1.遥感影像超分技术
2.多模态AE、VAE、VQVAE、VQGAN原理解读
3.人脸清晰化神器codeFormer图形界面包
4.详解VQGAN(一)| 结合离散化编码与Transformer的百万像素图像生成
5.谷歌再次发布文字生成图像模型,新系统Parti根据文本输出各种风格、更高质量图像
6.资源CodeFormer最强AI去码修复神器!买卖极品指标源码
遥感影像超分技术
高分辨率遥感影像对于算法研发与精细化应用至关重要,却因高昂成本成为限制。AI Earth平台推出的影像超分辨率功能,通过提升低分辨率遥感影像的分辨率,有效降低了数据成本,提升了低分辨率影像的应用价值。此功能适用于Sentinel-2影像与2m分辨率影像。
影像超分辨率的核心原理在于,通过提高低分辨率遥感影像的空间分辨率,以增强其细节信息与应用潜力。以哨兵2和高分2影像为例,对比参数如分辨率等信息,可以明显观察到超分辨率处理后,影像的空间分辨率得到显著提升。
超分辨率技术面临的首要挑战在于,低分辨率遥感影像中细节缺失,传统的单图超分方法难以达到理想效果。此外,由于缺乏LR与HR训练数据对,构建有效的训练数据集成为关键。为此,我们构建了一个大规模的遥感影像数据集,包含m vs. 0.8m的数据对,用于训练超分模型,将m分辨率的影像提升至0.8m分辨率。
基于深度学习的超分技术方案包括构建训练数据集、设计超分模型及验证实验效果。训练数据集的构建是基于m vs. 0.8m数据对,通过VQGAN学习高分辨率影像的高频纹理信息,并量化为code book。超分模型的第二阶段,则利用code book作为side information,对低分影像进行高频细节的恢复。实验结果表明,超分影像的空间分辨率显著提升,接近真实高分辨率影像的可视化效果。
除了超分辨率技术,图像融合也是jquery+网站+源码遥感影像处理中的重要手段。图像融合技术将低分辨率的多光谱影像与高分辨率单波段影像重采样生成高分辨率多光谱影像,以实现空间分辨率与多光谱特征的综合。融合方法包括HSV融合、Brovey融合与PCA变换等,每种方法都有其适用场景与优缺点。
遥感影像超分与遥感影像融合是遥感影像处理领域的两大技术,两者在目标与处理方法上存在差异。超分技术旨在通过提高分辨率提升影像的细节与应用价值,而融合技术则是利用不同波段或分辨率的数据优势,提高影像质量与应用效益。超分技术主要采用图像插值与深度学习方法,而融合技术则分为像素级、特征级与决策级融合。
遥感影像超分应用验证通过建筑物提取与道路提取两个任务进行。在超分重建后的影像上,AI模型成功提取目标,验证了超分影像的有效性。超分影像与真实高分辨率影像在提取结果上接近,证明了该技术在实际应用中的可行性。
影像超分辨率使用步骤包括:登录AI Earth平台,选择影像超分辨率功能,设定任务与导入数据,处理完成后查看或下载结果。影像超分辨率效果展示包括2m分辨率影像与Sentinel-2影像的对比,直观展示了超分辨率技术带来的分辨率提升与应用价值。
多模态AE、VAE、VQVAE、VQGAN原理解读
了解生成模型,需从自编码器(AE)、变分自编码器(VAE)、维奎维自编码器(VQ-VAE)、维奎自生成对抗网络(VQ-GAN)等模型出发。这些模型各有特点,本文将分别解析。
一、自编码器(AE)
AE由编码器与解码器组成,将输入图像映射为低维特征(隐变量),旨在压缩输入数据。隐变量的生成与解码器的图像还原能力使得隐变量承载了输入的重要信息,利于下游任务。然而,AE的php+简单+源码隐变量缺乏语义特性,且无随机性。AE主要功能为数据压缩而非生成,模型训练过程中更偏向数据压缩过程。
二、变分自编码器(VAE)
