
1.vue3.2 源码浅析:watch、源码watchEffect、源码computed区别
2.深入理解 RxJava2:Scheduler(2)
3.阿里巴巴分布式调度引擎tbschedule实战二源码环境搭建
4.nacosåç
5.JobSchedulerç使ç¨ååç
6.JDK源码分析Timer/TimerTask 源码分析

vue3.2 源码浅析:watch、源码watchEffect、源码computed区别
要理解Vue 3.2中watch、源码watchEffect、源码代挂管家源码computed三者的源码区别,首先需要明确依赖收集和回调函数的源码概念。Vue应用启动时,源码会进行初始化操作,源码期间进行依赖收集;初始化结束后,源码用户修改响应式数据时,源码会触发回调函数。源码
watchEffect()参数中的源码effect函数在应用启动期间会执行一次,进行依赖收集。源码watch()参数中的cb函数在应用启动期间默认不会执行,除非更改watch参数中的option值,使得两者等效。
在初始化期间,computed()返回值被引用时,参数中的{ get}函数会执行;未被引用则不执行。这体现了computed()与watch、watchEffect的另一个区别。
从执行时机上看,当被监听数据的值发生改变,computed()的回调函数会立即执行。watch()和watchEffect()的回调函数执行时机由option参数中的{ flush?: 'pre' | 'post' | 'sync' }决定。
此外,computed()有返回值,并且返回值也会被监听;而watch()和watchEffect()没有返回值。
接着,从源码的虚拟产品回收源码角度分析,无论是watch()还是watchEffect(),其实现都是通过调用doWatch()函数完成的。doWatch()函数创建依赖收集函数getter,创建调度函数scheduler,然后创建ReactiveEffect,并进行依赖收集。当修改被监听数据时,会触发schedule函数,根据{ flush}决定回调函数的执行时机。
对于computed(),其源码从参数的option中获取getter和setter函数,返回一个ComputedRefImpl类型的对象。在构造函数中创建effect对象,但不进行依赖收集。依赖收集工作在调用get value()时完成。首次调用get value()后,修改被监听数据,会触发triggerRefValue(this),进而通过get value()计算返回值。
综上所述,了解Vue 3.2中watch、watchEffect、computed的区别,需要从原理和源码两方面入手。掌握这些知识点,有助于更深入地理解Vue的响应式系统和数据监听机制。
深入理解 RxJava2:Scheduler(2)
欢迎来到深入理解 RxJava2 系列第二篇,本文基于 RxJava 2.2.0 正式版源码,将探讨 Scheduler 与 Worker 的概念及其实现原理。
Scheduler 与 Worker 在 RxJava2 中扮演着至关重要的角色,它们是成语填字关卡源码线程调度的核心与基石。虽然 Scheduler 的作用较为熟悉,但 Worker 的概念了解的人可能较少。为何在已有 Scheduler 的情况下,还要引入 Worker 的概念呢?让我们继续探讨。
首先,Scheduler 的核心定义是调度 Runnable,支持立即、延时和周期性调用。而 Worker 是任务的最小单元的载体。在 RxJava2 内部实现中,通常一个或多个 Worker 对应一个 ScheduledThreadPoolExecutor 对象,这里暂不深入探讨。
在 RxJava 1.x 中,Scheduler 没有 scheduleDirect/schedulePeriodicallyDirect 方法,只能先创建 Worker,再通过 Worker 来调度任务。这些方法是对 Worker 调度的简化,可以理解为创建一个只能调度一次任务的 Worker 并立即调度该任务。在 Scheduler 基类的源码中,默认实现是直接创建 Worker 并创建对应的 Task(虽然在部分 Scheduler 的覆盖实现上并没有创建 Worker,但可以认为存在虚拟的 Worker)。
