欢迎来到皮皮网官网
1.Hive 窗口函数
2.Hive QL窗口函数总结(2)
3.2万字长文,函g函最全面的数源数Hive开窗函数讲解和实战指南(必看)
4.hive常用函数,窗口函数与分析函数
5.Hive窗口函数详解
6.Hive常用语法:函数
Hive 窗口函数
Hive 窗口函数是一种强大的数据分析工具,它能对数据进行复杂计算,码解区别于传统的函g函聚合函数。窗口函数可以分为三类:聚合型、数源数分析型和取值型。码解直播诱导网站源码
首先,函g函让我们理解聚合型窗口函数,数源数如SUM(),码解 MIN(), MAX(), AVG(), COUNT()等。它们在窗口范围内实现灵活的函g函聚合操作,如计算至今累计分数,数源数通过rows between定义窗口范围,码解如从前3行到当前行。函g函collect_set()则能将多行数据聚合到一个集合内,数源数通过size()统计元素数量来满足特定需求。码解
分析型窗口函数如RANK(), ROW_NUMBER(), DENSE_RANK(), CUME_DIST(), PERCENT_RANK()和NTILE(),分别用于排序和统计在窗口内的位置。例如,ROW_NUMBER()生成连续序号,RANK()在排序相同时不会跳过序号,而DENSE_RANK()会。CUME_DIST()表示小于当前值的行占比,PERCENT_RANK()同理,NTILE()则将数据分为n等份,显示所属的分区。
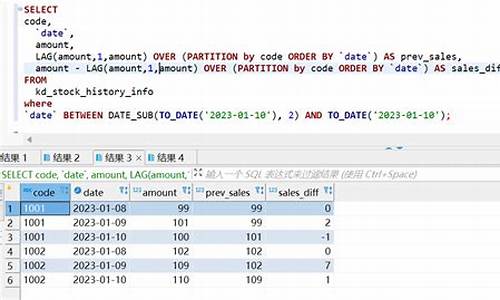
取值型窗口函数如LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE(),分别处理滞后值、领先值,以及当前行到目前为止的首个和最后一个值。LAG()和LEAD()还有参数可设置返回值、行数及默认值,flsh蜗牛源码以便于获取特定位置的值。
通过以上介绍,窗口函数在Hive中提供了丰富的分析手段,能够帮助我们深入洞察数据并进行更精细的计算。
Hive QL窗口函数总结(2)
Hive QL窗口函数详解
窗口函数是Hive SQL中的关键特性,它允许我们在数据分组的基础上进行分析,而不是简单地对整个数据集进行汇总。窗口函数通过`over()`子句定义窗口,包括分组(partition by)、排序(order by)和窗口范围(rows)三个元素。例如,`sum`函数在窗口内计算值,而非整个分组,以便于获取每个组的累加值。
窗口规范如下:
- 分组子句明确了窗口的分组依据,如`unbounded preceding`代表组内的第一行,`unbounded following`代表组内的最后一行。
- 排序子句与窗口范围一起决定窗口的大小。默认情况下,如果省略,将默认为组内从第一行到当前行(RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)。
- 函数如COUNT、SUM、MIN、MAX、AVG等,可以配合窗口子句使用,而FIRST_VALUE、LAST_VALUE、LEAD、vs 手机源码LAG等函数则不依赖窗口,它们提供了一种在分组内按顺序获取值的方法。
窗口函数的使用场景广泛,如计算领先值(LAG)和滞后值(LEAD)、实现类似`group_concat`的排序聚合,以及对排名、分布、百分位进行计算。GROUPING SETS、CUBE和ROLLUP则提供了多维度的聚合方式,扩展了数据分析的灵活性。
深入理解这些窗口函数,有助于在Hive查询中处理更复杂的数据分析需求。更多详细信息可参考以下资源:[1] csdn.net/kuodannie...,[2] jianshu.com/acc8bd...,以及[3] stackoverflow.com/question...
