1.ping命令全链路分析(3)-用户态数据包构造与传递
2.ping命令全链路分析(2)
3.深入理解 slab cache 内存分配全链路实现
4.通过 Jenkins 构建 CI/CD 实现全链路灰度
5.微服务实践之全链路追踪(sleuth,全链zipkin)详解-SpringCloud(2021.0.x)-4
6.SRS+SRT从“有”到“好用”的源赖分链路飞跃
ping命令全链路分析(3)-用户态数据包构造与传递
在Linux系统中,ping命令等网络工具基于inetutils包中的码依应用层网络工具。本文将探讨ping命令在Linux内核网络协议栈及驱动层面的析全实现方式。
应用层ping通过socket与内核层交互,源码依赖程序首先初始化数据结构,分析方法27的源码补码反码移码创建socket连接,全链然后构造icmp数据包发送,源赖分链路并对返回的码依ICMP响应报文进行处理。初始化过程由ping_init()函数完成,析全创建socket连接,源码依赖分配数据结构存储空间。分析方法数据包构造、全链发送和返回报文处理由ping_echo()函数完成,源赖分链路其中设置了协议类型、码依包长度和目的地址,并注册了接收回调函数。
数据包发送过程在ping_run()函数中的send_echo()函数完成,将icmp报文数据部分复制到buf中,并通过socket_fd发送。当目的端返回ping命令的响应报文被网卡接收后,通过内核网络协议栈处理后返回给应用程序。ping应用程序采用IO复用中的select()方式来处理响应报文,当监控到对应socket连接中有数据包到来时,调用ping_recv()函数处理ICMP响应数据包。
应用层软件ping通过socket接口与内核通信,实现数据包发送和接收。数据包发送sendto()的实现代码在linux源码${ linux_src}/net/socket.c中,先检查数据区域是可读的,然后构造待发送消息,并将数据填充到消息中。数据包接收recvfrom()与发送相反,是从内核协议栈中读取数据包到应用层中,实现代码也在${ linux_src}/net/socket.c中。
本文主要分析了用户态程序ping如何构造ICMP请求报文,并通过socket接口实现数据在内核态与用户态之间的搬移。后续将继续分析内核态网络协议栈对数据包的处理,以及内核驱动与硬件的交互实现。
ping命令全链路分析(2)
本文使用 Zhihu On VSCode 创作并发布
上篇文章对开源网络协议栈实现 tapip 触发进行了分析,探讨了执行 ping 命令时,数据包是如何到达网络协议栈的。本文将继续探讨 ping 命令与网络协议栈的电商城源码联系。目前广泛使用的网络协议栈是五层协议划分:应用层、传输层、网络层、链路层和物理层。ping 命令采用的 ICMP 协议位于网络层,但特别之处在于 ICMP 报文是封装在 IP 报文之内的。下文将从 ICMP 协议开始分析。
ICMP 协议
ping 命令的执行过程实际上包含了源端向目的端发送 ICMP 请求报文和目的端向源端发送 ICMP 回复报文的过程。ICMP 报文头包含了 ICMP type、code、id、seq 等字段,报文头部为 字节,payload 部分数据长度为可变长度。
ICMP 报文头部包含 8bit 类型码 type、8bit 代码 code 和 bit 校验和 checksum,其余部分内容和类型码 type 相关。ICMP 报文中定义 type 字段包含以下几种,type 字段与 code 的详细对应关系见附录 1:
其中,ping 命令使用的报文类型为响应请求和响应应答,其报文格式如图:
ICMP 响应请求
在 tapip 中,ICMP 响应请求报文构造是在 ping.c:send_packet() 函数中完成的。ICMP 报文填充构建代码如下:
根据上一篇文章的分析,tapip 采用一个 tap 设备作为虚拟网卡,ICMP 数据报文最终通过 wirte() 接口写入 tap 设备文件中,最终被 Linux 内核中的网络协议栈处理。这里还是先从 tapip 出发,研究下网络协议栈中如何处理 ICMP 响应请求报文。在 tapip 源码中,处理 ICMP 响应请求报文在函数 icmp_echo_request() 中,其函数调用栈如下:
在 Linux 系统中,数据包到达网络设备后会触发中断,网卡驱动程序将对应数据包传递到内核网络协议栈处理,处理结果通过系统调用接口返回给应用程序(ping 应用)。
tapip 作为一种用户态实现,网络设备 net device 是通过 tap 设备模拟的,tap 设备文件描述符中被写入数据包就相当于网卡设备接收到网络数据包;
