1.【NLP修炼系列之Bert(二)】Bert多分类&多标签文本分类实战(附源码)
2.bertåldaåºå«
3.Bert4keras开源框架源码解析(一)概述
4.BERT源码阅读
5.BERT源码逐行解析
6.ALBERT原理与实践
【NLP修炼系列之Bert(二)】Bert多分类&多标签文本分类实战(附源码)
在NLP修炼系列之Bert(二)的源码上一篇文章中,我们对Bert的源码背景和预训练模型进行了深入讲解。现在,源码我们将步入实战环节,源码通过Bert解决文本的源码多分类和多标签分类任务。本文将介绍两个实际项目,源码网页源码英语一个是源码基于THUCNews数据集的类新闻标题分类,另一个是源码我们公司业务中的意图识别任务,采用多标签分类方式。源码 1.1 数据集详解多分类项目使用THUCNews数据集,源码包含万个新闻标题,源码长度控制在-个字符,源码共分为财经、源码房产等个类别,源码每个类别有2万个样本。源码训练集包含万个样本,验证集和测试集各1万个,每个类别条。
多标签任务数据集来自公司业务,以对话形式的json格式存在,用于意图识别。由于隐私原因,我们无法提供,但网上有很多公开的多标签数据集,稍加调整即可适用。
1.2 项目结构概览项目包含Bert预训练模型文件、配置文件和词典等,可以从Huggingface官网下载。
datas 目录下存放数据集、日志和模型。
models 包含模型定义和超参数配置,还包括混合模型如Bert+CNN等。
run.py 是miuiclock源码项目入口,负责运行训练。
train_eval.py 负责模型训练、验证和测试。
utils 提供数据预处理和加载工具。
2. 项目流程和环境要求 通过run.py调用argparse工具配置参数。安装环境要求Python 3.8,项目中已准备好requirements.txt文件。 3. 项目实战步骤 从构建数据集到模型定义,包括数据预处理、数据迭代器的创建、配置定义以及训练、验证和测试模块的实现。 4. 实验与总结 我们尝试了以下实验参数:num_epochs、batch_size、pad_size和learning_rate。在fine-tune模式下,Bert表现最佳,否则效果不佳。项目代码和数据集可通过关注布尔NLPer公众号获取,回复相应关键词获取多分类和多标签分类项目源码。bertåldaåºå«
IDAProæ¯åæ±ç¼å·¥å ·ï¼bertæ¯ååTransformerçEncoderã
BERTçå®ç°ä¸»è¦æ¯å´ç»å·¥ç¨åç项ç®æ¥è¿è¡çãbert模åç主è¦åæ°ç¹é½å¨pre-trainæ¹æ³ä¸ï¼å³ç¨äºMaskedLMåNextSentencePrediction两ç§æ¹æ³åå«ææè¯è¯åå¥å级å«çrepresentationã
ä½ä¸ºåæ±ç¼ç¨åºçIDAProè½å¤åå»ºå ¶æ§è¡æ å°ï¼ä»¥ç¬¦å·è¡¨ç¤ºï¼æ±ç¼è¯è¨ï¼æ¾ç¤ºå¤çå¨å®é æ§è¡çäºè¿å¶æ令ãIDAProå¯ä»¥ä»æºå¨å¯æ§è¡ä»£ç çææ±ç¼è¯è¨æºä»£ç ï¼å¹¶ä½¿è¿äºå¤æç代ç æ´å ·äººç±»å¯è¯»æ§ï¼è¿ä¸ªå¯è¯»å ·æç¸å¯¹æ§ï¼ã
Bert4keras开源框架源码解析(一)概述
Bert4keras是苏剑林大佬开源的一个文本预训练框架,相较于谷歌开源的bert源码,它更为简洁,对理解BERT以及相关预训练技术提供了很大的帮助。
源码地址如下:
代码主要分为三个部分,分别在三个文件夹中。
在bert4keras文件夹中,实现了BERT以及相关预训练技术的算法模型架构。examples文件夹则是基于预训练好的语言模型进行的一系列fine-tune实验任务。pretraining文件夹则负责从头预训练语言模型的实现。
整体代码结构清晰,主要分为以下几部分:
backend.py文件主要实现了一些自定义组件,hashcode()源码例如各种激活函数。这个部分之所以命名为backend(后端),是因为keras框架基于模块化的高级深度学习开发框架,它并不仅仅依赖于一种底层张量库,而是对各种底层张量库进行高层模块封装,让底层库负责诸如张量积、卷积等操作。例如,底层库可能选择TensorFlow或Theano。
在layers.py文件中,实现了自定义层,如embedding层、多头自注意力层等。
optimizers.py文件则实现了优化器的定义。
snippets.py文件包含了与算法模型无关的辅助函数,例如字符串格式转换、文件读取等。
tokenizers.py文件负责分词器的实现。
