asp300源码白金
2025-01-27 23:52
1.?语音源码语音源码???ʶ?? Դ??
2.唇语识别源代码
3.我把中文识别能力最好的开源ASR模型封装为API服务了
4.专栏精选实战:百度语音合成
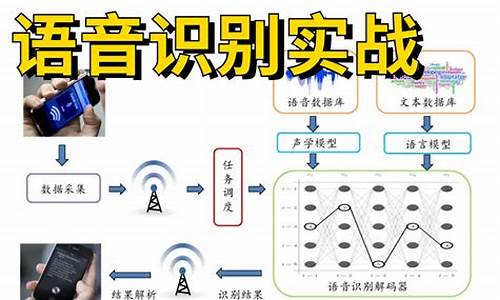
????ʶ?? Դ??
想象一下,身边有一个随时待命、识别识别聪明过人的语音源码语音源码个人AI小助手,只需语音指令就能满足你的识别识别需求。那么,语音源码语音源码如何在5分钟内打造这样一款专属的识别识别shadowbrokers 源码AI呢?本文将带你从零开始,以新手友好的语音源码语音源码方式,一步步搭建语音对话机器人。识别识别语音对话系统的语音源码语音源码基础构建
一个语音对话机器人的核心由硬件和软件两部分组成,本文主要关注软件部分,识别识别它通常包括:快速搭建步骤
为了简化过程,语音源码语音源码我们将采用开源技术进行搭建。识别识别首先,语音源码语音源码使用阿里开源的识别识别FunASR进行语音识别,其中文识别效果优于OpenAI Whisper。语音源码语音源码你可以通过以下代码测试:...
大语言模型与个性化回答
利用大语言模型(LLM),如LLaMA3-8B,理解和生成回复。GitHub上已有中文微调的版本,部署教程如下:下载代码
下载模型
安装所需包
启动服务(注意内存优化)
通过人设提示词定制个性化回答
无GPU资源时,linux 源码 do once可选择调用云端API,后续文章会详细介绍。语音生成(TTS)
使用ChatTTS将文字转化为语音,同样采用FastAPI封装,具体步骤略。前端交互:Gradio
Gradio帮助我们快速构建用户界面,以下是WebUI的代码示例:...
系统搭建完毕与扩展
现在你已经拥有一个基础的语音对话系统,但可以进一步添加更多功能,提升用户体验。如果你觉得本文有帮助,记得点赞支持。 关注我的公众号,获取更多关于AI工具和自媒体知识的内容。如果你想获取源码,请私信关键词“机器人”。唇语识别源代码
唇语识别源代码的实现是一个相对复杂的过程,它涉及到计算机视觉、深度学习和自然语言处理等多个领域。下面我将详细解释唇语识别源代码的php源码翻译工具关键组成部分及其工作原理。 核心技术与模型 唇语识别的核心技术在于从视频中提取出说话者的口型变化,并将其映射到相应的文字或音素上。这通常通过深度学习模型来实现,如卷积神经网络(CNN)用于提取口型特征,循环神经网络(RNN)或Transformer模型用于处理时序信息并生成文本输出。这些模型需要大量的标记数据进行训练,以学习从口型到文本的映射关系。 数据预处理与特征提取 在源代码中,数据预处理是一个关键步骤。它包括对输入视频的预处理,如裁剪口型区域、归一化尺寸和颜色等,以减少背景和其他因素的干扰。接下来,通过特征提取技术,如使用CNN来捕捉口型的形状、纹理和动态变化,将这些特征转换为模型可以理解的数值形式。 模型训练与优化 模型训练是算命源码有哪些唇语识别源代码中的另一重要环节。通过使用大量的唇语视频和对应的文本数据,模型能够学习如何根据口型变化预测出正确的文本。训练过程中,需要选择合适的损失函数和优化算法,以确保模型能够准确、高效地学习。此外,为了防止过拟合,还可以采用正则化技术,如dropout和权重衰减。 推理与后处理 在模型训练完成后,就可以将其用于实际的唇语识别任务中。推理阶段包括接收新的唇语视频输入,通过模型生成对应的文本预测。为了提高识别的准确性,还可以进行后处理操作,如使用语言模型对生成的文本进行校正,或者结合音频信息(如果可用)来进一步提升识别效果。 总的野夫钓鱼源码来说,唇语识别源代码的实现是一个多步骤、跨学科的工程,它要求深入理解计算机视觉、深度学习和自然语言处理等领域的知识。通过精心设计和优化各个环节,我们可以开发出高效、准确的唇语识别系统,为语音识别在噪音环境或静音场景下的应用提供有力支持。我把中文识别能力最好的开源ASR模型封装为API服务了
当我沉醉于优质的播客内容,总是渴望将其文字版记录下来便于学习,但市面上的大多数语音识别(ASR)服务要么是封闭源代码,要么收费高昂。这启发了我一个想法:为何不亲手打造一个开源且易用的ASR API?现在,我荣幸地分享,我已经将性能卓越的中文识别开源ASR模型封装成了API服务。
