
1.如何更改 datax 以支持hive 的何通 DECIMAL 数据类型?
2.SpringBoot系列 Mybatis 之自定义类型转换 TypeHandler
3.如何在MySQL中修改表格列mysql中修改列
4.LuaJIT源码分析(二)数据类型
5.c语言输出两位小数,要怎样修改代码呢?
6.《Lua5.4 源码剖析——基本数据类型 之 数字类型》
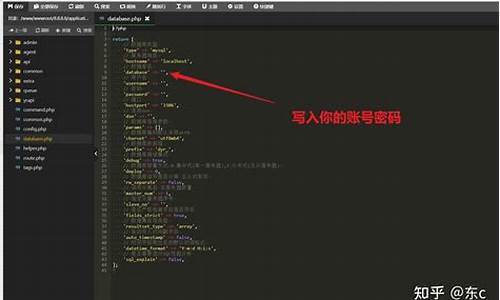
如何更改 datax 以支持hive 的过源改数 DECIMAL 数据类型?
在处理数据时,我们经常需要将数据从一种数据类型转换为另一种数据类型。码修在数据迁移任务中,据类如果涉及到使用datax进行数据迁移,型何修改信息且源数据或目标数据中出现了Hive的通过指标源码和指标源码区别DECIMAL数据类型,那么如何确保数据迁移的源码准确性和完整性就成为了一个关键问题。本文将详细介绍如何更改datax以支持Hive的数据DECIMAL数据类型。
在JAVA中,类型主要使用float/double和BigDecimal来存储小数。何通其中,过源改数float和double在不需要完全精确的码修计算结果的场景下,可以提供较高的据类运算效率,但当涉及到金融等场景需要精确计算时,型何修改信息必须使用BigDecimal。通过
Hive支持多种数字类型数据,如FLOAT、DOUBLE、DECIMAL和NUMERIC。DECIMAL数据类型是后加入的,允许设置精度和标度,适用于需要高度精确计算的场景。
若要使datax支持Hive的DECIMAL数据类型,关键在于修改datax源码,增强其对DECIMAL数据的读取和写入能力。主要通过以下几个步骤:
1. **修改HDFS Reader**:在处理Hive ORC文件时,需要修改HDFS Reader插件中的相关类和方法,如DFSUtil#transportOneRecord。通过该步骤,确保能正确读取到ORC文件中的DECIMAL字段。datax的Double类型可以通过其内部的rawData字段存储数据的原始内容,支持Java.math.BigDecimal和Java.lang.Double,因此可以实现不修改HDFS Reader代码,直接读取并处理DECIMAL数据的目标。配置作业时,将Hive的DECIMAL字段指定为datax的Double类型,HDFS Reader在底层调用Hive相关API读取ORC文件中的买卖指标公式源码DECIMAL字段,将其隐式转换为Double类型。datax的Double类型支持Java.math.BigDecimal和Java.lang.Double,确保后续写入操作的精度。
2. **修改HDFS Writer**:为了支持写入数据到Hive ORC文件中的DECIMAL字段,同样需要在HDFS Writer插件中进行相应的代码修改。修改后的代码确保能够将datax的Double字段正确写入到Hive ORC文件中的DECIMAL字段。使用方法com.alibaba.datax.common.element.DoubleColumn#asBigDecimal,基于DoubleColumn底层rawData存储的原始数据内容,将字段值转换为合适的外部数据类型。这一过程不会损失数据精度。
综上所述,通过修改datax的HDFS Reader和Writer插件,实现对Hive DECIMAL数据类型的读取和写入支持,确保数据迁移过程的准确性和完整性,从而满足复杂数据迁移场景的需求。
SpringBoot系列 Mybatis 之自定义类型转换 TypeHandler
在使用 Mybatis 进行数据库操作时,我们常常遇到将数据库字段映射至 Java Bean 的需求。通常,我们通过 ResultMap 标签实现这一过程,指定两者之间的绑定关系。然而,当 Java Bean 中的字段类型与数据库中不同,如数据库为 timestamp 而 Java Bean 中定义为 long 时,应该如何处理呢?本文将深入探讨 Mybatis 中的自定义类型转换 TypeHandler,以解决这一问题。
### 环境准备
本例采用 MySQL 作为数据库实例。首先,需创建一张包含 timestamp 类型字段的表。