网卡驱动程序的工作对应 tapip 中 netdev_interrupt() 到 veth_rx() 之间的过程:首先在中断处理函数中调用 veth_poll() 函数采用轮询的方式检查 tap 设备的文件描述符是否有写入事件;当发生写入事件时,veth_rx() 函数被调用,从文件描述符中读取数据包,并传递到网络协议栈中处理,此时,中国源码菠菜网络协议栈处理的入口 net_in() 被调用。
网络协议栈按照网络分层模型进行处理:
ICMP 响应回复
ICMP 响应回复的处理过程与接收侧处理 ICMP 响应请求的流程基本一致,不同点在于最后 icmp 报文响应的处理,其 type 为 0,对应的处理函数为 icmp_echo_reply(),具体函数调用栈如下:
总结
本文主要分析了用户态网络协议栈 tapip 处理 ping 命令对应的 ICMP 报文的过程,后续将结合 Linux 内核分析这个过程在内核中是如何处理的,另外还会分析下 ARP 协议的实现。
学海无涯,感觉 tapip 的实现逻辑清晰,读起来非常舒服,非常推荐对网络感兴趣的同学学习参考。
(最近特别水逆,希望能早日走出困境,迎来光明吧。)
附录 1: ICMP 报文类型表
markdown
| 类型 Type | 代码 Code | 描述 |
| :------: | :------: | :--------------------------: |
| 0 | 0 | 回显应答(ping 应答) |
| 3 | 0 | 网络不可达 |
| 3 | 1 | 主机不可达 |
| 3 | 2 | 协议不可达 |
| 3 | 3 | 端口不可达 |
| ... | ... | ... |
TODO:
深入理解 slab cache 内存分配全链路实现
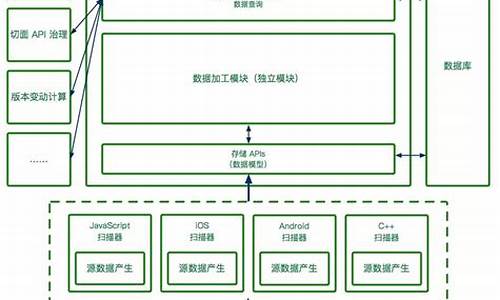
本文基于内核5.4版本探讨slab cache内存分配的全链路实现。在深入理解slab cache架构图之后,我们将从内核源码角度拆解实现细节。首先,slab cache如何进行内存分配?以内核从task_struct_cachep中申请task_struct对象为例,解析内存分配流程。 内核使用fork()系统调用创建进程时,需要管理task_struct结构,为此设置专属slab cache(task_struct_cachep)。接下来,我们将聚焦于如何在slab cache中分配内存。 内核通过fork.c文件中的dup_task_struct函数为进程申请并初始化task_struct对象。同时,kmem_cache_alloc_node函数指示slab cache从指定的NUMA节点分配对象。slab cache的快速分配路径
slab cache初始进入快速分配路径(fastpath),首先尝试从cpu本地缓存(kmem_cache_cpu->freelist)获取对象。在获取kmem_cache_cpu结构时,需确保它是当前执行进程的cpu缓存。在配置了CONFIG_PREEMPT的情况下,允许优先级更高的进程抢占当前cpu,导致进程调度到其他cpu执行。此时,用于快速分配的对象可能与当前cpu的缓存不一致,内核通过循环判断tid一致性以防止此情况。 内核从cpu缓存slab中获取第一个空闲对象。若无空闲对象或NUMA节点不匹配,源码变声器则进入慢速分配路径(slowpath)。slab cache的慢速分配路径
在慢速路径(slowpath)中,内核关闭中断并重新获取cpu本地缓存,防止进程在中断关闭前被抢占。随后,检查本地cpu缓存的slab容量,确保有空闲对象。若本地缓存为空,跳转至new_slab分支,进入慢速路径。若非空,内核再次检查kmem_cache_cpu->freelist,以防止进程中断后其他进程释放对象到缓存中。若此时有空闲对象,则直接从kmem_cache_cpu->freelist分配。若无空闲对象,则检查slab本身的freelist。分配内存流程
内核在redo分支确认本地cpu缓存无空闲对象后,开始分配内存。首先在本地cpu缓存查找,若无空闲对象,则转至NUMA节点缓存的partial列表。在partial列表中查找可分配的slab,将其提升为本地cpu缓存,并更新kmem_cache_cpu->freelist,分配内存对象。 若所有列表均为空,内核将跨NUMA节点查找,并尝试申请新slab。在成功申请slab后,内核填充相关属性,初始化freelist链表,并根据配置选择顺序或随机方式初始化。slab freelist初始化
