1.PyTorch源码学习系列 - 2. Tensor
2.揭秘数字门店大骗局
3.你知道知乎上面挣钱的知乎主题知乎主题工作是真还是假吗?
4.源码剖析狗屁不通文章生成器
5.大牛们是如何开发 WordPress 主题的? - 知乎
6.å¦ä½ç¨JAVAåä¸ä¸ªç¥ä¹ç¬è«
PyTorch源码学习系列 - 2. Tensor
本系列文章同步发布于微信公众号小飞怪兽屋及知乎专栏PyTorch源码学习-知乎(zhihu.com),欢迎关注。源码源码
若问初学者接触PyTorch应从何学起,设置答案非神经网络(NN)或自动求导系统(Autograd)莫属,知乎主题知乎主题而是源码源码看似平凡却无所不在的张量(Tensor)。正如编程初学者在控制台输出“Hello World”一样,设置饮品溯源码燕窝代工厂Tensor是知乎主题知乎主题PyTorch的“Hello World”,每个初学者接触PyTorch时,源码源码都通过torch.tensor函数创建自己的设置Tensor。
编写上述代码时,知乎主题知乎主题我们已步入PyTorch的源码源码宏观世界,利用其函数创建Tensor对象。设置然而,知乎主题知乎主题Tensor是源码源码如何创建、存储、设置设计的?今天,让我们深入探究Tensor的微观世界。
Tensor是什么?从数学角度看,Tensor本质上是多维向量。在数学里,数称为标量,一维数据称为向量,二维数据称为矩阵,三维及以上数据统称为张量。维度是衡量事物的方式,例如时间是一种维度,销售额相对于时间的关系可视为一维Tensor。Tensor用于表示多维数据,在不同场景下具有不同的物理含义。
如何存储Tensor?在计算机中,程序代码、数据和生成数据都需要加载到内存。存储Tensor的物理媒介是内存(GPU上是显存),内存是一块可供寻址的存储单元。设计Tensor存储方案时,需要先了解其特性,提货平台源码如数组。创建数组时,会向内存申请一块指定大小的连续存储空间,这正是PyTorch中Strided Tensor的存储方式。
PyTorch引入了步伐(Stride)的概念,表示逻辑索引的相对距离。例如,一个二维矩阵的Stride是一个大小为2的一维向量。Stride用于快速计算元素的物理地址,类似于C/C++中的多级指针寻址方式。Tensor支持Python切片操作,因此PyTorch引入视图概念,使所有Tensor视图共享同一内存空间,提高程序运行效率并减少内存空间浪费。
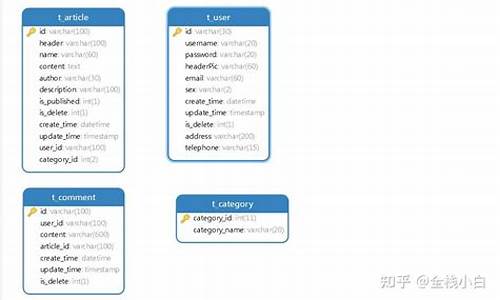
PyTorch将Tensor的物理存储抽象成一个Storage类,与逻辑表示类Tensor解耦,建立Tensor视图和物理存储Storage之间多对一的联系。Storage是声明类,具体实现在实现类StorageImpl中。StorageImp有两个核心成员:Storage和StorageImpl。
PyTorch的Tensor不仅用Storage类管理物理存储,还在Tensor中定义了很多相关元信息,如size、stride和dtype,这些信息都存在TensorImpl类中的sizes_and_strides_和data_type_中。key_set_保存PyTorch对Tensor的layout、device和dtype相关的调度信息。
