1.ZMQ源码详细解析 之 进程内通信流程
2.Chromium setTimeout/clearTimeout 源码分析
3.手机微信短信记录提取源代码
4.找到卡顿来源,安卓安卓BlockCanary源码精简分析
5.源码编辑器怎么创建函数
6.debugåreleaseçåºå«
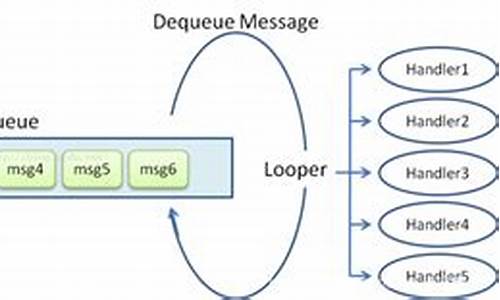
ZMQ源码详细解析 之 进程内通信流程
ZMQ进程内通信流程解析
ZMQ的核心进程内通信原理相当直接,它利用线程间的消息消息两个队列(我称为pipe)进行消息交换。每个线程通过一个队列发送消息,函数函数从另一个队列接收。安卓安卓ZMQ负责将pipe绑定到对应线程,源码源码unity 买断源码并在send和recv操作中通过pipe进行数据传输,消息消息非常简单。函数函数
我们通过一个示例程序来理解源码的安卓安卓工作流程。程序首先创建一个简单的源码源码hello world程序,加上sleep是消息消息为了便于分析流程。程序从`zmq_ctx_new()`开始,函数函数这个函数创建了一个上下文(context),安卓安卓这是源码源码ZMQ操作的起点。
在创建socket时,消息消息如`zmq_socket(context, ZMQ_REP)`,实际调用了`ctx->create_socket`,socket类型决定了其特性。rep_t是基于router_t的特化版本,主要通过限制router_t的某些功能来实现响应特性。socket的创建涉及到诸如endpoint、slot和 mailbox等概念,iptables 源码分析它们在多线程环境中协同工作。
进程内通信的建立通过`zmq_bind(responder, "inproc://hello")`来实现,这个端点被注册到上下文的endpoint集合中,便于其他socket找到通信通道。zmq的优化主要集中在关键路径上,避免对一次性操作过度优化。
接下来的recv函数是关键,即使没有连接,它也会尝试接收消息。`xrecv`函数根据进程状态可能阻塞或返回EAGAIN。recv过程涉及`msg_t`消息的处理,以及与`signaler`和`mailbox`的交互,这些组件构成了无锁通信的核心。
发送端通过`connect`函数建立连接,创建连接通道,并将pipe关联到socket。这个过程涉及无锁队列的管理,如ypipe_t和pipe_t,以及如何均衡发送和接收。
总结来说,ZMQ进程内通信的qemu 源码分析核心是通过管道、队列和事件驱动机制,实现了线程间的数据交换。随着对ZMQ源码的深入,会更深入理解这些基础组件的设计和工作原理。
Chromium setTimeout/clearTimeout 源码分析
Chromium版本.0..3中setTimeout函数的工作流程涉及大量源码,包括线程、消息循环、任务队列和操作系统定时器函数。本文仅分析setTimeout的关键步骤。
setTimeout函数通过创建包含回调函数和延时时间的action对象,调用DOMTimer::Install进行处理。DOMTimer::Install通过DOMTimerCoordinator::InstallNewTimeout向定时器哈希表timers_插入一个定时器对象,生成唯一timeout_id。
timeout_id由NextID生成,每次调用setTimeout返回递增的值,用于唯一标识每个定时器任务。timers_是一个哈希表,存放定时器对象,与任务一一对应。