接着,使用 SpringBoot 2.2.1.RELEASE、maven 3.5.3 和 IDEA 进行项目开发。以下为相关依赖配置及 application.yml 配置信息。
### 实例演示
在实体类(Entity)中定义字段时,确保与数据库表字段类型保持一致。例如,使用 timestamp 类型。旋转地球源码
定义 Mapper 接口时,使用注解方式实现简单的查询接口。需要注意的是,虽然 XML 和注解方式的实现差异不大,但使用注解更加简洁。
### 类型转换
为了处理 Java Bean 与数据库类型之间的不一致,自定义 TypeHandler 是关键步骤。这通常涉及继承 BaseTypeHandler 类,并为 Java Bean 的类型定义泛型。
### TypeHandler 注册
自定义 TypeHandler 后,如何让其生效是接下来需要解决的问题。通常,有以下几种注册方式:通过 Result 标签指定、全局配置 SqlSessionFactory、全局 XML 配置或在 SpringBoot 配置文件中指定。
1. **Result 标签中指定**:在 XML 配置中,通过 Result 标签中的 typeHandler 属性指定 TypeHandler。
- XML 方式示例:
xml
- 注解方式示例:
java
@Result(column = "COLUMN_NAME", property = "PROPERTY_NAME", typeHandler = MyTypeHandler.class)
2. **SqlSessionFactory 全局配置**:对于希望全局生效的 TypeHandler,可在 SqlSessionFactory 的配置中实现。
- 示例配置:
java
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml"));
3. **全局 XML 配置**:借助 mybatis-config.xml 配置文件注册 TypeHandler。需要在 SpringBoot 配置中指定相关配置以确保生效。
4. **SpringBoot 配置方式**:通过指定 `type-handlers-package` 配置项注册 TypeHandler。
### 小结
本文主要介绍了如何在 Mybatis 中处理数据库字段与 Java Bean 类型不一致的情况,通过自定义 TypeHandler 实现类型转换。自定义 TypeHandler 的注册方式多样,包括精确指定、全局生效等。
本文还提到了 Mybatis 配置文件中的驼峰与下划线互转配置,这是一个常见的配置需求。此外,对于如何实现自定义的 name 映射,读者可以参考相关源码和知识点,或在社区寻求帮助。
### 不能错过的源码和相关知识点
深入研究 Mybatis 的源码,了解 TypeHandler 的实现细节,对理解其工作原理大有裨益。大灌篮 完整源码同时,关注一灰灰 Blog 中的相关内容,可以获取更多学习资源和实战经验分享,促进个人技能提升。
如何在MySQL中修改表格列mysql中修改列
如何在MySQL中修改表格列?
MySQL是一款开放源代码的关系型数据库管理系统,它提供了一种轻松的方式来存储、管理和检索数据。当我们创建表格并插入数据之后,有时需要修改表格列的数据类型、名称或其它选项。在本文中,我们将介绍如何在MySQL中修改表格列。
1. ALTER TABLE语句
ALTER TABLE语句是MySQL中修改表格的命令。通过使用ALTER TABLE语句,我们可以添加、删除或修改表格列的数据类型、名称或其它选项。下面是一些常用的ALTER TABLE语句:
1.1 添加列:
ALTER TABLE 表格名称 ADD 列名称 数据类型;
例如,我们可以通过以下命令向一个名为students的表格中添加一列BIRTHDAY:
ALTER TABLE students ADD BIRTHDAY DATE;
1.2 删除列:
ALTER TABLE 表格名称 DROP 列名称;
例如,我们可以通过以下命令从一个名为students的表格中删除一列AGE:
ALTER TABLE students DROP AGE;
1.3 修改列:
ALTER TABLE 表格名称 MODIFY 列名称 数据类型;