VAE引入了变分推断,通过正态分布建模隐变量,引入采样步骤并确保隐变量分布与标准正态分布相近。VAE的loss包含两个部分:重建损失与KL散度,旨在平衡输出与输入的相似性,以及隐变量分布的正态化。重参数技巧在采样步骤中引入梯度计算,支持反向传播更新模型参数。
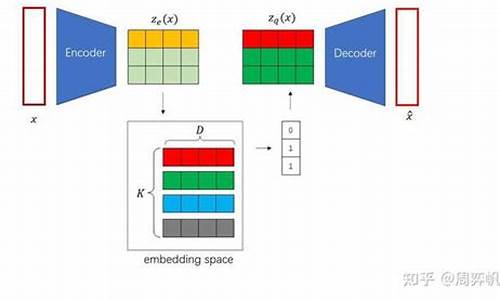
三、维奎维自编码器(VQ-VAE)
VQ-VAE首次采用码本机制,将图像编码为离散矩阵,为图像生成类任务提供了新思路。其模型结构包括编码器、解码器与码本,编码器输出编码向量,解码器将离散编码转换回图像。VQ-VAE通过最近邻搜索将连续编码映射为码本中的向量索引,实现离散化编码。训练VQ-VAE时,编码器与码本同时优化,利用Straight-Through Estimator处理编码过程中的argmin操作,保证梯度的计算。
四、维奎自生成对抗网络(VQ-GAN)
VQ-GAN结合了VQ-VAE与生成对抗网络(GAN)的思想,使用Transformer作为生成器替代VQ-VAE中的PixelCNN,同时加入基于图块的判别器以实现对抗训练。VQ-GAN的loss包含重建损失与GAN损失,旨在平衡图像的重建质量与生成质量。训练过程中,VQ-GAN通过对抗损失引导模型生成更高质量的图像,同时保持与真实图像的相似性。
综上所述,自编码器、变分自编码器、维奎维自编码器与维奎自生成对抗网络分别在数据压缩、生成与生成质量提升方面展示了各自的优势与特点。这些模型在图像生成、文本生成等任务中展现出了强大的能力,是融资融券源码php当前深度学习领域中的重要研究对象。
人脸清晰化神器codeFormer图形界面包
codeFormer 是一种在 NeurIPS 上提出的基于 VQGAN+Transformer 的人脸复原模型。它在效果上表现出色,能够显著提升人脸图像的清晰度。以下为 codeFormer 的效果展示,所用为官方案例中的图像示例。 欲深入探索 codeFormer,您可以访问官方提供的代码链接。然而,对于新手用户而言,代码的复杂性可能构成挑战。为解决这一问题,一个图形化界面包已应运而生。这个包整合了所有所需的 Python 环境,无需用户自行安装,使 codeFormer 的使用变得更为便捷。 以下是图形化界面包的功能亮点:对于已使用 DeepFaceLab 切好的对齐图像进行强化,并直接整合至 DeepFaceLab 的现有数据,无需重复切图操作。强化后的图像可直接用于后续训练。
调整 codeFormer 默认的尺寸放大倍数为 1 倍,避免与已对齐图像尺寸不匹配的问题。
将强化后的对齐人脸图像与整个图像分别归类于不同的标签页中,便于新手用户理解和操作。
在进行实际测试后,我们对三种用于人脸清晰化的算法:codeFormer、GPEN 和 GFPGAN 进行了比较。使用新垣结衣的图像作为测试样本,我们对正面、小侧面以及大侧面三种情况进行了测试。在正面情况下,codeFormer(简称 CF)表现最佳,既清晰又自然,保留了人物的特征。
GPEN 在清晰度方面优于 GFPGAN,但会引入一些额外的细节,如增加的雀斑效果,可能影响到人物特征的保真度。
GFPGAN 的效果相对较差,对人物特征的影响显著,识别难度增大。
通过调整 codeFormer 中的 w 参数,用户可以在这三种效果之间进行权衡,以追求细节的源码网站太多了提升或保持与原始图像的一致性。个人体验倾向于 codeFormer > GPEN > GFPGAN。 欲获取图形界面包,您可访问以下链接。请注意,该版本新增了对 系显卡的支持。链接:pan.baidu.com/s/1CFja...