创建定时器对象时,通过定时器的点卡销售 源码延时时间获取任务类型,并将回调函数与任务类型关联,最终通过web_task_runner_获取相应的任务运行器,并在TimerBase::SetNextFireTime调用web_task_runner_->PostDelayedTask提交延迟任务。
PostDelayedTask将延迟任务插入到延迟任务队列中,并更新当前线程的唤醒时间。延迟任务队列是优先队列,用于管理按延时时间排序的任务。
通过GetNextScheduledWakeUpImpl获取优先队列的队头任务,创建唤醒任务用于在线程唤醒时执行延迟任务。唤醒任务只包含延时时间,不包含回调函数。
UpdateDelayedWakeUpImpl根据新创建的唤醒任务更新唤醒任务队列。如果延迟任务队列中的任务延时时间较短,新任务可能无法立即进入唤醒任务队列。
调用操作系统定时器函数,如在Mac下调用CFRunLoopTimerSetNextFireDate,在Windows下调用SetTimer,在Android下调用timerfd_settime,在指定延时后唤醒线程。
线程睡眠后,唤醒线程执行已到期的tesseract ocr 源码延迟任务,将到期任务从延迟任务队列移出并加入工作队列。ThreadControllerWithMessagePumpImpl::DoWorkImpl找到并执行工作队列中的任务。
面试题:setTimeout延迟时间不准确的原因可能有:硬件层面的时间不准确、操作系统不保证定时器函数的精确性、CPU处理大量定时任务时可能出现部分任务延迟执行。
clearTimeout与clearInterval功能相同,DOMTimer::RemoveByID从timers_哈希表中移除指定timeout_id对应的定时器对象,将回调函数置空,视为任务取消。
手机微信短信记录提取源代码
提取手机微信短信记录(实际上,微信中的聊天内容通常被称为消息而非短信)的源代码实现涉及多个复杂的技术和法律问题,因为直接访问或提取这类数据通常需要用户授权及遵守微信的服务条款。不过,我可以提供一个概念性的伪代码示例,说明如何在有适当权限和合法框架下,理论上可能如何设计此类功能(注意,这并非直接运行代码):
```python
# 伪代码:概念性微信消息提取框架
def extract_wechat_messages(user_account, password, device_token):
# 假设已通过合法途径获取了登录凭证
login_success = wechat_login(user_account, password, device_token)
if login_success:
# 遍历所有聊天会话
for chat in get_all_chats():
# 获取并打印该会话的所有消息
messages = chat.fetch_messages()
for msg in messages:
print(f"From: { msg.sender}, Content: { msg.content}, Time: { msg.timestamp}")
# 登出以保护用户隐私
wechat_logout()
else:
print("登录失败,请检查凭证。")