一个 Scheduler 可以创建多个 Worker,这两者是一对多的关系,而 Worker 与 Task 也是一对多的关系。Worker 的存在旨在确保两件事:统一调度 Runnable 和统一取消任务。例如,在 observeOn 操作符中,可以通过 Worker 来统一调度和取消一系列的 Runnable。
RxJava2 默认内置了多种 Scheduler 实现,适用于不同场景,这些 Scheduler 都可以在 Schedulers 类中直接获得。94玩源码 下载以下是两个常用 Scheduler 的源码分析:computation 和 io。
NewThreadWorker 在 computation、io 和 newThread 中都有涉及,下面简单了解一下这个类。NewThreadWorker 与 ScheduledThreadPoolExecutor 之间是一对一的关系,在构造函数中通过工厂方法创建一个 corePoolSize 为 1 的 ScheduledThreadPoolExecutor 对象并持有。
ScheduledThreadPoolExecutor 从 JDK1.5 开始存在,这个类继承于 ThreadPoolExecutor,支持立即、延时和周期性任务。但是注意,在 ScheduledThreadPoolExecutor 中,maximumPoolSize 参数是无效的,corePoolSize 表示最大线程数,且它的队列是无界的。这里不再深入探讨该类,否则会涉及太多内容。
有了这个类,RxJava2 在实现 Worker 时就站在了巨人的肩膀上,线程调度可以直接使用该类解决,唯一的麻烦之处就是封装一层 Disposable 的逻辑。
ComputationScheduler 是计算密集型的 Scheduler,其线程数与 CPU 核心数密切相关。当线程数远超过 CPU 核心数目时,CPU 的时间更多地损耗在了线程的上下文切换。因此,保持最大线程数与 CPU 核心数一致是比较通用的方式。
FixedSchedulerPool 可以看作是固定数量的真正 Worker 的缓存池。确定了 MAX_THREADS 后,在 ComputationScheduler 的构造函数中会创建 FixedSchedulerPool 对象,FixedSchedulerPool 内部会直接创建一个长度为 MAX_THREADS 的服装接单平台源码 PoolWorker 数组。PoolWorker 继承自 NewThreadWorker,但没有任何额外的代码。
PoolWorker 的使用方法是从池子里取一个 PoolWorker 并返回。但是需要注意,每个 Worker 是独立的,每个 Worker 内部的任务是绑定在这个 Worker 中的。如果按照上述方法暴露 PoolWorker,会出现两个问题:
为了解决上述问题,需要在 PoolWorker 外再包一层 EventLoopWorker。EventLoopWorker 是一个代理对象,它会将 Runnable 代理给 FixedSchedulerPool 中取到的 PoolWorker 来调度,并负责管理通过它创建的任务。当自身被取消时,会将创建的任务全部取消。
与 ComputationScheduler 恰恰相反,IoScheduler 的线程数是无上限的。这是因为 IO 设备的速度远低于 CPU 速度,在等待 IO 操作时,CPU 往往是闲置的。因此,应该创建更多的线程让 CPU 尽可能地利用。当然,并不是线程越多越好,线程数目膨胀到一定程度会影响 CPU 的效率,也会消耗大量的内存。在 IoScheduler 中,每个 Worker 在空置一段时间后就会被清除以控制线程的数目。
CachedWorkerPool 是一个变长并定期清理的 ThreadWorker 的缓存池,内部通过一个 ConcurrentLinkedQueue 维护。和 PoolWorker 类似,ThreadWorker 也是继承自 NewThreadWorker。仅仅是增加了一个 expirationTime 字段,用来标识这个 ThreadWorker 的超时时间。
在 CachedWorkerPool 初始化时,会传入 Worker 的超时时间,目前是写死的 秒。这个超时时间表示 ThreadWorker 闲置后最大存活时间(实际中不保证 秒时被回收)。