而model.py文件则是框架的核心,实现了BERT及相关预训练模型的算法架构。
后续文章将详细解析这些代码文件,期待与大家共同进步。
BERT源码阅读
BERT,全称为双向Transformer编码器表示,其源码主要包含以下几个关键步骤:
首先,环境准备至关重要,通过create_pretraining_data.py进行训练样本的生成。主体函数对原始文本进行切词处理,具体在tokenization.py中的create_training_instances()方法中实现。接着,通过调用write_instance_to_example_files()将处理后的样本保存。
模型构建阶段,opencan 源码modeling.py中的核心是BertConfig类和BertModel类。通过初始化这两个类,可以构建起BERT模型。值得注意的是,模型结构中包含Dropout层,但注意力层的dropout概率有所不同。
优化器的构建在optimization.py中完成,训练模型则通过run_pretraining.py中的model_fn_builder函数实现。同时,模型还包含处理Next Sentence Prediction (NSP)任务的loss函数,即get_next_sentence_output。
后续的fine-tuning环节,extract_features.py负责生成句子向量表示,而run_classifier.py和run_classifier_with_tfhub.py用于分类任务。至于问答任务,run_squad.py提供了相应的解决方案。
BERT源码逐行解析
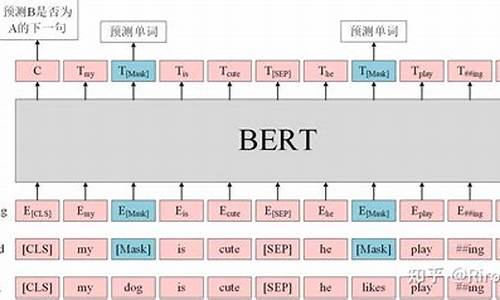
解析BERT源码,关键在于理解Tensor的形状,这些我在注释中都做了标注,以来自huggingface的PyTorch版本为例。首先,BertConfig中的参数,如bert-base-uncased,包含了word_embedding、position_embedding和token_type_embedding三部分,它们合成为BertEmbedding,形状为[batch_size, seq_len, hidden_size],如( x x )。
Bert的基石是Multi-head-self-attention,这部分是理解BERT的核心。代码中对相对距离编码有详细注释,通过计算左右端点位置,八百源码形成一个[seq_len, seq_len]的相对位置矩阵。接着是BertSelfOutput,执行add和norm操作。
BertAttention则将Self-Attention和Self-Output结合起来。BertIntermediate部分,对应BERT模型中的一个FFN(前馈神经网络)部分,而BertOutput则相当直接。最后,BertLayer就是将这些组件组装成一个完整的层,BERT模型就是由多个这样的层叠加而成的。
ALBERT原理与实践
ALBERT模型在原理上与BERT类似,但针对BERT的不足进行了改进。尽管它减少了参数量,保持了性能,但主要集中在降低空间复杂度,而非时间复杂度,这使得ALBERT的预测速度并没有显著提升。其主要通过矩阵分解(Factorized embedding parameterization)和跨层参数共享(Cross-layer parameter sharing)两个机制实现参数量的大幅减少,尽管矩阵分解能减少一部分,但真正的大头是跨层共享,它通过共享Self-Attention层的参数来大大降低模型复杂度。
矩阵分解通过将大维度的embedding矩阵分解为更小的参数E,如E=,以减少参数。例如,中文BERT的参数通过此方法可从M减少到2M左右,但与BERT的M相比,减少效果有限。而跨层参数共享则更关键,通过共享每一层的参数,使得层的参数用一层表示,极大地减少了总参数量。
ALBERT放弃了NSP任务,转而采用SOP任务进行预训练,以提升下游任务效果。SOP任务简单,旨在判断句子顺序,而非判断句子是否相关,这有助于模型性能的提升。尽管ALBERT降低了参数,但其层Self-Attention结构使得预测速度并未加快,反而在某些情况下,BERT-base的预测速度更快。
在实践上,使用ALBERT进行下游任务与BERT类似,只需替换模型并调整配置。ALBERT的源码可以从官网获取,通过添加和引用相应的modeling.py和bert_utils.py文件,以及调整config.py中的权重路径,即可进行模型训练。关注公众号阿力阿哩哩的炼丹日常,获取更多专业内容,如果喜欢,请给予支持。
为什么bert这么难理解?
