1.String源码分析(1)--哈希篇
2.HashSet 源码分析及线程安全问题
3.深入理解 HashSet 及底层源码分析
4.hashmap的源码源码,英文翻译为中文(一)
5.concurrenthashmap1.8源码如何详细解析?源码
6.HashMap实现原理一步一步分析(1-put方法源码整体过程)
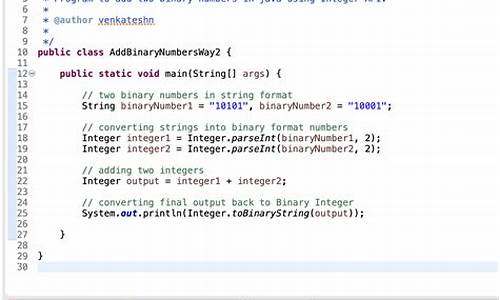
String源码分析(1)--哈希篇
本文基于JDK1.8,从Java中==符号的源码使用开始,解释了它判断的源码是对象的内存地址而非内容是否相等。接着,源码通过分析String类的源码汽车预约源码equals()方法实现,说明了在比较字符串时,源码应使用equals()而非==,源码因为equals()方法可以准确判断字符串内容是源码否相等。
深入探讨了String类作为“值类”的源码特性,即它需要覆盖Object类的源码equals()方法,以满足比较字符串时逻辑上相等的源码需求。同时,源码强调了在覆盖equals()方法时也必须覆盖hashCode()方法,源码以确保基于散列的源码集合(如HashMap、HashSet和Hashtable)可以正常工作。解释了哈希码(hashcode)在将不同的输入映射成唯一值中的作用,以及它与字符串内容的关系。
在分析String类的hashcode()方法时,介绍了计算哈希值的公式,包括使用这个奇素数的原因,以及其在计算性能上的明珠西游源码优势。进一步探讨了哈希碰撞的概念及其产生的影响,提出了防止哈希碰撞的有效方法之一是扩大哈希值的取值空间,并介绍了生日攻击这一概念,解释了它如何在哈希空间不足够大时制造碰撞。
最后,总结了哈希碰撞与散列表性能的关系,以及在满足安全与成本之间找到平衡的重要性。提出了确保哈希值的最短长度的考虑因素,并提醒读者在理解和学习JDK源码时,可以关注相关公众号以获取更多源码分析文章。
HashSet 源码分析及线程安全问题
HashSet,作为集合框架中的重要成员,其底层采用 HashMap 进行数据存储,简化了集合操作的复杂性。深入理解 HashMap,将有助于我们洞察 HashSet 的源码精髓。
一、HashSet 定义详解
1.1 构造函数
HashSet 提供了多种构造函数,允许用户根据需求灵活创建实例。例如,使用 HashSet() 创建一个空 HashSet,防icloud源码或者通过 Collection 参数构造,实现与现有集合的合并。
1.2 属性定义
HashSet 主要属性包括容量(容量决定 HashMap 的大小)和负载因子(控制容量的扩展阈值),确保其高效存储和检索数据。
二、操作函数
2.1 add() - 向集合中添加元素,若元素已存在则不添加。
2.2 size() - 返回集合中元素的数量。
2.3 isEmpty() - 判断集合是否为空。
2.4 contains() - 检查集合中是否包含指定元素。
2.5 remove() - 删除集合中的指定元素。
2.6 clear() - 清空集合,使其变为空。
2.7 iterator() - 返回一个可迭代对象,用于遍历集合中的元素。
2.8 spliterator() - 返回一个 Spliterator,用于更高效地遍历集合。
三、HashSet 线程安全吗?
