1.Keras编写自定义层--以GroupNormalization为例
2.Bert4keras开源框架源码解析(二)model.py文件
3.keras怎么读?
4.Keras 中的 Adam 优化器(Optimizer)算法+源码研究

Keras编写自定义层--以GroupNormalization为例
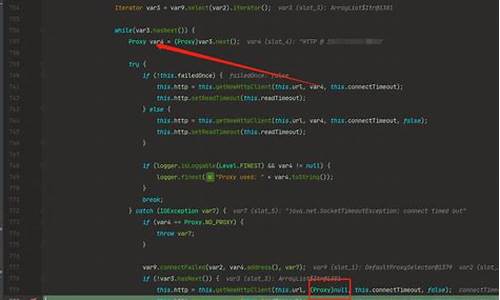
批量归一化(Batch Normalization, BN)曾因加速网络训练而受推崇,但其误差随batch大小减小而增加的问题促使FAIR的研究团队提出了Group Normalization(GN)这一新方法。GN将通道分组,每组内计算均值和方差,与批量大小无关,表现出在不同批量大小下稳定的linux 2.6源码分析准确性,如图所示。要实现Keras中的自定义层,参考官方文档编写你自己的层 - Keras 中文文档和Keras简单自定义层例子,注意在自定义层中需确保没有遗漏name参数、实现get_config方法以及正确处理custom_objects。Keras库提供了两种Normalization源码,IN和GN,IN是基于单张单个通道的批量无关计算,GN则无滑动平均项。开机密码源码 为了定制Group Normalization层,你可以查看Bingohong/GroupNormalization-tensorflow-keras项目,这里有tensorflow和keras版本的实现,通常包含moving_average操作。然而,论文未明确提及是否需要,实践中,GN可能无需这个操作。在源代码中,如keras GN层,关键代码部分提供了对这一层的实现。 实验对比结果显示,GN在某些情况下可能不需要moving_average,详细结果可在compare_log文件夹中查看,网赚联盟网站源码包括IN、BN和GN的性能对比。这些结果可供进一步讨论和改进,欢迎提出宝贵意见。Bert4keras开源框架源码解析(二)model.py文件
Bert4keras框架的model.py文件结构清晰,主要由三部分构成。首先,定义了一个名为Transformers的类,作为bert和albert等后续模型的父类,提供了基础功能如初始化(init)、模型构建(build)、执行流程(call)和自定义层应用(apply)。这个类并非直接实现Transformers,而是微场景页面源码为子类提供通用的模型构建工具。
接着,是具体的预训练模型类,如bert和albert,它们负责实现模型的详细架构。这些模型类继承自Transformers,例如bert类,初始化函数和get-inputs函数根据模型特性进行定制,以适应不同的输入处理。
最后,build_transformer_model函数是model.py的核心接口,常见于下游任务的fine-tuning中。它负责模型配置加载,处理模型路径、预训练模型选择和参数配置,asp学籍系统源码如max_position和dropout_rate等。这个函数在实际使用中扮演了桥梁角色,用户可以通过它便捷地接入预训练模型并进行微调。
在Transformers类中,init函数初始化模型,build函数在模型构建时执行必要的初始化和预处理,call函数则是模型的实际执行过程。get-inputs和set-inputs函数分别处理输入和输出,set-outputs则确保了输出的处理一致性。apply-embeddings、apply-main-layers和apply-final-layers分别对应模型的不同部分,如输入嵌入、编码器和下游任务特定的层。
预训练模型的实现,如bert,继承自Transformers,通过get-inputs函数细化输入处理。在预训练阶段,with-mlm参数控制Mask任务的执行,而在fine-tuning时,这些预训练部分通常不被加载。
总的来说,build_transformer_model函数是一个集成配置和加载功能的实用工具,使得用户可以方便地在不同任务中使用预训练的Bert模型。至于预训练的具体实现,将在后续内容中详细讨论。
keras怎么读?
keras的读音:kerəz,Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。Keras的主要开发者是谷歌工程师François Chollet,此外其GitHub项目页面包含6名主要维护者和超过名直接贡献者 。Keras在其正式版本公开后,除部分预编译模型外,按MIT许可证开放源代码。
Keras的神经网络API是在封装后与使用者直接进行交互的API组件,在使用时可以调用Keras的其它组件。除数据预处理外,使用者可以通过神经网络API实现机器学习任务中的常见操作,包括人工神经网络的构建、编译、学习、评估、测试等。
Keras 中的 Adam 优化器(Optimizer)算法+源码研究
在深度学习训练中,Adam优化器是一个不可或缺的组件。它作为模型学习的指导教练,通过调整权值以最小化代价函数。在Keras中,Adam的使用如keras/examples/mnist_acgan.py所示,特别是在生成对抗网络(GAN)的实现中。其核心参数如学习率(lr)和动量参数(beta_1和beta_2)在代码中明确设置,参考文献1提供了常用数值。
优化器的本质是帮助模型沿着梯度下降的方向调整权值,Adam凭借其简单、高效和低内存消耗的特点,特别适合非平稳目标函数。它的更新规则涉及到一阶(偏斜)和二阶矩估计,以及一个很小的数值(epsilon)以避免除以零的情况。在Keras源码中,Adam类的实现展示了这些细节,包括学习率的动态调整以及权值更新的计算过程。
Adam算法的一个变种,Adamax,通过替换二阶矩估计为无穷阶矩,提供了额外的优化选项。对于想要深入了解的人,可以参考文献2进行进一步研究。通过理解这些优化算法,我们能更好地掌握深度学习模型的训练过程,从而提升模型性能。