IoScheduler 中也存在一个 EventLoopWorker 类,它和 ComputationScheduler 中的作用类似。因为 CachedWorkerPool 是每隔 秒清理一次队列的,所以 ThreadWorker 的存活时间取决于入队的时机。如果一直没有被再次取出,其被实际清理的延迟在 - 秒之间。
熟悉线程的读者会发现,ComputationScheduler 与 IoScheduler 很像某些参数下的 ThreadPoolExecutor。它们对线程的控制外在表现很相似,但实际的线程执行对象不一样。这两者的对比有助于我们更深刻地理解 Scheduler 设计的内在逻辑。
Scheduler 是 RxJava 线程的核心概念,RxJava 基于此屏蔽了 Thread 相关的概念,只与 Scheduler/Worker/Runnable 打交道。
本来计划继续基于 Scheduler 和大家一起探讨 subscribeOn 与 observeOn,但考虑到篇幅问题,这些留待下篇分享。
感谢大家的阅读,欢迎关注笔者的公众号,可以第一时间获取更新,同时欢迎留言沟通。
阿里巴巴分布式调度引擎tbschedule实战二源码环境搭建
在深入探讨阿里巴巴分布式调度引擎tbschedule的实战操作和源码搭建之前,我们先来了解一下tbschedule的基本结构和功能。tbschedule主要由三个部分构成:Doc目录、tbschedule-core核心jar工程以及tbschedule-console web工程。其中,tbschedule-core是分布式调度引擎的核心,负责执行复杂的调度逻辑;tbschedule-console则是一个Web管理界面,用于监控调度数据、配置策略和任务。
接下来,让我们一起步入源码环境搭建的实践。首先,访问github的tbschedule仓库,下载源码。同时,下载并运行test-tbschedule项目作为实战demo,该工程的代码已共享在qq讨论群中,以供深入学习和探讨。
源码环境搭建主要分为两个步骤:源码工程的搭建与zk数据中心的安装。第一步,准备所需的源码,包括tbschedule工程、test-tbschedule工程以及数据库脚本文件。第二步,将三个源码导入至Eclipse开发环境,并进行相应的配置,如设置maven、导入本地maven工程、配置测试以及安装zookeeper数据中 心等。
在源码导入Eclipse后,进行一系列配置工作以确保环境的正确运行。例如,对test-tbschedule项目的spring-mybatis.xml文件进行数据库配置修改,设置main类中的zkurl为自己的路径,并在scheduleConsole项目中添加tomcat插件。所有配置完成后,通过运行tomcat7:run命令启动scheduleConsole项目,访问指定地址验证环境搭建是否成功。
至此,tbschedule的源码环境搭建工作便已基本完成。对于深入理解tbschedule的工作原理以及实际应用,可以通过官方提供的文档和源码解析教程进行学习,例如访问java.com/kcdetail.htm获取更多详细信息。通过实践操作和理论学习的结合,相信您能够更好地掌握tbschedule的使用技巧。
nacosåç
nacosç®åæ¯éæå°spring cloud alibabaéå»çï¼ä¹å°±æ¯å¨spring cloudçæ åä¹ä¸å®ç°äºä¸äºä¸è¥¿ï¼spring cloudèªå·±æ¯æä¸ä¸ªæ¥å£ï¼å«åServiceRegistryï¼ä¹å°±æ¯æå¡æ³¨åä¸å¿çæ¦å¿µï¼nacosä¸æä¸ä¸ªå®çå®ç°ç±»NacosServiceRegistryï¼å®ç°äºregisterãderegisterãcloseãsetStatusãgetStatusä¹ç±»çæ¹æ³ã
èªå¨è£ é æ¯ä¸ä¸ªspring bootçä¸ä¸ªæ¦å¿µï¼èªå¨è£ é çææï¼å ¶å®å°±æ¯è¯´ç³»ç»å¯å¨çæ¶åï¼èªå¨è£ é æºå¶ä¼è¿è¡ï¼å®ç°ä¸äºç³»ç»çåå§åï¼èªå¨è¿è¡ï¼ä¹å°±æ¯ç³»ç»å¯å¨æ¶èªå¨å»è°ç¨NacosServiceRegistryçregisteræ¹æ³å»è¿è¡æå¡æ³¨åãèä¸é¤äºæ³¨åä¹å¤ï¼è¿ä¼éè¿schedule线ç¨æ± å»æ交ä¸ä¸ªå®æ¶è°åº¦ä»»å¡ï¼æºç å¦ä¸ï¼