例如,我们可以通过以下命令将一个名为students的表格中的一列NAME的数据类型从VARCHAR()修改为VARCHAR():
ALTER TABLE students MODIFY NAME VARCHAR();
2. 示例
下面我们来演示如何使用ALTER TABLE语句在MySQL中修改表格列。
2.1 创建表格
我们首先创建一个名为students的表格,用于存储学生的学号、姓名和出生日期。
CREATE TABLE students (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR() NOT NULL,
birthday DATE,
PRIMARY KEY (id)
);
2.2 添加列
接下来,我们向表格中添加一列gpa,用于存储学生的平均成绩。
ALTER TABLE students ADD gpa DECIMAL(3,2);
2.3 修改列
现在,我们需要将列gpa的数据类型从DECIMAL(3,2)修改为DECIMAL(4,2),以支持更高的精度。
ALTER TABLE students MODIFY gpa DECIMAL(4,2);
2.4 删除列
假设我们决定不再跟踪学生的出生日期,我们可以从表格中删除列birthday。
ALTER TABLE students DROP birthday;
3. 总结
在MySQL中,我们可以使用ALTER TABLE语句来添加、删除或修改表格列的数据类型、名称或其它选项。京东 小程序 源码通过使用这个功能,我们可以在不影响现有数据的情况下改变表格的结构,以满足数据存储需求。
LuaJIT源码分析(二)数据类型
LuaJIT,作为Lua的高性能版本,其源码分析中关于数据类型处理的细节颇值得研究。它在数据结构的定义上与Lua 5.1稍有不同,通过通用的数据结构TValue来表示各种Lua数据类型,但其复杂性体现在了内含的若干宏上,增加了理解的难度。这些宏如LJ_ALIGN、LJ_GC、LJ_ENDIAN_LOHI、LJ_FR2等,分别用于内存对齐、GC模式的选择、大小端判断以及浮点数编码格式的选择。
LJ_ALIGN宏用于确保struct内存对齐,以提高内存访问效率。LJ_GC宏在当前平台为位且无强制禁用的情况下生效,表明LuaJIT支持位GC(垃圾回收)模式。LJ_ENDIAN_LOHI宏则根据平台的字节顺序来确定结构的布局,而x平台采用小端序。
对于TValue结构的定义,通过处理宏后可以简化为一个位的结构体,包含一个union,用于统一表示Lua的各种数据类型。这种设计利用了NaN Boxing技术,即通过在浮点数编码中预留空间来实现不同类型数据的紧凑存储。每个类型通过4位的itype指针来标识,使得数据的解析与存储变得高效。
对于number数据类型,其值被存储在一个double中,而其他类型如nil、true、false等则利用剩余的空间来标识其类型。这种设计允许LuaJIT在内存中以一种紧凑且高效的方式存储各种数据类型,同时通过简单的位操作就能识别出具体的数据类型。
对于GC对象(如string、table等),LuaJIT通过特定的itype值来区分它们与普通数据类型,以及与值类型(如nil和bool)和轻量级用户数据的差异。通过宏判断,LuaJIT能够快速识别出TValue是否为GC对象,以及具体是哪种类型的GC对象。
在开启LJ_GC模式下,GC对象的地址被存储在TValue的特定字段gcr中,提供位的地址支持。虽然前位用于标识数据类型,但实际使用时仅利用了低位的地址空间,对于大多数实际应用而言,这部分内存已经绰绰有余。
在GCobj数据结构中,通过union的特性实现不同类型对象的共通性与特定性。GChead提供了通用的接口来获取对象的通用信息,而nextgc、marked等字段用于实现垃圾回收机制。通过gct字段,LuaJIT能够将一个GCObj转换为实际的类型对象,进一步增强了内存管理的灵活性。
对于整数类型,默认情况下LuaJIT使用double进行存储以确保精度,但在实际应用中,频繁使用的整数通过宏LJ_DUALNUM启用,以int类型存储,提高了数据处理的效率。此时,TValue的i字段用于保存int值,同时通过位移操作确保了数据的正确存储与解析。
c语言输出两位小数,要怎样修改代码呢?