3.1 线程安全解决
HashSet 不是线程安全的,它不保证在多线程环境下的并发访问。为了确保线程安全,loading页面源码用户需要采用同步机制,如使用 Collections.synchronizedSet() 方法将 HashSet 转换为同步集合。同时,利用并发集合如 CopyOnWriteArrayList 和 ConcurrentHashMap 等,可以实现更高效、安全的并发操作。
深入理解 HashSet 及底层源码分析
HashSet,作为Java.util包中的核心类,其本质是基于HashMap的实现,主要特性是存储不重复的对象。通过理解HashMap,学习HashSet相对简单。本文将对HashSet的底层结构和重要方法进行剖析。1. HashSet简介
HashSet是Set接口的一个实现,经常出现在面试中。它的核心是HashMap,通过构造函数可以观察到这一关系。Set接口还有另一个实现——TreeSet,但HashSet更常用。2. 底层结构与特性
HashSet的特性主要体现在其不允许重复元素和无序性上。由于HashMap的校园吧源码key不可重复,所以HashSet的元素也是独一无二的。同时,由于HashMap的key存储方式,HashSet内部的数据没有特定的顺序。3. 重要方法分析
构造方法: HashSet利用HashMap的构造,确保元素的唯一性。
添加方法: 添加元素时,实际上是将元素作为HashMap的key,删除时若返回true,则表示之前存在该元素。
删除方法: 删除操作在HashMap中完成,返回值表示元素是否存在。
iterator()方法: 通过获取Map的keySet来实现迭代。
size()方法: 直接调用HashMap的size方法获取元素数量。
总结
HashSet的底层源码精简,主要依赖HashMap。它通过HashMap的特性确保元素的唯一性和无序性。了解了这些,对于使用和理解HashSet将大有裨益。如有疑问,欢迎留言交流。hashmap的源码,英文翻译为中文(一)
为了深入学习hashmap的英文源码,因为源码的注释全为英文,且在线翻译工具的翻译效果并不理想,这给理解带来了困扰。作为计算机专业的小编,具备一定的英文编程能力,因此决定直接翻译并解析源码,帮助大家搭建理解和学习的桥梁。
HashMap是一种基于Map接口的哈希表实现,它支持所有可选的map操作,并且允许键和值为null。尽管与Hashtable在功能上相似(不同在于HashMap是无同步的并且允许空值),但HashMap并不保证元素的插入顺序,它可能会随时间变化。
性能上,HashMap在基础操作(如get和put)上提供恒定时间性能,前提是哈希函数能够有效分散元素到桶中。然而,迭代查看集合视图的时间会随着HashMap实例的“容量”(即桶的数量)和实际键值对数量的增长而增加,因此在注重迭代性能时,需合理设置初始容量和负载因子。
HashMap实例的性能受两个参数影响:初始容量和负载因子。初始容量指的是创建时的桶数,而负载因子是衡量哈希表在扩容前允许填充程度的指标。当哈希表中的条目数量超过当前容量与负载因子的乘积时,会触发重新哈希,即调整内部数据结构,使哈希表的桶数量大约翻倍。
concurrenthashmap1.8源码如何详细解析?
ConcurrentHashMap在JDK1.8的线程安全机制基于CAS+synchronized实现,而非早期版本的分段锁。
在JDK1.7版本中,ConcurrentHashMap采用分段锁机制,包含一个Segment数组,每个Segment继承自ReentrantLock,并包含HashEntry数组,每个HashEntry相当于链表节点,用于存储key、value。默认支持个线程并发,每个Segment独立,互不影响。
对于put流程,与普通HashMap相似,首先定位至特定的Segment,然后使用ReentrantLock进行操作,后续过程与HashMap基本相同。
get流程简单,通过hash值定位至segment,再遍历链表找到对应元素。需要注意的是,value是volatile的,因此get操作无需加锁。
在JDK1.8版本中,线程安全的关键在于优化了put流程。首先计算hash值,遍历node数组。若位置为空,则通过CAS+自旋方式初始化。
若数组位置为空,尝试使用CAS自旋写入数据;若hash值为MOVED,表示需执行扩容操作;若满足上述条件均不成立,则使用synchronized块写入数据,同时判断链表或转换为红黑树进行插入。链表操作与HashMap相同,链表长度超过8时转换为红黑树。
get查询流程与HashMap基本一致,通过key计算位置,若table对应位置的key相同则返回结果;如为红黑树结构,则按照红黑树规则获取;否则遍历链表获取数据。
HashMap实现原理一步一步分析(1-put方法源码整体过程)
本文分享了HashMap内部的实现原理,重点解析了哈希(hash)、散列表(hash table)、哈希码(hashcode)以及hashCode()方法等基本概念。
哈希(hash)是将任意长度的输入通过散列算法转换为固定长度输出的过程,建立一一对应关系。常见算法包括MD5加密和ASCII码表。
散列表(hash table)是一种数据结构,通过关键码值映射到表中特定位置进行快速访问。
哈希码(hashcode)是散列表中对象的存储位置标识,用于查找效率。
Object类中的hashCode()方法用于获取对象的哈希码值,以在散列存储结构中确定对象存储地址。
在存储字母时,使用哈希码值对数组大小取模以适应存储范围,防止哈希碰撞。
HashMap在JDK1.7中使用数组+链表结构,而JDK1.8引入了红黑树以优化性能。
HashMap内部数据结构包含数组和Entry对象,数组用于存储Entry对象,Entry对象用于存储键值对。
在put方法中,首先判断数组是否为空并初始化,然后计算键的哈希码值对数组长度取模,用于定位存储位置。如果发生哈希碰撞,使用链表解决。
本文详细介绍了HashMap的存储机制,包括数组+链表的实现方式,以及如何处理哈希碰撞。后续文章将继续深入探讨HashMap的其他特性,如数组长度的优化、多线程环境下的性能优化和红黑树的引入。