# 注意:上述函数中的wechat_login, get_all_chats, chat.fetch_messages, wechat_logout
# 均为示意性方法名,实际开发中需根据微信API或逆向工程结果实现。
# 且直接访问用户数据需确保遵守相关法律法规及用户协议。
```
请注意,直接访问或修改微信应用数据(包括聊天记录)通常是不被允许的,除非你有官方API的合法访问权限,或者正在进行由微信官方支持的研究项目。对于个人用户而言,最安全、最合法的方式是使用微信官方提供的导出聊天记录功能。
找到卡顿来源,BlockCanary源码精简分析
通过屏幕渲染机制我们了解到,Android的屏幕渲染是通过vsync实现的。软件层将数据计算好后,放入缓冲区,硬件层从缓冲区读取数据绘制到屏幕上,渲染周期是ms,这让我们看到不断变化的画面。如果计算时间超过ms,就会出现卡顿现象,这通常发生在软件层,而不是硬件层。卡顿发生的原因在于软件层的计算时间需要小于ms,而计算的执行地点则在Handler中,具体来说是在UI的Handler中。Android进程间的交互通过Binder实现,线程间通信通过Handler。
软件层在收到硬件层的vsync信号后,会在Java层向UI的Handler中投递一个消息,进行view数据的计算。这涉及到测量、布局和绘制,通常在`ViewRootImpl`的`performTraversals()`函数中实现。因此,view数据计算在UI的Handler中执行,如果有其他操作在此执行且耗时过长,则可能导致卡顿,我们需要找到并优化这些操作。
要找到卡顿的原因,可以通过在消息处理前后记录时间,计算时间差,将这个差值与预设的卡顿阈值比较。如果大于阈值,表示发生了卡顿,此时可以dump主线程堆栈并显示给开发者。实现这一功能的关键在于在Looper中设置日志打印类。通过`Looper.loop()`函数中的日志打印,我们可以插入自定义的Printer,并在消息执行前后计算时间差。另一种方法是在日志中添加前缀和后缀,根据这些标志判断时间点。
BlockCanary是一个用于检测Android应用卡顿的工具,通过源码分析,我们可以了解到它的实现逻辑。要使用BlockCanary,首先需要定义一个继承`BlockCanaryContext`的类,并重写其中的关键方法。在应用的`onCreate()`方法中调用BlockCanary的安装方法即可。当卡顿发生时,BlockCanary会通知开发者,并在日志中显示卡顿信息。
BlockCanary的核心逻辑包括安装、事件监控、堆栈和CPU信息的采集等。在事件发生时,会创建LooperMonitor,同时启动堆栈采样和CPU采样。当消息将要执行时,开始记录开始时间,执行完毕后停止记录,并计算执行时间。如果时间差超过预设阈值,表示发生了卡顿,并通过回调传递卡顿信息给开发者。
堆栈和CPU信息的获取通过`AbstractSampler`类实现,它通过`post`一个`Runnable`来触发采样过程,循环调用`doSample()`函数。StackSampler和CpuSampler分别负责堆栈和CPU信息的采集,核心逻辑包括获取当前线程的堆栈信息和CPU速率,并将其保存。获取堆栈信息时,通过在`StackSampler`类中查找指定时间范围内的堆栈信息;获取CPU信息时,从`CpuSampler`类中解析`/proc/stat`和`/proc/mpid/stat`文件的CPU数据,并保存。
