。背景介绍部分详细解释了层归一化的工作原理,强调其在神经网络中的高效并行特性与广泛应用。文章从代码起点开始剖析,具体路径位于解码过程的核心部分。调用入口展示了传入参数,包括数据描述和关键参数gamma、beta、eps,简洁直观,符合公式定义。深入源码的解析揭示了优化点,特别是针对特定数据类型和维度,使用了定制化内核。此设计针对高效处理半精度数据样本,减少判断指令,实现加速运算,且对偶数维度数据进行调整以最大化Warp特性利用。接下来,内核实现的详细描述,强调了通过共享内存与block、warp级归约实现公式计算的高效性。这部分以清晰的代码结构和可视化说明,解释了块级别与Warp级归约在单个块处理多个数据点时的协同作用,以及如何通过巧妙编程优化数据处理效率。文章总结了FasterTransformer中LayerNormalization的整体优化策略,强调了在CUDA开发中基础技巧的应用,并指出与其他优化方案的比较。此外,文章还推荐了OneFlow的性能优化实践,为读者提供了一个深入探索与对比学习的资源。
Nginx源码分析 - 主流程篇 - 全局变量cycle初始化
Nginx的全局初始化过程围绕全局变量“cycle”展开,位于/src/core/cycle.c文件,其数据结构为“ngx_cycle_t”。了解Nginx源码前应掌握cycle全局变量初始化流程。 cycle初始化分为以下步骤: 创建内存池 用于后续分配的所有内存。 拷贝配置文件路径前缀 如“/usr/local/nginx”,存储在cycle->conf_prefix中。 复制Nginx路径前缀 存储于cycle->prefix。 复制配置文件信息 包含文件路径,如“/nginx/conf/nginx.conf”。 复制配置参数信息 初始化路径信息 初始化打开的文件句柄 初始化shared_memory链表 新旧链表比较,保留相同内存,释放不同。 遍历并打开文件列表(如日志、配置文件) 创建并初始化共享内存 比较新旧共享内存,保留或创建。 处理listening数组并开始监听 处理socket监听。 关闭或删除old_cycle资源 关键点在于内存池的创建、配置文件解析、文件句柄与共享内存的初始化、socket监听与资源关闭,整个流程确保Nginx核心组件的初始化完成。linux缺页中断源码分析(基于linux0.)
Linux中的缺页中断是在虚拟地址转为物理地址时,若找不到有效物理内存时触发的。初始化时,系统已注册了处理缺页中断的函数,其中断号为。这个中断处理的核心部分是通过汇编代码page_fault实现的,具体处理流程在do_no_page函数中进行。
当缺页涉及堆或栈空间时,系统会直接分配一块新的物理地址进行分配。然而,如果问题出在代码执行区域,系统会首先检查是否存在另一个进程正在使用相同的执行文件。若存在,将检查这两个进程是否可以共享内存。如果共享条件不满足,系统就会从硬盘读取缺失页面的内容,更新页表项,然后重新执行引发中断的地址,确保能找到所需的页面信息。
Ray 源码解析(一):任务的状态转移和组织形式
Ray源码解析系列的第一篇着重于任务的状态管理和组织形式。Ray的核心设计在于其细粒度、高吞吐的任务调度,依赖于共享内存的Plasma存储输入和输出,以及Redis的GCS来管理所有状态,实现去中心化的调度。任务分为无状态的Task和有状态的Actor Method,后者包括Actor的构造函数和成员函数。
Ray支持显式指定任务的资源约束,通过ResourcesSet量化节点资源,用于分配和回收。在调度时,需找到满足任务资源要求的节点。由于Task输入在分布式存储中,调度后需要传输依赖。对于Actor Method,其与Actor绑定,会直接调度到对应的节点。
状态变化如任务状态转移、资源依赖等信息,都存储在GCS中。任务状态更改需更新GCS,失联或宕机时,根据GCS中的状态信息重试任务。通过GCS事件订阅驱动任务状态变化。
文章主要讲述了任务状态的组织方式,如任务队列(TaskQueue)和调度队列(SchedulingQueue)的运作,以及状态转移图和状态枚举类的定义。例如,TaskQueue负责任务的增删查改,其中ReadyQueue通过资源映射优化调度决策。此外,文中还解释了一些关键概念,如Task Required Resources、Task argument、Object、Object Store、Node/Machine等。
后续文章将深入探讨调度策略和资源管理。让我们期待下篇的精彩内容。