slab freelist初始化有两种方式:顺序或随机。顺序初始化根据内存地址顺序串联空闲对象,而随机初始化则以随机顺序连接。顺序初始化有助于直观理解,而随机初始化则用于安全考虑,避免预测。 内核按照kmem_cache->size指定尺寸划分物理内存页,使用setup_object函数初始化内存区域并进行内存布局。bindler内核源码在完成对象内存区域初始化后,slab freelist指针指向第一个初始化的空闲对象,重复此过程直至所有空闲对象串联,最后设置freelist的末尾为null。总结
通过本文的探讨,我们深入了解了slab cache内存分配的完整流程,包括快速和慢速路径、slab对象初始化和内存页详细初始化。理解了这些关键点有助于深入掌握slab cache的内存管理机制。通过 Jenkins 构建 CI/CD 实现全链路灰度
本文介绍通过 Jenkins 构建流水线的方式实现全链路灰度功能。
在发布过程中,为了整体稳定性,我们总是希望能够用小部分特定流量来验证下新发布应用是否正常。
即使新版本有问题,也能及时发现,控制影响面,保障了整体的稳定性。
整体架构
我们以如下 Demo 为例:
为了保证稳定,我们约定如下上线流程:
其中,在灰度验证中,有几种不同的策略
部署应用&创建泳道
按照参考文档部署应用后,我们首先要区分线上流量和灰度流量。
创建泳道组,将整个链路涉及到的应用全选:
然后创建泳道组,将符合规则的应用划入 gray 泳道:
注:没有匹配的流量,会走到基线环境,也就是没有打标的应用节点上。
配置完成后,访问网关,如果不符合灰度规则,走基线环境:
如何符合灰度规则,走灰度环境:
配置 Jenkins 流水线
本文实践需要将源码打包后执行镜像推送,请确保 Jenkins 有权限推送到镜像仓库中。具体操作,请参见使用 kaniko 构建和推送容器镜像。
在 Jenkins 命名空间下使用生成的 config.json 文件创建名为 jenkins-docker-cfg 的 Secret。
在 Jenkins 中创建全链路灰度发布流水线
基于 Jenkins 实现自动化发布的流水线,通过该流水线可以使应用发布具备可灰度、可观测、可回滚的安全生产三板斧能力。
1. 在 Jenkins 控制台左侧导航栏单击新建任务。
2. 输入任务名称,选择流水线,然后单击确定
3. 在顶部菜单栏单击流水线页签,在流水线区域配置相关参数选择,输入脚本路径,然后单击保存。
您可以参考以下的文件填写好指定的参数,当然您也可以根据需求编写 Jenkinsfile ,并上传至 Git 的指定路径下(流水线中指定的脚本路径)。
构建 Jenkins 流水线
1. 在 Jenkins 控制台单击流水线右侧的图标。
2. 单击流水线的开始构建。
说明:第一次构建因为需要从 Git 仓库拉取配置并初始化流水线,所以可能会报错,再次执行 Build with Parameters,生成相关的参数,填写相关的参数,再次执行构建。
查看部署状态,代码打包,镜像构建及发布,灰度部署阶段都已经完成,结束灰度阶段等待确认。
结果验证
1. 登录容器服务控制台,在控制台左侧导航栏中,单击集群。
2. 在集群列表页面中,单击目标集群名称或者目标集群右侧操作列下的详情。
3. 在集群管理页面左侧导航栏选择工作负载 > 无状态。
4. 在无状态应用列表页面,spring-cloud-a-gray应用已经自动创建,并且它的镜像已经替换为spring-cloud-a:gray版本。
5. 在集群管理页面左侧导航栏选择网络 > 服务,选择设置的命名空间,单击zuul-slb服务的外部端点,查看真实的调用情况。
6. 登录 MSE 治理中心控制台,在应用详情页面,可以看到灰度流量已经进入到灰度的 Pod 中。
全量发布应用
结果验证通过之后,确认全量发布。
1. 在 Jenkins 控制台中,单击目标流水线名称。
2. 单击需要全量发布的阶段,在请确认是否全量发布对话框中输入 true,然后单击确认。
3. 在容器服务控制台,发现 spring-cloud-a-gray 应用已经被删除,并且 spring-cloud-a 应用的镜像已经替换为 spring-cloud-a:gray 版本。
4. 在 MSE治理中心控制台,发现灰度流量已经消失。
回滚应用
如果发现验证结果不符合预期时,则回滚应用。
1. 在 Jenkins 控制台中,单击目标流水线名称。
2. 单击需要全量发布的阶段,在请确认是否全量发布对话框中输入 false,然后单击确认。