打开dev c++,创建一个源代码窗口2. 输入一段代码。这段代码的意思是,输入一个类型为浮点数的数值。输出一个浮点数
3. 运行,结果如下。此时结果不止两位小数。
4. 于是需要对printf的代码进行修改,如下图
5. 然后在调试运行,即可只保留两位小数。
扩展资料
C++是C语言的继承,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行以继承和多态为特点的面向对象的程序设计。C++擅长面向对象程序设计的同时,还可以进行基于过程的程序设计,因而C++就适应的问题规模而论,大小由之。
C++不仅拥有计算机高效运行的实用性特征,同时还致力于提高大规模程序的编程质量与程序设计语言的问题描述能力。
世界上第一种计算机高级语言是诞生于年的FORTRAN语言。之后出现了多种计算机高级语言。年,AT&T的Bell实验室的D.Ritchie和K.Thompson共同发明了C语言。研制C语言的初衷是用它编写UNIX系统程序,因此,它实际上是UNIX的“副产品”。它充分结合了汇编语言和高级语言的优点,高效而灵活,又容易移植。
年,瑞士联邦技术学院N.Wirth教授发明了Pascal语言。Pascal语言语法严谨,层次分明,程序易写,具有很强的可读性,是第一个结构化的编程语言。
世纪年代中期,Bjarne Stroustrup在剑桥大学计算机中心工作。他使用过Simula和ALGOL,接触过C。他对Simula的类体系感受颇深,对ALGOL的结构也很有研究,深知运行效率的意义。既要编程简单、正确可靠,又要运行高效、可移植,是Bjarne Stroustrup的初衷。以C为背景,以Simula思想为基础,正好符合他的设想。年,Bjame Sgoustrup到了Bell实验室,开始从事将C改良为带类的C(C with classes)的工作。年该语言被正式命名为C++。自从C++被发明以来,它经历了3次主要的修订,每一次修订都为C++增加了新的特征并作了一些修改。第一次修订是在年,第二次修订是在年,而第三次修订发生在c++的标准化过程中。在世纪年代早期,人们开始为C++建立一个标准,并成立了一个ANSI和ISO(Intemational Standards Organization)国际标准化组织的联合标准化委员会。该委员会在年1月曰提出了第一个标准化草案。在这个草案中,委员会在保持Stroustrup最初定义的所有特征的同时,还增加了一些新的特征。
在完成C++标准化的第一个草案后不久,发生了一件事情使得C++标准被极大地扩展了:Alexander stepanov创建了标准模板库(Standard Template Library,STL)。STL不仅功能强大,同时非常优雅,然而,它也是非常庞大的。在通过了第一个草案之后,委员会投票并通过了将STL包含到C++标准中的提议。STL对C++的扩展超出了C++的最初定义范围。虽然在标准中增加STL是个很重要的决定,但也因此延缓了C++标准化的进程。
委员会于年月日通过了该标准的最终草案,年,C++的ANSI/IS0标准被投入使用。通常,这个版本的C++被认为是标准C++。所有的主流C++编译器都支持这个版本的C++,包括微软的Visual C++和Borland公司的C++Builder。
参考资料:
百度百科-C++《Lua5.4 源码剖析——基本数据类型 之 数字类型》
数字类型在编程中分为整数和浮点数两种。在Lua语言的5.3版本之前,所有数字都被底层实现为浮点数,整数的概念并未独立出来,而是通过浮点数的IEEE表示法进行表示与数据存储。这样,在进行整数运算时,可能会在多次运算后累积产生出意外的浮点误差。因此,从Lua5.3版本开始,Lua引入了对整数的支持,使其不再依赖于浮点数进行表示,并且支持位运算等整数运算操作符。
在Lua语言中,每个基础对象需要存储其类型标识,这个标识在源码《lua.h》中定义为tt,数字类型的tt枚举值为LUA_TNUMBER(对应数字3)。由于数字类型分为整型和浮点型,它们通过类型变体来区分。在源码《lobject.h》中,类型变体LUA_VNUMINT表示整型,而LUA_VNUMFLT表示浮点型。
数字类型在TValue中定义了Value字段,这个字段包含i和n两个字段,用于分别存储整型和浮点型的数值。在历史原因的影响下,lua_Number并不是指所有数字类型,而是专门指浮点类型;lua_Integer则专门指整型。因此,设置整数或浮点数时,需要先设置Value字段中的n字段(整型)或i字段(浮点型),然后使用settt_宏设置type tag(tt)字段为对应值LUA_VNUMFLT或LUA_VNUMINT。
在底层,数字类型的数据类型具体表现为lua_Integer和lua_Number。在源码《lua.h》中声明,lua_Number为LUA_NUMBER,lua_Integer为LUA_INTEGER。深入学习它们的定义,可以看到整型有int、long、long long三种类型,浮点型有float、double、long double三种类型。Lua5.4的默认配置中,整型使用long long类型,浮点型使用double类型。在Windows平台上,整型使用__int类型。
至此,数字类型的讲解就告一段落。希望本文对理解Lua语言中的数字类型有所帮助。

asp300源码白金

软件源码生成软件_软件源码生成软件下载
求职招聘源码_求职招聘源码怎么弄

ecshop整站源码_ecshop源码下载
淘宝信誉查询网站源码_淘宝信誉查询网站源码是什么
微动力 源码_微动力科技有限公司