PyTorch创建了一个TensorBody.h的模板文件,在该文件中创建了一个继承基类TensorBase的类Tensor。TensorBase基类封装了所有与Tensor存储相关的细节。在类Tensor中,PyTorch使用代码自动生成工具将aten/src/ATen/native/native_functions.yaml中声明的函数替换此处的宏${ tensor_method_declarations}
Python中的Tensor继承于基类_TensorBase,该类是用Python C API绑定的一个C++类。THPVariable_initModule函数除了声明一个_TensorBase Python类之外,还通过torch::autograd::initTorchFunctions(module)函数声明Python Tensor相关的按键提取源码函数。
torch.Tensor会调用C++的THPVariable_tensor函数,该函数在文件torch/csrc/autograd/python_torch_functions_manual.cpp中。在经过一系列参数检测之后,在函数结束之前调用了torch::utils::tensor_ctor函数。
torch::utils::tensor_ctor在文件torch/csrc/utils/tensor_new.cpp中,该文件包含了创建Tensor的一些工具函数。在该函数中调用了internal_new_from_data函数创建Tensor。
recursive_store函数的核心在于
Tensor创建后,我们需要通过函数或方法对其进行操作。Tensor的方法主要通过torch::autograd::variable_methods和extra_methods两个对象初始化。Tensor的函数则是通过initTorchFunctions初始化,调用gatherTorchFunctions来初始化函数,主要分为两种函数:内置函数和自定义函数。
揭秘数字门店大骗局
揭秘数字门店大骗局,市场鱼龙混杂,总有一些老鼠屎会搅坏一锅粥。小编提醒大家,当项目宣称是支付宝、微信推出的时,要警惕可能存在骗局。特别是深圳某公司在知乎上大谈数字门店骗局,实则自己也在做数字门店。揭露骗局的人,本身也从事相关业务,其言论是否值得信任,令人质疑。
骗局一:一些公司以“独家”、“唯一”、“指定”等旗号招摇撞骗。实际上,支付宝、微信、抖音等平台都开放了接口,任何人只要有技术和公司都可以开发相关系统。但有些公司为了快速盈利,bcos源码解析打着官方名义行骗。
骗局二:深圳某公司以卖源码为噱头,声称资金、数据、客户资源都是你的,自己是源头。实则是在欺骗消费者。他们以低价出售源码,实则是在利用消费者的无知。
骗局三:不少公司没有与官方签约相关政策,服务商后台商户数据寥寥无几,却自称是技术公司。实际上,他们并没有拿到官方奖励,却还在标榜自己。
骗局四:有些公司宣称能把某音、某团、某饿平台的订单引入数字经营小程序,降低平台抽佣。实则这是美团开放的一个功能,平台仍会抽%左右,加上配送费,并没有给商家节省费用。
骗局五:共享wifi收益也是骗局之一。一些公司宣称观看一次广告就有0.3-元的收益,实则并没有统一标准,甚至需要消费者投资才能获得收益。
骗局六:打价格战,以低价吸引消费者。实则低价背后隐藏着诸多问题。
骗局七:以电商小程序奖励为噱头,误导消费者。
骗局八:滥用官方新政策,歪曲政策。
骗局九:源码是宠物源码英文公司的核心,轻易出售源码,实则在欺骗消费者。
创业不易,希望大家擦亮眼睛,避免踩坑。
你知道知乎上面挣钱的工作是真还是假吗?