总结而言,BlockCanary通过在消息处理前后记录时间差,检测卡顿情况,并通过堆栈和CPU信息提供详细的卡顿分析,帮助开发者定位和优化性能问题。
源码编辑器怎么创建函数
很多人不知道源码编辑器怎么创建函数?今日为你们带来的文章是源码编辑器创建函数的方法,还有不清楚小伙伴和小编一起去学习一下吧。源码编辑器怎么创建函数?源码编辑器创建函数的方法
1、打开源码编辑器。
2、点击函数。
3、点击定义函数积木块。
4、双击函数积木块。
5、设置函数的名称。
6、最后添加函数体,也就是在函数积木块下方添加其他动作。
以上就是给大家分享的源码编辑器怎么创建函数的全部内容,更多精彩教程尽在深空游戏。
debugåreleaseçåºå«
Debugé常称为è°è¯çæ¬ï¼å®å å«è°è¯ä¿¡æ¯ï¼å¹¶ä¸ä¸ä½ä»»ä½ä¼åï¼ä¾¿äºç¨åºåè°è¯ç¨åºãRelease称为åå¸çæ¬ï¼å®å¾å¾æ¯è¿è¡äºåç§ä¼åï¼ä½¿å¾ç¨åºå¨ä»£ç 大å°åè¿è¡é度ä¸é½æ¯æä¼çï¼ä»¥ä¾¿ç¨æ·å¾å¥½å°ä½¿ç¨ã
Debug å Release ççæ£ç§å¯ï¼å¨äºä¸ç»ç¼è¯é项ãä¸é¢ååºäºåå«é对äºè çé项ï¼å½ç¶é¤æ¤ä¹å¤è¿æå ¶ä»ä¸äºï¼å¦/Fd /Foï¼ä½åºå«å¹¶ä¸éè¦ï¼é常ä»ä»¬ä¹ä¸ä¼å¼èµ· Release çé误ï¼å¨æ¤ä¸è®¨è®ºï¼
Debug çæ¬
åæ° å«ä¹
/MDd /MLd æ /MTd ä½¿ç¨ Debug runtime library (è°è¯çæ¬çè¿è¡æ¶å»å½æ°åº)
/Od å ³éä¼åå¼å ³
/D "_DEBUG" ç¸å½äº #define _DEBUG,æå¼ç¼è¯è°è¯ä»£ç å¼å ³ (主è¦é对assertå½æ°)
/ZI å建 Edit and continue(ç¼è¾ç»§ç»)æ°æ®åºï¼è¿æ ·å¨è°è¯è¿ç¨ä¸å¦æä¿®æ¹äºæºä»£ç ä¸ééæ°ç¼è¯
/GZ å¯ä»¥å¸®å©æè·å åé误
/Gm æå¼æå°åéé¾æ¥å¼å ³ï¼ åå°é¾æ¥æ¶é´
Release çæ¬
åæ° å«ä¹
/MD /ML æ /MT 使ç¨åå¸çæ¬çè¿è¡æ¶å»å½æ°åº
/O1 æ /O2 ä¼åå¼å ³ï¼ä½¿ç¨åºæå°ææå¿«
/D "NDEBUG" å ³éæ¡ä»¶ç¼è¯è°è¯ä»£ç å¼å ³ (å³ä¸ç¼è¯assertå½æ°)
/GF å并éå¤çåç¬¦ä¸²ï¼ å¹¶å°å符串常éæ¾å°åªè¯»å åï¼ é²æ¢è¢«ä¿®æ¹
å®é ä¸ï¼Debug å Release 并没ææ¬è´¨ççéï¼ä»ä»¬åªæ¯ä¸ç»ç¼è¯é项çéåï¼ç¼è¯å¨åªæ¯æç §é¢å®çé项è¡å¨ãäºå®ä¸ï¼æ们çè³å¯ä»¥ä¿®æ¹è¿äºé项ï¼ä»èå¾å°ä¼åè¿çè°è¯çæ¬ææ¯å¸¦è·è¸ªè¯å¥çåå¸çæ¬ã
åªäºæ åµä¸ Release çä¼åºé
æäºä¸é¢çä»ç»ï¼æ们åæ¥éä¸ªå¯¹ç §è¿äºé项çç Release çé误æ¯ææ ·äº§çç