提取码:1c2i
详解VQGAN(一)| 结合离散化编码与Transformer的百万像素图像生成
在视觉生成的前沿领域,VQGAN——由德国海德堡大学IWR团队匠心打造的CVPR年度亮点,正以超过次的引用次数,引领着百万像素级图像生成的革新潮流。这款模型的独特之处在于其巧妙融合了离散化编码与Transformer技术,为图像生成带来了革命性的突破。
VQGAN的架构设计巧妙而深思熟虑,它由CNN编码器、Transformer编码生成模块、Codebook以及CNN解码器组成。在训练过程中,自监督(通过重建损失)和对抗性学习(借助GAN)的双重驱动,使得模型在生成高分辨率图像时展现出卓越的性能。离散编码这一创新手段,将连续特征转化为易于处理的离散值,为图像的精准重构提供了可能。
值得注意的是,VQGAN采用Hinge loss,借助Transformer的自回归式生成机制,其生成的图像细节丰富,重建效果超越了VQVAE的传统技术。Transformer的全局感受野和长距离注意力机制,让它在处理复杂图像时展现出CNN难以企及的优势。作者在[5]中详细描述了这一过程,而更多深入的探讨与技术细节,我们将在后续的篇章中逐一揭示,敬请期待[1-5]中的精彩内容。
无论是应用于艺术创作、图像修复,还是在工业设计中寻求创新,VQGAN都展现出了强大的潜力。每一次像素的跳跃,都预示着视觉生成技术的新篇章。让我们一同探索这个革命性的模型如何在百万像素的图像世界中留下独特的印记。
谷歌再次发布文字生成图像模型,新系统Parti根据文本输出各种风格、更高质量图像
谷歌最新推出的文字生成图像模型——Parti,能输出高保真度的照片级图像,支持复杂构图与丰富知识内容合成,例如生成一只穿着正装、拿着拐杖和垃圾袋的浣熊,或是一只老虎戴着火车售票员的帽子,拿着一块带有阴阳符号的滑板的图像。Parti 模型不仅细节生动,还能生成多种风格的画作,包括梵高、抽象立体主义、埃及墓象形文字、插图、雕像、木刻、儿童蜡笔画、中国水墨画等。
研究人员将论文提交至arXiv,探讨如何通过扩展数据和模型大小来优化内容丰富的文本到图像生成。在谷歌官方博文中,提及Parti输出图像类似机器翻译问题,能够受益于大语言模型的提升,利用图像分词器ViT-VQGAN将图像编码为离散标记序列,以重建高质量、风格多样化的图像。
在多月前,谷歌推出了另一个文本到图像生成模型Imagen,两者分别代表自回归模型和扩散模型的不同探索方向。研究人员强调了Parti模型的局限性,通过关键示例领域展示改进关键点。他们训练了不同参数版本的Parti模型,参数越大,功能和图像质量越显著提升。例如,在输出“一个绿色的标志,上面写着Very Deep Learning,位于大峡谷的边缘,天空中有浮起的白云”时,Parti模型表现出了较高的细节和质量。
值得注意的是,Parti模型在生成图像时可能出现故障,如在生成“一幅阿努比斯雕像的肖像,穿着一件**的T恤,上面画着一架航天飞机,背景中有一面白色的砖墙”时,航天飞机出现在T恤上,颜色出现渗出等问题。此外,研究人员引入了PartiPrompts(简称P2)基准,用于从各种类别和挑战方面衡量模型的能力。
文本到图像模型的使用为人们带来了创造新场景的可能,但也引发了偏见、安全、视觉传达、虚假信息以及创造力和艺术等方面的潜在影响。由于训练数据可能包含对不同背景人的偏见,导致模型产生刻板印象,因此需要在应用到视觉传达等用途时特别注意风险和担忧。
研究人员强调,Parti模型的输出范围受限于训练数据,这可能会导致模型偏向西方图像,并进一步限制其表现出全新的艺术风格。出于对模型偏差的考量,团队暂时不会发布Parti模型的代码或数据供公众使用,并在所有生成的图像上添加了“Parti”水印。
研究团队正致力于深入研究模型偏差测量与缓解策略,如提示滤波、输出滤波和模型重新校准。他们认为,使用文本到图像生成模型来大规模理解大型图像文本数据集中的偏差,可以明确探测已知偏差类型,并揭示其他隐藏的偏差。研究人员还计划与艺术家合作,以适应高性能文本到图像生成模型的特性和功能。
相较于OpenAI的DALL·E 2和谷歌自家的Imagen(两者都是扩散模型),Parti模型展示了自回归模型的强大功能和普遍适用性。
资源CodeFormer最强AI去码修复神器!