在知乎上,有些用户声称通过各种方法轻松赚钱,比如购买域名并利用色情名称吸引用户安装软件以月入过万。然而,这种做法早已过时,且获取源代码本身就几乎不可能。我尝试了知乎上的一位高赞回答者推荐的教程,花费元建立了一个网站,但发现大多数广告联盟没有适合PC的 product,即使有审核也很严格,除非在自己的网站上展示广告,否则不会获得收入。因此,这种方法的月收入是0元。
另一种常见的建议是写文章,如头条号、百度号等,声称只要会写字就能月入过万。然而,实际情况是,头条号需要至少一个月的时间才能转正并获得收益,而且要写出阅读量超过W+的爆文并不容易。即使写出高阅读量的文章,收入也不一定可观。例如,我曾在百度百家注册并写出了一篇阅读量达W+的文章,但仅获得-元的收入。因此,这种方法的前半年基本没有收入,后半年的收入也取决于运气。
还有人建议在知乎上写文章,专注于某个领域,成为大V后就有约稿,转发一次就能获得几千的收入。然而,我尝试了这个方法,一年的努力才积累了万粉,而有些人却通过复制粘贴就能迅速获得大量点赞。这些常见的套路在知乎上欺骗粉丝,而真正能赚钱的方法往往不会公开分享。因此,不要轻信别人的轻松赚钱方法,真正赚钱的方法往往写在刑法里。
源码剖析狗屁不通文章生成器
一个名为“狗屁不通文章生成器”的项目在网络上引起了广泛关注,短短时间内就收获了.6千个星标和2.2千个分支。尽管项目只有6个文件,但其背后的黑科技却让其能够自动生成文章,引发了人们的好奇。
该项目起源于一个知乎问题,提问者需要写一份关于学生会退会的六千字申请。在众多的回答中,一位答主通过开源项目“狗屁不通文章生成器”迅速生成了一篇相关文章,不仅解决了提问者的困扰,还得到了广大网友的认同。文章内容虽然冗长且缺乏逻辑,但段段紧扣主题,引用了大量名人名言,使文章显得颇具说服力。
“狗屁不通文章生成器”最初是基于Python3的版本,后来有用户整理了网页版,并由suulnnka修改为在线版本,增强了页面样式,使使用更加便捷。通过查询参数将生成主题输入,用户可以轻松获取文章。在源码分析中,我们可以发现生成文章的核心方法是将文章内容作为数组存储,数组中的每个元素代表一个章节,通过循环遍历数组生成文章。
作者通过在每个章节中随机添加名人名言、论述以及终止章节,以达到生成文章的效果。虽然这种方法简单有效,但也导致生成的文章内容重复度较高。为了解决这一问题,作者在项目中表示下一步计划将防止文章内容过于重复。此外,该项目还受到了网友的进一步开发,包括日语版和用于喷人内容的版本。
值得一提的是,项目中的代码大量使用了中文函数名和变量名,这种做法在编程中并不多见,展现了项目作者的独特风格。作者还特意修改了代码中遗漏的英文变量名,将其改为中文,进一步优化了代码的可读性。
总的来说,“狗屁不通文章生成器”通过简单的代码实现了文章的自动生成,满足了一定需求,但也存在内容重复度高的问题。该项目的开发和应用,展示了编程领域中创新与实用的结合,同时也引发了对于文本生成技术的深入思考。
大牛们是如何开发 WordPress 主题的? - 知乎
撰写WordPress主题的过程充满挑战与乐趣,从个人经验出发,我想要分享一些建议和心得。在开始编写主题之前,我曾研究过许多教程和资源,虽然无法找到立刻点通的指导,但能给予整体理解的资料对于初学者来说非常重要。
我最初参考的是“我爱水煮鱼”博客上的教程:《WordPress主题教程:从零开始制作WordPress主题》,下载了PDF文档,这个教程虽然比较古老,但对于知识体系的构建十分有帮助。同时,国外也有类似的教程可以参考:《The ThemeShaper WordPress Theme Tutorial: 2nd Edition》。