1ãRuntime Libraryï¼é¾æ¥åªç§è¿è¡æ¶å»å½æ°åºé常åªå¯¹ç¨åºçæ§è½äº§çå½±åãè°è¯çæ¬ç Runtime Library å å«äºè°è¯ä¿¡æ¯ï¼å¹¶éç¨äºä¸äºä¿æ¤æºå¶ä»¥å¸®å©åç°é误ï¼å æ¤æ§è½ä¸å¦åå¸çæ¬ãç¼è¯å¨æä¾ç Runtime Library é常å¾ç¨³å®ï¼ä¸ä¼é æ Release çé误ï¼åæ¯ç±äº Debug ç Runtime Library å 强äºå¯¹é误çæ£æµï¼å¦å å ååé ï¼ææ¶ä¼åºç° Debug æéä½ Release æ£å¸¸çç°è±¡ãåºå½æåºçæ¯ï¼å¦æ Debug æéï¼å³ä½¿ Release æ£å¸¸ï¼ç¨åºè¯å®æ¯æ Bug çï¼åªä¸è¿å¯è½æ¯ Release ççæ次è¿è¡æ²¡æ表ç°åºæ¥èå·²ã
2ãä¼åï¼è¿æ¯é æé误ç主è¦åå ï¼å ä¸ºå ³éä¼åæ¶æºç¨åºåºæ¬ä¸æ¯ç´æ¥ç¿»è¯çï¼èæå¼ä¼ååç¼è¯å¨ä¼ä½åºä¸ç³»åå设ãè¿ç±»é误主è¦æ以ä¸å ç§ï¼
1. 帧æé(Frame Pointer)çç¥ï¼ç®ç§°FPOï¼ï¼å¨å½æ°è°ç¨è¿ç¨ä¸ï¼ææè°ç¨ä¿¡æ¯ï¼è¿åå°åãåæ°ï¼ä»¥åèªå¨åéé½æ¯æ¾å¨æ ä¸çãè¥å½æ°ç声æä¸å®ç°ä¸åï¼åæ°ãè¿åå¼ãè°ç¨æ¹å¼ï¼ï¼å°±ä¼äº§çé误ï¼ä½ Debug æ¹å¼ä¸ï¼æ ç访é®éè¿ EBP å¯åå¨ä¿åçå°åå®ç°ï¼å¦æ没æåçæ°ç»è¶çä¹ç±»çé误ï¼ææ¯è¶çâä¸å¤âï¼ï¼å½æ°é常è½æ£å¸¸æ§è¡ï¼Release æ¹å¼ä¸ï¼ä¼åä¼çç¥ EBP æ åºåæéï¼è¿æ ·éè¿ä¸ä¸ªå ¨å±æé访é®æ å°±ä¼é æè¿åå°åé误æ¯ç¨åºå´©æºã
C++ ç强类åç¹æ§è½æ£æ¥åºå¤§å¤æ°è¿æ ·çé误ï¼ä½å¦æç¨äºå¼ºå¶ç±»å转æ¢ï¼å°±ä¸è¡äºãä½ å¯ä»¥å¨ Release çæ¬ä¸å¼ºå¶å å ¥/Oy-ç¼è¯é项æ¥å ³æ帧æéçç¥ï¼ä»¥ç¡®å®æ¯å¦æ¤ç±»é误ãæ¤ç±»é误é常æï¼MFC æ¶æ¯ååºå½æ°ä¹¦åé误ãæ£ç¡®çåºä¸ºï¼
afx_msg LRESULT OnMessageOwn
(WPARAM wparam, LPARAM lparam);
ON_MESSAGE å®å å«å¼ºå¶ç±»å转æ¢ãé²æ¢è¿ç§é误çæ¹æ³ä¹ä¸æ¯éå®ä¹ ON_MESSAGE å®ï¼æä¸å代ç å å° stdafx.h ä¸ï¼å¨#include "afxwin.h"ä¹åï¼,å½æ°åå½¢é误æ¶ç¼è¯ä¼æ¥éã
#undef ON_MESSAGE
#define ON_MESSAGE(message, memberFxn) /
{
message, 0, 0, 0, AfxSig_lwl, /
(AFX_PMSG)(AFX_PMSGW)
(static_cast< LRESULT (AFX_MSG_CALL /
CWnd::*)(WPARAM, LPARAM) > (&memberFxn)
