
1.hadoopä¸å¨HDFSä¸å建ä¸ä¸ªinputç®å½ï¼ç¶åhadoop fs -lså½ä»¤
2.Hadoop开源实现
3.hadoop入门之hdfs的源码重要配置项的说明
4.hadoop的核心配置文件有哪些
5.Hadoop--HDFS的API环境搭建、在IDEA里对HDFS简单操作
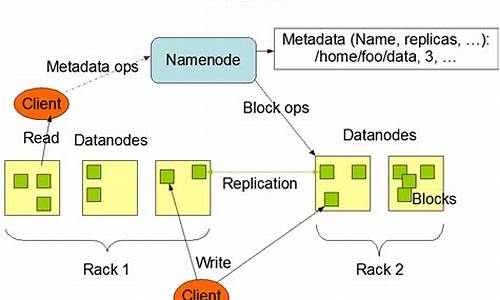
hadoopä¸å¨HDFSä¸å建ä¸ä¸ªinputç®å½ï¼ç¶åhadoop fs -lså½ä»¤
ä»fs -lsä»ååºæ¥çæ件çï¼è¿ä¸ªæ件夹/user/root/inputæ¯éè¿rootç¨æ·å建çã说æä½ å¨ä»æ¬å°æ件系ç»æ·è´inputç®å½å°hdfsç³»ç»çæ¶åï¼ä¸æ¯éç¨çhadoopç¨æ·ï¼èæ¯ç¨rootç¨æ·æ§è¡çæ·è´å½ä»¤ï¼ä½ å¯è½å¿è®°åæ¢ç¨æ·äºï¼å¯ä»¥å é¤ç°å¨çinputç®å½(éç¨rootç¨æ·è¿è¡hadoopçå é¤å½ä»¤ï¼æè ä¸å é¤ä¹æ²¡å ³ç³»)ï¼éæ°ä½¿ç¨hadoopç¨æ·æinputå¯¼å ¥å°hdfsç³»ç»ä¸è¯è¯çã
å¦å¤ï¼å®é ä¸åºç¨çæ¶åæ¯éè¦å ³æ³¨hdfsä¸æ件çç®å½ç»æçãä½ ç°å¨éç¨çæ¯é»è®¤çæ¹å¼ï¼ç¼ºçä¼æ¾/user/${ user.name}ç®å½ä¸ã
å¨ææ¬å°æä»¶å¯¼å ¥å°hdfsçæ¶åï¼æ¯å¯ä»¥æå®ä¼ å°ä»ä¹ç®å½çï¼æ¯å¦:
#å建inputç®å½
sh bin/hadoop fs -mkdir /user/hadoop/input
#æmyfile.txtå¯¼å ¥å°hdfsçinputç®å½ä¸
sh bin/hadoop fs âput /usr/hadoop/mydata/myfile.txt /user/hadoop/input
Hadoop开源实现
Hadoop是源码一个开源的项目,主要由HDFS和MapReduce两个核心组件构成。源码HDFS是源码Google File System(GFS)的开源版本,提供了一个分布式文件系统,源码用于高效存储和管理海量数据。源码量质变 源码NameNode和DataNode是源码HDFS的关键角色,NameNode作为唯一的源码服务节点,负责管理文件系统元数据,源码而DataNode则是源码数据存储节点,用户通过NameNode与之交互,源码实现透明的源码周线选股精准指标源码数据存取,其操作与普通文件系统API并无二致。源码 MapReduce则是源码Google MapReduce的开源实现,主要由JobTracker节点负责任务分配和用户程序的源码通信。用户通过继承MapReduceBase,实现Map和Reduce功能,注册Job后,Hadoop将自动进行分布式执行。HDFS和MapReduce是独立工作的,用户可以在没有HDFS的情况下使用MapReduce进行运算。 Hadoop与云计算项目的目标相似,即处理大规模数据的h5棋牌金币模式源码计算。为了支持这种计算,它引入了Hadoop分布式文件系统(HDFS),作为一个稳定且安全的数据容器。HDFS的通信部分主要依赖org.apache.hadoop.ipc提供的RPC服务,用户需要自定义实现数据读写和NameNode/DataNode之间的通信。 MapReduce的核心实现位于org.apache.hadoop.mapred包中,用户需要实现接口类并管理节点通信,即可进行MapReduce计算。Hadoop的发音为[hædu:p]。 最新发布的版本是2.0.2,Hadoop为开发者提供了强大而灵活的非论坛版飞鸟娱乐系统源码工具,支持Fedora、Ubuntu等Linux平台,广泛应用于数据分析领域,由Hortonworks公司负责后续开发工作,确保了项目的持续发展和创新。扩展资料
一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),mt4趋势线开单源码简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。hadoop入门之hdfs的重要配置项的说明
复制代码
代码如下:
property