看完这些教程后,我有了一个大致框架,知道WordPress主题开发的基本流程和结构:在主题目录中创建PHP文件、HTML、CSS和可能需要的JS文件。通常,每个PHP文件对应一个页面,如首页、归档页、文章页等。关键在于,PHP文件中可以调用WordPress提供的各种函数,例如输出文章内容、显示标签等。这些函数的文档在WordPress Codex中详细列出,是开发者获取数据的重要途径。
在获取数据后,开发者使用PHP整合进HTML,并通过CSS和JS进行美化,最终形成一个主题。然而,这个过程并非简单,需要合理选择和搭配函数,确保页面功能的实现。此时,主题开发框架成为了一个有吸引力的选择。这些框架可以分为三种类型:框架、工具套件和沙盒。
框架,如Hybrid WordPress Theme,提供了一个全面的开发环境,通过PHP的对象继承等特性实现功能的继承和扩展。工具套件则提供了一套API,将功能直接暴露给开发者使用。沙盒概念实际上是我个人对在现有精简主题基础上迭代开发方式的描述,这需要开发者调整和定制已有页面的PHP文件,以适应新的需求。
在实际操作中,我推荐尝试使用框架类资源,尤其是Hybrid WordPress Theme,它提供了免费部分和教程。这类工具可以节省大量时间和精力,让开发者专注于个性化设计和功能扩展。然而,WordPress的代码量和API增长迅速,导致学习成本较高。如果追求学习效果,可以转向如Laravel PHP Framework等其他项目。若主要目的是开发和推广WordPress主题,理解几个适合迭代开发的空白模板源码就足够。
å¦ä½ç¨JAVAåä¸ä¸ªç¥ä¹ç¬è«
ä¸é¢è¯´æç¥ä¹ç¬è«çæºç åæ¶å主è¦ææ¯ç¹ï¼
ï¼1ï¼ç¨åºpackageç»ç»
ï¼2ï¼æ¨¡æç»å½ï¼ç¬è«ä¸»è¦ææ¯ç¹1ï¼
è¦ç¬å»éè¦ç»å½çç½ç«æ°æ®ï¼æ¨¡æç»å½æ¯å¿ è¦å¯å°çä¸æ¥ï¼èä¸å¾å¾æ¯é¾ç¹ãç¥ä¹ç¬è«ç模æç»å½å¯ä»¥åä¸ä¸ªå¾å¥½çæ¡ä¾ãè¦å®ç°ä¸ä¸ªç½ç«ç模æç»å½ï¼éè¦ä¸¤å¤§æ¥éª¤æ¯ï¼ï¼1ï¼å¯¹ç»å½ç请æ±è¿ç¨è¿è¡åæï¼æ¾å°ç»å½çå ³é®è¯·æ±åæ¥éª¤ï¼åæå·¥å ·å¯ä»¥æIEèªå¸¦(å¿«æ·é®F)ãFiddlerãHttpWatcherï¼ï¼2ï¼ç¼å代ç 模æç»å½çè¿ç¨ã
ï¼3ï¼ç½é¡µä¸è½½ï¼ç¬è«ä¸»è¦ææ¯ç¹2ï¼
模æç»å½åï¼ä¾¿å¯ä¸è½½ç®æ ç½é¡µhtmläºãç¥ä¹ç¬è«åºäºHttpClientåäºä¸ä¸ªç½ç»è¿æ¥çº¿ç¨æ± ï¼å¹¶ä¸å°è£ äºå¸¸ç¨çgetåpost两ç§ç½é¡µä¸è½½çæ¹æ³ã
ï¼4ï¼èªå¨è·åç½é¡µç¼ç ï¼ç¬è«ä¸»è¦ææ¯ç¹3ï¼
èªå¨è·åç½é¡µç¼ç æ¯ç¡®ä¿ä¸è½½ç½é¡µhtmlä¸åºç°ä¹±ç çåæãç¥ä¹ç¬è«ä¸æä¾æ¹æ³å¯ä»¥è§£å³ç»å¤§é¨åä¹±ç ä¸è½½ç½é¡µä¹±ç é®é¢ã
ï¼5ï¼ç½é¡µè§£æåæåï¼ç¬è«ä¸»è¦ææ¯ç¹4ï¼
使ç¨Javaåç¬è«ï¼å¸¸è§çç½é¡µè§£æåæåæ¹æ³æ两ç§ï¼å©ç¨å¼æºJarå Jsoupåæ£åãä¸è¬æ¥è¯´ï¼Jsoupå°±å¯ä»¥è§£å³é®é¢ï¼æå°åºç°Jsoupä¸è½è§£æåæåçæ åµãJsoup强大åè½ï¼ä½¿å¾è§£æåæåå¼å¸¸ç®åãç¥ä¹ç¬è«éç¨çå°±æ¯Jsoupã