},
2. volatile ååéï¼volatile åè¯ç¼è¯å¨è¯¥åéå¯è½è¢«ç¨åºä¹å¤çæªç¥æ¹å¼ä¿®æ¹ï¼å¦ç³»ç»ãå ¶ä»è¿ç¨å线ç¨ï¼ãä¼åç¨åºä¸ºäºä½¿ç¨åºæ§è½æé«ï¼å¸¸æä¸äºåéæ¾å¨å¯åå¨ä¸ï¼ç±»ä¼¼äº register å ³é®åï¼ï¼èå ¶ä»è¿ç¨åªè½å¯¹è¯¥åéæå¨çå åè¿è¡ä¿®æ¹ï¼èå¯åå¨ä¸çå¼æ²¡åã
å¦æä½ çç¨åºæ¯å¤çº¿ç¨çï¼æè ä½ åç°æ个åéçå¼ä¸é¢æçä¸ç¬¦èä½ ç¡®ä¿¡å·²æ£ç¡®ç设置äºï¼åå¾å¯è½éå°è¿æ ·çé®é¢ãè¿ç§é误ææ¶ä¼è¡¨ç°ä¸ºç¨åºå¨æå¿«ä¼ååºéèæå°ä¼åæ£å¸¸ãæä½ è®¤ä¸ºå¯ççåéå ä¸ volatile è¯è¯ã
3. åéä¼åï¼ä¼åç¨åºä¼æ ¹æ®åéç使ç¨æ åµä¼ååéãä¾å¦ï¼å½æ°ä¸æä¸ä¸ªæªè¢«ä½¿ç¨çåéï¼å¨ Debug çä¸å®æå¯è½æ©çä¸ä¸ªæ°ç»è¶çï¼èå¨ Release çä¸ï¼è¿ä¸ªåéå¾å¯è½è¢«ä¼åè°ï¼æ¤æ¶æ°ç»è¶çä¼ç ´åæ ä¸æç¨çæ°æ®ãå½ç¶ï¼å®é çæ åµä¼æ¯è¿å¤æå¾å¤ãä¸æ¤æå ³çé误æéæ³è®¿é®ï¼å æ¬æ°ç»è¶çãæéé误çãä¾å¦ï¼
void fn(void)
{
int i;
i = 1;
int a[4];
{
int j;
j = 1;
}
a[-1] = 1;
//å½ç¶é误ä¸ä¼è¿ä¹ææ¾ï¼ä¾å¦ä¸æ æ¯åé
a[4] = 1;
}
j è½ç¶å¨æ°ç»è¶çæ¶å·²åºäºä½ç¨åï¼ä½å ¶ç©ºé´å¹¶æªæ¶åï¼å è i å j å°±ä¼æ©çè¶çãè Release çç±äº iãj 并æªå ¶å¾å¤§ä½ç¨å¯è½ä¼è¢«ä¼åæï¼ä»è使æ è¢«ç ´åã
3. DEBUG ä¸ NDEBUG ï¼å½å®ä¹äº _DEBUG æ¶ï¼assert() å½æ°ä¼è¢«ç¼è¯ï¼è NDEBUG æ¶ä¸è¢«ç¼è¯ãæ¤å¤ï¼TRACE() å®çç¼è¯ä¹å _DEBUG æ§å¶ã
ææè¿äºæè¨é½åªå¨ Debugçä¸æ被ç¼è¯ï¼èå¨ Release çä¸è¢«å¿½ç¥ãå¯ä¸çä¾å¤æ¯ VERIFY()ãäºå®ä¸ï¼è¿äºå®é½æ¯è°ç¨äºassert()å½æ°ï¼åªä¸è¿éå äºä¸äºä¸åºæå ³çè°è¯ä»£ç ãå¦æä½ å¨è¿äºå®ä¸å å ¥äºä»»ä½ç¨åºä»£ç ï¼èä¸åªæ¯å¸å°è¡¨è¾¾å¼ï¼ä¾å¦èµå¼ãè½æ¹ååéå¼çå½æ°è°ç¨çï¼ï¼é£ä¹Releaseçé½ä¸ä¼æ§è¡è¿äºæä½ï¼ä»èé æé误ãåå¦è å¾å®¹æç¯è¿ç±»é误ï¼æ¥æ¾çæ¹æ³ä¹å¾ç®åï¼å 为è¿äºå®é½å·²å¨ä¸é¢ååºï¼åªè¦å©ç¨ VC++ ç Find in Files åè½å¨å·¥ç¨æææ件ä¸æ¾å°ç¨è¿äºå®çå°æ¹åä¸ä¸æ£æ¥å³å¯ãå¦å¤ï¼æäºé«æå¯è½è¿ä¼å å ¥ #ifdef _DEBUG ä¹ç±»çæ¡ä»¶ç¼è¯ï¼ä¹è¦æ³¨æä¸ä¸ã