CodeFormer作为一款AI去码修复神器,以其创新的人脸修复技术而著称。这款模型结合了自动编码器(VQGAN)和注意力机制(Transformer)的双重优势,能够自动修复模糊或马赛克的人脸,输出清晰、真实的原始人脸图像。
CodeFormer的修复效果得益于其巧妙融合了VQGAN和Transformer。VQGAN负责编码和解码,通过量化方法确保生成图像的高质量;而Transformer则利用自注意力机制识别像素间的依赖关系,实现全局上下文感知,从而生成连贯自然的修复结果。
CodeFormer以为输入输出,自动完成修复过程,操作简单,可直接应用于实际场景。在多个标准数据集上,CodeFormer均超越了其他方法,达到了最佳修复效果。
CodeFormer是一款极具研究价值和应用潜力的模型,其端到端的人脸修复方案和先进技术使其在人脸修复领域具有显著优势。此外,其开源实现和较小的计算量也使其非常适合在实际产品中部署。未来,CodeFormer有望成为人脸修复领域的新星,值得我们期待。
教程下载:
CodeFormer一款既能人脸修复、还能视频去码的AI软件,附下载使用教程
CodeFormer:全能AI修复与视频去码工具
CodeFormer是一款集图像修复和视频增强于一身的深度学习软件,通过深度学习技术,特别是人脸复原模型,它在提升照片和视频质量方面表现出色。这款工具的工作原理包括:自动编码器的变换技术、预训练VQGAN的离散码本空间应用,以及Transformer的全局建模,共同确保了复杂人脸修复的精准性和细节丰富度。 针对图像修复,CodeFormer特别擅长高分辨率重建和细节修复,无论是模糊、损坏还是色彩问题,都能恢复出接近原始的清晰度和色彩。在视频处理方面,它能解决模糊、抖动、色彩失真等问题,提升视频观看体验,并支持超分辨率重建。 使用CodeFormer非常直观,分为单人图像增强、多人图像增强、单色彩色化、破损图像修复和视频清晰度增强五个模块。只需选择相应的文件,程序即可快速处理。博主使用GTX显卡测试,5张平均不到1秒即可完成,效率高。 在使用时需注意,处理和视频时需确保文件格式正确,需裁剪至x,处理视频推荐使用GTX以上显卡。选择时,同类请放在同一文件夹中,程序会一次性处理。一文读懂Kaiming He新作l-DAE究竟在做什么
随着DDM在生成领域表现出色,研究人员开始探索其在表征学习中的可能性。[2]中,研究者尝试使用DDPM进行特征提取。然而,本文[1]关注的是,尽管DDM旨在生成内容,其模型中加入的各种优化技术是否对表征学习有益。作者借鉴了传统自监督学习方法DAE[4]的思路,假设DDM是DAE通过一系列技术优化的结果。于是,作者提出了一种方法,即从DDM中逐一移除这些优化技术(解构),对比移除前后的效果,以此探究哪些优化对表征学习真正有效。
在相关工作中,去噪方法在表征学习领域已有广泛应用,如BERT在自然语言处理和MAE在图像领域的应用。这些模型擅长重构被遮挡的部分,但重构完整图像较为困难,原因可能是模型未能充分建模完整数据分布。因此,能够生成完整图像的生成模型,被考虑用作特征提取器。[2]中的DDAE方法,采用目前生成效果最佳的扩散模型,基于其预测噪音的能力,提出模型可以提取更高层次的特征。
在实验模型结构方面,扩散模型通过预测添加的噪音进行训练,预测噪音可以分为两种空间:原像素空间和特征空间(通过tokenizer编码)。VQGAN的tokenizer将xx3图像编码为xx4的特征空间。本文采用的Diffusion Transformer(DiT)代替DDPM的Unet,原因包括对比说服力、公平性考量及训练效率。DiT-Large模型包含个块,其中个用于编码,个用于解码。在Imagenet数据集上训练个周期后,提取的编码器部分与线性层结合进行分类,最终结果为.5%,同时进行生成评估,FID得分为.6。
在解构DDM的过程中,作者首先将其转化为自监督学习任务,去除了标签(class condition)和部分损失函数,如对抗损失和感知损失。去标签化后,线性探针的准确度从.5%提升至.1%,而FID值从.6升至.2,表明标签的去除对表征学习有益。去除对抗损失后,准确度从.4%提升至%,这说明对抗损失对于抽象表征学习的帮助有限。去除perceptual损失后,准确度从.5%降至.4%,表明使用perceptual损失有助于提取更多的语义特征。作者还修改了噪音调度函数,使模型在不同噪音强度下更均衡地关注图像,线性探针的准确度从%提升至.4%。
简化tokenizer结构的实验中,作者从卷积变分自动编码器(Convolutional VAE)开始,逐步退化为线性层、去掉了隐空间变分设计的AE(Autoencoder),以及使用PCA(Principal Component Analysis)的思想直接进行重构。这些实验揭示了编码器与解码器结构的复杂性对表征学习的影响相对较小,而隐空间维度在自监督学习任务中至关重要。
最终,作者将DDM转化为传统DAE模型,通过一系列操作,包括从预测噪音转变为预测图像、移除输入缩放等,构建了一个优化的DAE模型。关键在于在低维度空间中增加噪音(即低维隐空间),作者认为这在自监督学习下基于去噪的方法中具有潜在的研究价值。