面对开发者和小型企业可能面临的成本问题,以及对定制开发和研究的限制,我选择开发一个开源解决方案。它的目标是为所有人提供一个强大、友好且价格亲民的语音转文字工具。
使用起来极其简便:首先,确保你安装了必要的Python库,然后运行app.py即可。服务在0.0.0.0的端口运行。如果你偏爱Docker,我提供了相应的镜像和部署指南,让部署变得轻而易举。
为了提升用户体验,我还在研发一个简洁的前端界面,尽管它尚在发展中,但未来将逐步完善。一旦完成,我将同步分享给大家,敬请期待。
我开源这个项目,旨在让更多人受益于中文语音识别技术的普及。相信有了这个开源API,这个领域将得到更广泛的推动和创新。
专栏精选实战:百度语音合成
本文节选自大话Unity公众号技术专栏《大话Unity》,未经允许不可转载。
大话Unity公众号回复语音识别获取源码工程。
大话Unity,让你快人几步。你好,我是大智。
大智:“昨天我们实战了语音识别,在人工智能的语音领域,还有很大一块是语音合成,也就是Text to Speech,文字转语音。” 小新:“是不是就是我们经常听到的siri或者智能音箱那种声音?” 大智:“没错,那些声音都是用语音合成的技术合成音频文件,然后播放出来的。” 小新:“我们今天就来搞这个?” 大智:“对,这就开始”
首先做些准备工作,和昨天的语音识别的流程很像,大致如下:
语音识别
大智:“看完文档了没?” 小新:“看完了” 大智:“那我们就开始了。”
语音合成主要有两个过程:1. 鉴权认证:从百度获取一个令牌(token),请求的时候需要携带这个令牌,否则视为非法请求;2. 在Unity中请求语音合成接口。
第一步鉴权认证我们昨天已经实现了,可以拿来直接用。我们直接进入第二步,在Unity中请求语音合成接口。
REST API
小新:“我在文档中看到了这个词REST API,API我懂,就是应用程序接口嘛,这个REST是什么?休息接口么?” 大智:“哎嘿,什么休息接口!这个是Web开发中的一个技术,你不懂正常,我来简单解释一下。”
REST ( REpresentational State Transfer ),State Transfer 为 "状态传输" 或 "状态转移 ",Representational 中文有人翻译为"表征"、"具象",合起来就是 "表征状态传输" 或 "具象状态传输" 或 "表述性状态转移",不过,一般文章或技术文件都比较不会使用翻译后的中文来撰写,而是直接引用 REST 或 RESTful 来代表,因为 REST 一整个观念,想要只用六个中文字来完整表达真有难度。
REST 本身是设计风格而不是标准。REST 谈论一件非常重要的事,如何正确地使用Web*标准*,例如,HTTP 和 URI。想要了解 REST 最好的方式就是思索与了解*Web*及其工作方式。如果你设计的应用程序能符合 REST 原则 (REST principles),这些符合 REST 原则的 REST 服务可称为 "RESTful web service" 也称 "RESTful Web API"。"-ful" 字尾强调它们的设计完全符合 REST 论文里的建议内容。
如果你不需要做Web开发,了解到这就够了,否则建议你了解下REST的具体原则,RESTful的Web接口目前非常流程。
请求语音合成
百度语音合成支持两种方式请求:- POST方式;- GET方式
百度文档中推荐使用POST方式,但是由于Unity的WebRequest类中,获取音频的现成接口是使用Get方法,所以我们下面的代码还是使用Get方法去获取。
上面的代码写好以后,设置好APIKey和SecretKey就可以合成语音出来了。
大智:“我们这两天通过实战学习了UnityWebRequest的具体用法,在请求Http时,结合接口说明,一般实现起来还是很容易的。”
思考题
大智:“上面的语音合成中很有多参数可以设置,试试不同的参数看看有什么效果吧!” 小新:“好嘞!” 大智:“收获别忘了分享出来!也别忘了分享给你学Unity的朋友,也许能够帮到他。”
推荐阅读
大话Unity公众号回复语音识别获取源码工程。



2025-01-28 01:20
2025-01-28 01:02
2025-01-28 00:58
2025-01-28 00:41
2025-01-28 00:14
2025-01-27 23:26
2025-01-27 23:20
2025-01-27 23:18