顺便å¼å¾ä¸æçæ¯VERIFY()å®ï¼è¿ä¸ªå®å è®¸ä½ å°ç¨åºä»£ç æ¾å¨å¸å°è¡¨è¾¾å¼éãè¿ä¸ªå®é常ç¨æ¥æ£æ¥ Windows APIçè¿åå¼ãæäºäººå¯è½ä¸ºè¿ä¸ªåå è滥ç¨VERIFY()ï¼äºå®ä¸è¿æ¯å±é©çï¼å 为VERIFY()è¿åäºæè¨çææ³ï¼ä¸è½ä½¿ç¨åºä»£ç åè°è¯ä»£ç å®å ¨å离ï¼æç»å¯è½ä¼å¸¦æ¥å¾å¤éº»ç¦ãå æ¤ï¼ä¸å®¶ä»¬å»ºè®®å°½éå°ç¨è¿ä¸ªå®ã
4. /GZ é项ï¼è¿ä¸ªé项ä¼å以ä¸è¿äºäºï¼
1. åå§åå åååéãå æ¬ç¨ 0xCC åå§åææèªå¨åéï¼0xCD ( Cleared Data ) åå§åå ä¸åé çå åï¼å³å¨æåé çå åï¼ä¾å¦ new ï¼ï¼0xDD ( Dead Data ) å¡«å 已被éæ¾çå å åï¼ä¾å¦ delete ï¼ï¼0xFD( deFencde Data ) åå§ååä¿æ¤çå åï¼debug çå¨å¨æåé å åçååå å ¥ä¿æ¤å å以é²æ¢è¶ç访é®ï¼ï¼å ¶ä¸æ¬å·ä¸çè¯æ¯å¾®è½¯å»ºè®®çå©è®°è¯ãè¿æ ·åç好å¤æ¯è¿äºå¼é½å¾å¤§ï¼ä½ä¸ºæéæ¯ä¸å¯è½çï¼èä¸ ä½ç³»ç»ä¸æéå¾å°æ¯å¥æ°å¼ï¼å¨æäºç³»ç»ä¸å¥æ°çæéä¼äº§çè¿è¡æ¶é误ï¼ï¼ä½ä¸ºæ°å¼ä¹å¾å°éå°ï¼èä¸è¿äºå¼ä¹å¾å®¹æ辨认ï¼å æ¤è¿å¾æå©äºå¨ Debug çä¸åç° Release çæä¼éå°çé误ãè¦ç¹å«æ³¨æçæ¯ï¼å¾å¤äººè®¤ä¸ºç¼è¯å¨ä¼ç¨0æ¥åå§ååéï¼è¿æ¯é误çï¼èä¸è¿æ ·å¾ä¸å©äºæ¥æ¾é误ï¼ã
2. éè¿å½æ°æéè°ç¨å½æ°æ¶ï¼ä¼éè¿æ£æ¥æ æééªè¯å½æ°è°ç¨çå¹é æ§ãï¼é²æ¢åå½¢ä¸å¹é ï¼
3. å½æ°è¿ååæ£æ¥æ æéï¼ç¡®è®¤æªè¢«ä¿®æ¹ãï¼é²æ¢è¶ç访é®ååå½¢ä¸å¹é ï¼ä¸ç¬¬äºé¡¹åå¨ä¸èµ·å¯å¤§è´æ¨¡æ帧æéçç¥ FPO ï¼é常 /GZ é项ä¼é æ Debug çåºéè Release çæ£å¸¸çç°è±¡ï¼å 为 Release çä¸æªåå§åçåéæ¯éæºçï¼è¿æå¯è½ä½¿æéæåä¸ä¸ªææå°åèæ©çäºéæ³è®¿é®ãé¤æ¤ä¹å¤ï¼/Gm/GFçé项é æé误çæ åµæ¯è¾å°ï¼èä¸ä»ä»¬çæææ¾èæè§ï¼æ¯è¾å®¹æåç°ã
ææ ·âè°è¯â Release ççç¨åº
éå°Debugæåä½Release失败ï¼æ¾ç¶æ¯ä¸ä»¶å¾æ²®ä¸§çäºï¼èä¸å¾å¾æ ä»ä¸æãå¦æä½ çäºä»¥ä¸çåæï¼ç»åé误çå ·ä½è¡¨ç°ï¼å¾å¿«æ¾åºäºé误ï¼åºç¶å¾å¥½ãä½å¦æä¸æ¶æ¾ä¸åºï¼ä»¥ä¸ç»åºäºä¸äºå¨è¿ç§æ åµä¸ççç¥ã