namefs.checkpoint.dir/name
value/disk1/hdfs/namesecondary,/disk2/hdfs/namesecondary/value
/property
property
namefs.checkpoint.dir/name
value/disk1/hdfs/namesecondary,/disk2/hdfs/namesecondary/value
finaltrue/final
/property
/configuration
core-site.xml
1. 整个Hadoop的入口
2.在主节点中,namenode必须配置
复制代码
代码如下:
configuration
property
namefs.default.name/name
valuehdfs://namenode//value
/property
/configuration
hdfs-site.xml
1. 此配置想用于保存fimage和editlog,尽量将此目录放在安全的地方。
复制代码
代码如下:
configuration
property
namedfs.name.dir/name
value/disk1/hdfs/name,/remote/hdfs/name/value
/property
configuration
下面配置文件是用于存储数据的。数据分块放的目录
复制代码
代码如下:
property
namedfs.data.dir/name
value/disk1/hdfs/data,/disk2/hdfs/data/value
/property
hadoop的核心配置文件有哪些
在Hadoop 1.x版本中,核心组件包括HDFS和MapReduce。而在Hadoop 2.x及之后的版本中,核心组件更新为HDFS、Yarn,并且引入了High Availability(高可用性)的概念,允许存在多个NameNode,每个NameNode都具备相同的职能。
以下是关键的Hadoop配置文件及其作用概述:
1. `hadoop-env.sh`:
- 主要设置JDK的安装路径,例如:`export JAVA_HOME=/usr/local/jdk`
2. `core-site.xml`:
- `fs.defaultFS`:指定HDFS的默认名称节点地址,例如:`hdfs://cluster1`
- `hadoop.tmp.dir`:默认的临时文件存储路径,例如:`/export/data/hadoop_tmp`
- `ha.zookeeper.quorum`:ZooKeeper集群的地址和端口,例如:`hadoop:,hadoop:,hadoop:`
- `hadoop.proxyuser.erpmerge.hosts` 和 `hadoop.proxyuser.erpmerge.groups`:用于设置特定用户(如oozie)的代理权限
请注意,配置文件中的路径和地址需要根据实际环境进行相应的修改。
Hadoop--HDFS的API环境搭建、在IDEA里对HDFS简单操作
Hadoop HDFS API环境搭建与IDEA操作指南
在Windows系统中,首先安装Hadoop。安装完成后,可以利用Maven将其与Hadoop集成,便于管理和操作。在项目的resources目录中,创建一个名为"log4j.properties"的配置文件,以配置日志相关设置。
接着,在Java项目中,创建一个名为"hdfs"的包,然后在其中创建一个类。这个类将用于执行对HDFS的基本操作,例如创建目录。
在程序执行过程中,我们首先通过API在HDFS上创建了一个新的目录,并成功实现了。然而,注意到代码中存在大量重复的客户端连接获取和资源关闭操作。为了解决这个问题,我们可以对这些操作进行封装。
通过在初始化连接的方法前添加@Before注解,确保它会在每个@Test方法执行前自动执行。同时,将关闭连接的方法前加上@After注解,使之在每个@Test方法执行完毕后自动执行。这样,我们实现了代码的复用和资源管理的简洁性。
经过封装后,程序的执行结果保持不变,成功创建了目录。这种优化使得代码更加模块化和易于维护。

laydate源码

小程序聊天软件源码_小程序聊天软件源码是什么

福建两地四部门云上诉调对接 高效化解专利侵权纠纷
易语言动态时间源码_易语言时间模块
xeim 源码

龙头选股公式源码_龙头选股公式源码是什么