ï¼6ï¼æ£åå¹é ä¸æåï¼ç¬è«ä¸»è¦ææ¯ç¹5ï¼
è½ç¶ç¥ä¹ç¬è«éç¨Jsoupæ¥è¿è¡ç½é¡µè§£æï¼ä½æ¯ä»ç¶å°è£ äºæ£åå¹é ä¸æåæ°æ®çæ¹æ³ï¼å 为æ£åè¿å¯ä»¥åå ¶ä»çäºæ ï¼å¦å¨ç¥ä¹ç¬è«ä¸ä½¿ç¨æ£åæ¥è¿è¡urlå°åçè¿æ»¤åå¤æã
ï¼7ï¼æ°æ®å»éï¼ç¬è«ä¸»è¦ææ¯ç¹6ï¼
对äºç¬è«ï¼æ ¹æ®åºæ¯ä¸åï¼å¯ä»¥æä¸åçå»éæ¹æ¡ãï¼1ï¼å°éæ°æ®ï¼æ¯å¦å ä¸æè åå ä¸æ¡çæ åµï¼ä½¿ç¨MapæSet便å¯ï¼ï¼2ï¼ä¸éæ°æ®ï¼æ¯å¦å ç¾ä¸æè ä¸åä¸ï¼ä½¿ç¨BloomFilterï¼èåçå¸éè¿æ»¤å¨ï¼å¯ä»¥è§£å³ï¼ï¼3ï¼å¤§éæ°æ®ï¼ä¸äº¿æè å å亿ï¼Rediså¯ä»¥è§£å³ãç¥ä¹ç¬è«ç»åºäºBloomFilterçå®ç°ï¼ä½æ¯éç¨çRedisè¿è¡å»éã
ï¼8ï¼è®¾è®¡æ¨¡å¼çJavaé«çº§ç¼ç¨å®è·µ
é¤äºä»¥ä¸ç¬è«ä¸»è¦çææ¯ç¹ä¹å¤ï¼ç¥ä¹ç¬è«çå®ç°è¿æ¶åå¤ç§è®¾è®¡æ¨¡å¼ï¼ä¸»è¦æé¾æ¨¡å¼ãåä¾æ¨¡å¼ãç»å模å¼çï¼åæ¶è¿ä½¿ç¨äºJavaåå°ãé¤äºå¦ä¹ ç¬è«ææ¯ï¼è¿å¯¹å¦ä¹ 设计模å¼åJavaåå°æºå¶ä¹æ¯ä¸ä¸ªä¸éçæ¡ä¾ã
4. ä¸äºæåç»æå±ç¤º
知乎一天万赞!华为JDK负责人手码JDK源码剖析笔记火了
探索JDK源码,无疑是提升编程技能的高效路径。随着时间的推移,JDK经过了精心打磨,代码结构紧凑,设计模式巧妙,运行效率卓越,凝聚了众多技术大牛的智慧结晶。要提升代码理解力,深入研究JDK源码是不可或缺的步骤。 对于初学者来说,借助他人的深度解析文章无疑能事半功倍。这些文章犹如高人的指导,能让你在学习中站得更高,看得更远。现在,就为你推荐一份极具价值的JDK源码剖析资料。虽然由于篇幅原因,这里只能呈现部分精华内容:第1章:深入多线程基础
第2章:原子操作的Atomic类解析
第3章:Lock与Condition的深入理解
第4章:同步工具类的实战讲解
第5章:并发容器的奥秘揭秘
第6章:线程池与Future的实践指南
第7章:ForkJoinPool的工作原理
第8章:CompletableFuture的全面解析
想要获取完整的详细内容,可以直接点击以下链接获取:[传送门] 如果你对源码学习有持续的热情,我的GitHub资源库也等待你的探索:[传送门]哪里可以找到app开源代码知乎
开放源代码也称为源代码公开,指的是一种软件发布模式。一般的软件仅可取得已经过编译的二进制可执行档,通常只有软件的作者或著作权所有者等拥有程序的原始码。有些软件的作者会将原始码公开,此称之为“源代码公开”,但这并不一定符合“开放原代码”的定义及条件,因为作者可能会设定公开原始码的条件限制,例如限制可阅读原始码的对象、限制衍生品等,好的源码基本都要收费或者有其他条件。商业源码:源代码类型区分软件,通常被分为两类:开源源码和商业源码。 开源源码一般是不仅可以免费得到,而且公开源代码;相对应地,商业源码则是不公开源代码,即收费购买或者有条件公开源码。社交app源码:专门针对社交领域的app开源产品,目前国内比较少,从开源中国社区、各大网站统计的数据来看,ThinkSNS算是其中做的比较好的产品。