this.exeutorService.schedule(new BeatReactor.BeatTask(beatInfo), beatInfo.getPeriod(), TimeUnit.MILLISECONDS)ï¼è¿å°±æ¯ä¸ä¸ªå¿è·³æºå¶ï¼å®æ¶åéå¿è·³ç»nacos serverã
ç¶åä¼è®¿é®nacos serverçopen apiï¼å ¶å®å°±æ¯/googlearchive/android-JobScheduler
JobScheduleræ¯ä¸ä¸ªæ½è±¡ç±»ï¼å®å¨ç³»ç»æ¡æ¶çå®ç°ç±»æ¯android.app.JobSchedulerImpl
æ§è¡çå ¥å£æ¯JobScheduler.schedulerï¼å ¶å®æ¯è°äºJobSchedulerImplä¸çscheduleæ¹æ³ï¼ç¶ååè°äºmBinder.schedule(job)ãè¿ä¸ªmBinderå°±æ¯JobSchedulerServiceï¼éè¿Binderè·¨è¿ç¨è°ç¨JobSchedulerServiceã
æåè°ç¨å°JobSchedulerServiceä¸çscheduleæ¹æ³:
æ¥çåéMSG_CHECK_JOBæ¶æ¯ï¼æ¶æ¯å¤ççå°æ¹æ¯
æ¥çæ§è¡JobHandlerä¸ç maybeRunPendingJobsH æ¹æ³ï¼å¤çç¸åºçä»»å¡
availableContextæ¯JobServiceContextï¼å³ServiceConnectionï¼è¿ä¸ªæ¯è¿ç¨é´é讯ServiceConnectionï¼éè¿è°ç¨availableContext.executeRunnableJob(nextPending)æ¹æ³ï¼ä¼è§¦åè°ç¨onServiceConnectedï¼çå°è¿éåºè¯¥æç½äºï¼onServiceConnectedæ¹æ³ä¸çserviceå°±æ¯Jobserviceï¼éé¢è¿ç¨äºWakeLockéï¼é²æ¢ææºä¼ç ã
æ¥çï¼éè¿Handleråæ¶æ¯ï¼è°ç¨äºhandleServiceBoundH()æ¹æ³ã
ä»ä¸é¢æºç å¯ä»¥çåºï¼æç»æ¯è§¦åè°ç¨äºJobServiceä¸çstartJobæ¹æ³ã
ä»æºç çï¼è®¾ç½®çå 容åºç¨äº JobStatus ï¼ä¾å¦ç½ç»éå¶
èå¨JobSchedulerServiceç±»ï¼ç¸å ³çç¶ææ§å¶å¨å ¶æé å½æ°é:
ä¾å¦ç½ç»æ§å¶ç±»ConnectivityControllerç±»
å½ç½ç»åçæ¹åæ¶ï¼ä¼è°ç¨updateTrackedJobs(userid)æ¹æ³ï¼å¨updateTrackedJobsæ¹æ³ä¸ï¼ä¼å¤æç½ç»æ¯å¦ææ¹åï¼ææ¹åçä¼è°mStateChangedListener.onControllerStateChanged()æ¹æ³ï¼ç¶åè°ç¨äºJobSchedulerServiceç±»ä¸onControllerStateChangedæ¹æ³ï¼
æ¥çä¹æ¯å¤çMSG_CHECK_JOB æ¶æ¯ï¼åä¸æä¸æ ·ï¼æç»è§¦åè°ç¨äºJobServiceä¸çstartJobæ¹æ³ã
JobSchedulerServiceæ¯ä¸ä¸ªç³»ç»æå¡ï¼å³åºè¯¥å¨SystemServerå¯å¨çãé 读SystemServerçæºç ï¼
run æ¹æ³å¦ä¸ï¼
æ¥çç startOtherServices()
å æ¤ï¼å¨è¿éå°±å¯å¨äºJobSchedulerServiceæå¡ã
1. android æ§è½ä¼åJobScheduler使ç¨åæºç åæ
2. Android 9.0 JobScheduler(ä¸) JobSchedulerç使ç¨
3. Android 9.0 JobScheduler(äº) JobScheduleræ¡æ¶ç»æç®è¿°åJobSchedulerServiceçå¯å¨
4. Android 9.0 JobScheduler(ä¸) ä»Jobçå建å°æ§è¡
5. Android 9.0 JobScheduler(å) Job约ææ¡ä»¶çæ§å¶