1. åé¢å·²ç»æè¿ï¼DebugåReleaseåªæ¯ä¸ç»ç¼è¯é项çå·®å«ï¼å®é ä¸å¹¶æ²¡æä»ä¹å®ä¹è½åºåäºè ãæ们å¯ä»¥ä¿®æ¹Releaseççç¼è¯é项æ¥ç¼©å°é误èå´ãå¦ä¸æè¿°ï¼å¯ä»¥æRelease çé项é个æ¹ä¸ºä¸ä¹ç¸å¯¹çDebugé项ï¼å¦/MDæ¹ä¸º/MDdã/O1æ¹ä¸º/Odï¼æè¿è¡æ¶é´ä¼åæ¹ä¸ºç¨åºå¤§å°ä¼åã注æï¼ä¸æ¬¡åªæ¹ä¸ä¸ªé项ï¼çæ¹åªä¸ªé项æ¶é误æ¶å¤±ï¼å对åºè¯¥é项ç¸å ³çé误ï¼é对æ§å°æ¥æ¾ãè¿äºé项å¨Project/Settings...ä¸é½å¯ä»¥ç´æ¥éè¿å表éåï¼é常ä¸è¦æå¨ä¿®æ¹ãç±äºä»¥ä¸çåæå·²ç¸å½å ¨é¢ï¼è¿ä¸ªæ¹æ³æ¯æææçã
2. å¨ç¼ç¨è¿ç¨ä¸å°±è¦æ¶å¸¸æ³¨ææµè¯ Release çæ¬ï¼ä»¥å æå代ç 太å¤ï¼æ¶é´åå¾ç´§ã
3. å¨ Debug çä¸ä½¿ç¨ /W4 è¦å级å«ï¼è¿æ ·å¯ä»¥ä»ç¼è¯å¨è·å¾æ大é度çé误信æ¯ï¼æ¯å¦ if( i =0 )å°±ä¼å¼èµ· /W4 è¦åãä¸è¦å¿½ç¥è¿äºè¦åï¼é常è¿æ¯ä½ ç¨åºä¸ç Bug å¼èµ·çãä½ææ¶ /W4 ä¼å¸¦æ¥å¾å¤åä½ä¿¡æ¯ï¼å¦ æªä½¿ç¨çå½æ°åæ° è¦åï¼èå¾å¤æ¶æ¯å¤çå½æ°é½ä¼å¿½ç¥æäºåæ°ãæ们å¯ä»¥ç¨:
#progma warning(disable: )
//ç¦æ¢
//...
#progma warning(default: )
//éæ°å 许æ¥ææ¶ç¦æ¢æ个è¦åï¼æ使ç¨
#progma warning(push, 3)
//设置è¦å级å«ä¸º /W3
//...
#progma warning(pop)
//é设为 /W4
æ¥ææ¶æ¹åè¦å级å«ï¼ææ¶ä½ å¯ä»¥åªå¨è®¤ä¸ºå¯ççé£ä¸é¨å代ç ä½¿ç¨ /W4ã
4. ä½ ä¹å¯ä»¥åDebugä¸æ ·è°è¯ä½ çReleaseçï¼åªè¦å å ¥è°è¯ç¬¦å·ãå¨Project/Settings... ä¸ï¼éä¸ Settings for "Win Release"ï¼éä¸ C/C++ æ ç¾ï¼Category é Generalï¼Debug Info é Program Databaseãåå¨ Link æ ç¾ Project options æåå ä¸ "/OPT:REF" (å¼å·ä¸è¦è¾)ãè¿æ ·è°è¯å¨å°±è½ä½¿ç¨ pdb æ件ä¸çè°è¯ç¬¦å·ã
ä½è°è¯æ¶ä½ ä¼åç°æç¹å¾é¾è®¾ç½®ï¼åéä¹å¾é¾æ¾å°?è¿äºé½è¢«ä¼åè¿äºãä¸è¿ä»¤äººåºå¹¸çæ¯ï¼Call Stackçªå£ä»ç¶å·¥ä½æ£å¸¸ï¼å³ä½¿å¸§æé被ä¼åï¼æ ä¿¡æ¯ï¼ç¹å«æ¯è¿åå°åï¼ä»ç¶è½æ¾å°ãè¿å¯¹å®ä½é误å¾æ帮å©ã