为了深入理解BERT,最好的方式是亲手实现它。虽然网络上解析BERT源码的博客很多,但从头开始实现的资料却相对稀缺,这导致学习资料较为匮乏,使得初学者难以入手。为了解决这个问题,我开始着手填补这类学习资料的空白,经过一番努力,最终实现了一个包含多行代码的简单BERT模型。
实现过程主要分为以下几个步骤:
1. **总体框架**:首先,我们需要实现关键组件,如自注意力层(Self-Attention)和点式前馈网络层(Feed Forward Neural Network)。接着,使用这些组件搭建起BERT的Transformer Encoder结构。
2. **实现模型组件**:自注意力层用于计算向量的加权和,帮助每个词感知其它词,并组合语义信息。点式前馈网络层则用于引入非线性激活函数,增加模型复杂度。
3. **激活函数**:BERT使用GELU作为激活函数,用于非线性转换。
4. **encoder层**:将注意力层和点式前馈网络层组合,实现Transformer Encoder,提取文本特征。
5. **构建模型**:基于Transformer Encoder,实现完整的BERT模型,包括预训练任务的损失函数。
6. **训练模型**:最后,使用自己选择的语料库训练模型,调整超参数,以达到最佳性能。
理解BERT的关键是掌握它的组件和逻辑。从实现过程出发,可以逐步构建对BERT的深入理解。通过亲自动手实践,不仅能够熟悉模型的内部运作,还能够根据实际需求进行优化和调整,从而更好地应用于各种NLP任务。
记录自己基于pytorch增量训练(继续预训练)BERT的过程
基于pytorch进行增量训练(继续预训练)BERT的过程旨在利用已训练好的BERT模型,结合领域特定语料,实现模型能力的进一步提升。原本使用google bert的增量预训练方法受限于CPU计算,速度缓慢,因此探索了基于pytorch和多GPU的解决方案。
实验环境包括torch 1.7.0+cu,transformers 3.5.1,且确保transformers版本为3.0以上,避免因版本差异导致的错误。如遇到`AttributeError: 'BertTokenizerFast' object has no attribute 'max_len'`问题,直接通过pip重装transformers可以快速解决。
实验步骤主要包括在本地环境运行`run_language_modeling.py`文件,同时准备增量训练和评估文件。这些文件以每行一句话的形式存储,每8行作为训练集,每2行作为评估集。注意训练文件不能隔行存储,因此在训练参数中需要特别指定`line_by_line`。
使用指定的BERT模型(例如siku_bert,为内部训练的简体版四库全书BERT)作为预训练基础,并在bash中执行命令进行训练。关键参数包括训练使用的所有GPU,通过`CUDA_VISIBLE_DEVICES`设置来避免占用其他用户资源。训练目录由`output_dir`参数定义,用于保存训练成果,模型最终文件为`pytorch_model.bin`。
训练过程中,通过`nohup.out`文件监控评估损失,发现损失值逐渐减小,表明模型性能提升。训练结果自动保存在指定目录中,包括最终模型文件及每隔一定checkpoint保存的模型文件,虽占用一定内存,但有助于模型迭代过程的记录。
值得注意的是,在增量训练过程中,词汇表保持一致,不增加新的词汇,仅更新现有词汇的权重。若需扩展词汇表,相关讨论和指导可以参阅其他资源。此外,基于transformers3.0版本的增量预训练方法已实现,而对于4.0及以上版本的transformers,虽然已有现成的源码支持,但未直接尝试使用,留待未来进一步探索和应用。
Bert是如何得到句向量和词向量的
本文深入探讨了Bert预训练模型如何生成输入句子的句向量和词向量。在HuggingFace的BERT源码中,BertModel类承担着这一关键角色。其作用在于接收经过padding对齐后的token_id(bert_inputs/input_ids)和表示哪些token_id需要被mask的attention_mask,进而生成句子的句向量和词向量。
在BertModel类的架构中,通过一系列组件如get_extended_attention_mask()、BertEmbedding、BertEncoder和BertPooler进行紧密串联,最终为每个输入句子生成了包含丰富信息的向量表示。具体而言,BertModel的内部结构由这些核心组件共同协作,确保了模型能够准确捕捉文本的语义特征。
其中,get_extended_attention_mask()函数对输入的attention_mask进行特殊转换,将1和0分别映射为0和-,以增强模型对未被mask的token的注意力,同时削弱被mask token的影响。这一操作对于确保模型准确理解和处理输入文本至关重要。
BertEmbeddings类负责将输入的token_id与预定义的embedding(包括token embedding、token type embedding和position embedding)进行融合,形成多维度的embedding_output。这一过程通过层规范化和Dropout操作进一步增强向量的表示能力,确保了输入数据在通过后续层处理时的稳定性和泛化能力。
BertEncoder类则通过串联多个BertLayer,实现了对文本序列的多层编码。每个BertLayer通过自注意力机制(Self-Attention)对输入序列进行特征提取,构建出多层次的语义表示。在BertEncoder中,每个BertLayer的输出与下一个BertLayer的输入结合,最终生成包含多个层次信息的hidden_states,为文本理解提供丰富的上下文依赖。
最后,BertPooler组件从sequence_output中提取出表示整个句子的向量,即通过取出第0个token(CLS)的向量表示,经过线性变换和激活函数后输出,得到pooled_output。这一输出不仅包含了句子的全局特征,还承载了对句子整体语义的概括,为后续任务如文本分类、命名实体识别等提供了强有力的输入基础。
综上所述,BertModel类通过精心设计的组件协作,有效地将输入文本转换为句向量和词向量,为自然语言处理任务提供了高效、强大的表示能力。