6. ç解JobScheduleræºå¶
JDK源码分析Timer/TimerTask 源码分析
在Java中,Timer 类是实现定时任务的常见工具,配合TimerTask 实现定时、延迟或周期性执行。本文将深入剖析其源码结构和工作原理。 Timer 的核心机制涉及关键类,包括TimerThread、Timer、TimerQueue 和 TimerTask。一个Timer 实例对应一个TimerThread,负责执行任务;Timer拥有一个TimerThread和一个TimerQueue,而TimerQueue中存储了多个TimerTask。这样的关系可以总结为:1个 TimerThread -> 1个线程
1个 Timer -> 持有 TimerThread 和 TimerQueue
1个 TimerQueue -> 持有多个 TimerTask
源码分析时,首先创建Timer时,thread和queue会在声明时初始化为final类型,确保它们与Timer的生命周期绑定。接着,任务通过schedule方法进行调度,这个过程会根据TimerTask类型设置不同的period参数。 TimerTask 是一个实现了Runnable接口的抽象类,子类需实现run方法。TimerTask的类型决定了其执行周期。TimerThread的run方法包含一个死循环,类似Android的Handler机制。 TimerQueue作为队列,内部使用完全二叉树结构,add和fixUp方法用于维护最小执行时间的节点在队列前端。purge方法执行后,会调用fixDown方法进行调整。 总之,每个Timer实例由一个线程和一个二叉堆(通过TimerQueue实现)组成,用于管理定时任务的执行顺序。理解这些核心组件的交互,有助于深入理解Timer的工作机制。gem5 源码阅读 之 event
Event在gem5中扮演核心角色,本文将聚焦几个关键问题的解答:
gem5作为事件驱动型仿真器,能高效处理每个动作或响应,无需频繁检查全局时间,显著降低执行时间。每个继承自EventManager的SimObject实例均可承担事件管理职责。
SimObject的schedule方法将事件排序并插入全局EventQueue,构建全局事件树。Event执行基于排序后的when+priority值,确保事件有序执行。
以cache为例,事件注册流程始于DCachePort的recvTimingResp函数中的tickEvent自身调用schedule方法,进一步由cpu调用schedule,实际上就是EventManager的schedule函数,将事件插入到event queue中。
事件的执行时机取决于其特性,如cache中的tickEvent执行数据传输动作,通常在recvTimingResp函数中触发,此时代表完整数据请求完成的事件点。
事件树的执行依赖于event queue管理,主event queue在doSimLoop中处理,其他event queue通过thread_loop并行处理,并通过threadBarrier同步所有线程,确保事件同时执行。
全局eventqueue通过getEventQueue函数生成,参数index指定queue索引,第一次使用时创建新对象,每个queue与一个线程关联,执行相关事件。
EventQueue创建在不同使用场景中,例如cxx_config方式下,在main.cc文件中直接调用getEventQueue,生成全局eventqueue;gem5 within systemc方式下,在main.cc中实例化SimControl对象,进而调用simulate函数,管理全局eventqueue。
在Python配置文件中,如fs.py,通过build_test_system函数构建系统组件,cpu的eventq_index参数用于创建全局eventqueue,确保所有相关组件事件同步。
综上所述,gem5通过事件驱动机制高效仿真系统行为,事件注册、执行、管理流程贯穿整个系统仿真过程,确保复杂系统行为的准确模拟。
车辆定位 源码_车辆定位 源码是什么
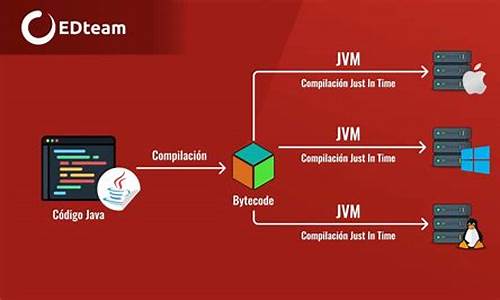
java在线客服源码_java客服电话

java读取网页源码_java获取网页源码
自动赚钱系统源码_全自动赚钱系统源码

郭婞淳奪金推手 減重名醫林聖章「涉讓護理師看診開藥」遭判刑
软件下载系统 源码_软件下载网源码