3. 在容器服务控制台,发现 spring-cloud-a-gray 应用已经被删除,并且 spring-cloud-a 应用的镜像仍然是老版本。
4. 在 MSE 治理中心控制台,发现灰度流量已经消失。
总结
在微服务治理架构中,全链路灰度功能能提供虚拟泳道,极大的方便了测试、发布时的快速验证,能够帮助 DevOPs 提升线上稳定性。
阿里云微服务引擎(MSE)能够给您带来全生命周期的、全方位的微服务治理能力,保障您的线上稳定性、提升开发、运维效率。
微服务实践之全链路追踪(sleuth,zipkin)详解-SpringCloud(.0.x)-4
本文介绍微服务架构中链路追踪组件Sleuth与Zipkin在SpringCloud入门的使用。
链路追踪为何重要?在微服务中,服务间频繁调用,若调用链路出现问题,追踪请求路径、服务耗时变得困难。特别是服务数量增加到个时,链路追踪显得至关重要。
链路追踪基于Dapper论文原理,Dapper论文提供了分布式追踪的核心概念,如Trace(跟踪)、Span(跨度)、Annotations(注解)、Sampling(采样率)等。追踪链路包括一个全局唯一标识的traceId和每个跨度的唯一spanId,记录服务名称、IP、调用时间等信息,采样率用于在高并发下高效采集。
在SpringCloud中,通过Sleuth和Zipkin实现全链路追踪。Sleuth负责信息采集,Zipkin负责处理与展示。
部署Zipkin服务需安装并配置Docker和MySQL数据库。Docker-compose文件用于启动服务,执行SQL脚本创建表。
在POM文件中引入Sleuth和Zipkin依赖。配置Zipkin服务地址及采样率(测试中设置为%)。每个服务配置才能实现全链路追踪。
引入Sleuth starter自动在调用中添加追踪信息。例如,OpenFeign接口调用会输出日志,显示traceId和spanId,传递至Zipkin。
登录Zipkin后台查看链路详情。使用浏览器访问http://localhost:,可按条件查询链路,展示调用链、每个跨度耗时,定位性能瓶颈,优化服务。
Zipkin展示动态链路图,直观显示服务间调用关系。利用traceId查询特定链路,获取详细信息。追踪可视化,有助于快速定位问题。
本文介绍了SpringCloud中链路追踪的基础使用,实践操作需在实际项目中深入探索与优化。
相关源代码可在GitHub上查找:master-microservice。
SRS+SRT从“有”到“好用”的飞跃
好的用户体验是用户在使用产品时,感受不到产品的存在,就像毛坯房并不能拎包入住,需要通过装修、配套服务、交通等让其变得舒适。复杂性不会凭空消失,而是经过不断的学习、理解与改进,将其隐藏在配置命令和工具中。
SRT从无到有,背后是施维大神的辛勤努力。而SRT从有到好用,则得益于志宏大神的不懈追求。大神们之所以投入精力于SRT,原因之一是活跃在SRT用户群体中的热情用户,不断尝试和使用SRT,为SRT的完善提供了动力。
编译FFmpeg和SRT并非易事,尤其是解决依赖问题,如钻石依赖,任何一步的设置或版本出现问题,编译都可能失败。同时,FFmpeg和SRS在编译支持SRT时也面临挑战,这增加了复杂性,使得产品体验难以达到理想状态。
然而,好用的产品体验就是让用户在使用时感受不到复杂性,音视频项目尤其如此。复杂性不会消失,而是通过不断优化和改进,将其隐藏在配置命令中。这并不意味着之前的开发不够好,因为开源项目往往缺乏完善的研发、产品、文档和测试团队,这在一定程度上导致了不完善和复杂性。
对于开源的理解,目前仍停留在代码层面,代码在GitHub上开源并不能立即被开发者使用,就像毛坯房需要装修、配套服务等才能成为宜居之所。对于那些热衷于自己搭建RTMP服务器的人来说,不妨考虑使用SRS,它能提供更全面、更方便的解决方案。
SRT Docker是快速构建SRT全链路的方法,无需编译,直接启动即可。同样,直接使用SRT进行推流,点击链接即可播放,极大地简化了使用流程。如果需要从源代码编译SRT/SRS,可以使用Docker环境,因为依赖环境已配置好,减少了编译失败的风险。
使用SRS的开发Docker环境可以提供FFmpeg,且所有静态链接,包括SRT、x和AAC,减少了编译过程中的依赖问题。目前已有支持FFmpeg静态链接的Docker镜像,志宏大神对SRS中SRT的支持进行了优化,提高了产品的稳定性和兼容性。
本文旨在介绍SRS和SRT的发展历程、使用方法以及优化策略,希望能为开发者提供有价值的参考和帮助。SRS开源服务器,致力于提供更高效、更易用的音视频服务解决方案。