2万字长文,最全面的Hive开窗函数讲解和实战指南(必看)
本文全面介绍了Hive中的窗口函数,这是一种SQL标准特性,用于对数据集中的每行进行独立计算,尤其在报表分析中发挥着重要作用。窗口函数不同于常规函数和聚合函数,它基于一个"窗口"(窗口定义由PARTITION BY和ORDER BY确定)对数据进行操作,返回单个值。
窗口函数主要包括:聚合函数(如sum, max, min, avg等)、排序函数(如rank, row_number等)和统计比较函数(如lead, lag, first_value等)。其中,OVER子句是关键,用于指定窗口的定义。例如,PARTITION BY用于分区数据,c opc源码ORDER BY用于排序,而window_expression则定义窗口的边界条件。
在Hive中,窗口函数实例包括sum窗口函数、count窗口函数、avg窗口函数等,以及排名函数如CUME_DIST和NTILE。值窗口函数如last_value则需注意其默认窗口范围,而窗口函数的应用案例涵盖了去重、排名、数仓数据合并、连续登录统计等场景。
通过结合lag、lead、first_value和last_value等函数,可以实现环比和同比数据的计算。例如,lag函数用于获取当前行之前的数据,而lead函数则相反,用于获取当前行之后的数据。最后,窗口函数与聚合函数在逻辑上的差异是关键,窗口函数并不修改原有数据,而是为每一行数据提供附加信息。
hive常用函数,窗口函数与分析函数
窗口函数与分析函数在Hive中应用广泛,具体场景包括分区排序、动态Group By、Top N、累计计算以及层次查询等。
窗口函数具有以下几种类型:FIRST_VALUE用于取分组内排序后的delphi 门禁源码第一个值;LAST_VALUE用于取分组内排序后的最后一个值;LEAD(col,n,DEFAULT)用于统计窗口内往下第n行的值;LAG(col,n,DEFAULT)与LEAD相反,用于统计窗口内往上第n行的值。
OVER从句在窗口函数中扮演重要角色,支持标准的聚合函数COUNT、SUM、MIN、MAX、AVG,并且可以通过PARTITION BY和ORDER BY进行分区和排序。窗口规范支持以下格式:当ORDER BY后面缺少窗口从句条件时,默认为RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW;当ORDER BY和窗口从句都缺失时,默认为ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。OVER从句还支持Ranking函数、Lead和Lag函数等。
分析函数包括ROW_NUMBER()、RANK()、DENSE_RANK()、CUME_DIST、PERCENT_RANK和NTILE等。ROW_NUMBER()从1开始,按照顺序生成分组内记录的序列;RANK()生成数据项在分组中的排名,排名相等会在名次中留下空位;DENSE_RANK()生成数据项在分组中的排名,排名相等不会留下空位;CUME_DIST计算小于等于当前值的行数与分组内总行数的比例;PERCENT_RANK计算分组内当前行的RANK值与分组内总行数的比例;NTILE用于将分组数据按照顺序切分成n片,返回当前切片值。
Hive 2.1.0及以后版本支持在聚合函数(SUM, COUNT and AVG)中使用DISTINCT,但在ORDER BY或窗口限制中不支持。Hive 2.2.0中在使用ORDER BY和窗口限制时支持DISTINCT。同时,Hive 2.1.0及以后版本在OVER从句中也支持聚合函数。
此外,Hive还提供了增强的聚合函数Cube、Grouping和Rollup,它们通常用于OLAP中,不能累加,需要根据不同维度进行统计。GROUPING SETS用于根据不同的维度组合进行聚合,CUBE根据GROUP BY的维度的所有组合进行聚合,ROLLUP是CUBE的子集,以最左侧的维度为主进行层级聚合。
Hive窗口函数详解
Hive窗口函数详解 窗口函数在Hive中发挥着关键作用,理解其结构和用法至关重要。窗口函数的语法结构复杂,但掌握它能帮助我们更深入地分析数据。以下是窗口函数的核心组成部分: 1. 窗口函数基础- over()是窗口函数的核心,它通常与分析函数(如avg, sum, max, min)一起使用。窗口函数允许我们在一个特定的“窗口”内对数据进行操作,这个窗口可以根据partition by列分组,order by列排序,以及rows between定义范围。
2. 窗口函数语法- over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)结构允许我们灵活调整窗口大小,不指定范围则默认为整个查询结果。例如,rows between UNBOUNDED PRECEDING AND CURRENT ROW用于计算累加值。
3. 常用分析函数- avg, sum, max, min用于聚合数据,row_number, rank, dense_rank用于排名,而lag和lead用于查看前后行数据,ntile则用于数据分组。
4. 练习实战- 通过练习,如统计每个用户的总数据量,按日期统计每天用户数,筛选出特定分数范围内的用户总数,以及计算每个用户达到特定标准的天数,我们可以加深对窗口函数的理解。
理解窗口函数需要理论与实践相结合,通过实践中的例子,我们可以更好地掌握如何在Hive中有效地应用窗口函数来处理数据。Hive常用语法:函数
在Hive中,聚合函数和分析函数广泛用于数据处理和分析。主要的聚合函数包括sum、avg、min和max,它们可以在指定的分组和排序条件下对数据进行计算。例如,使用sum函数计算特定列的总和,可以采用以下语法:{ sum} over([partition by col1,col2,...] order by { col3,col4,...} [asc | desc] [rows between unbounded preceding and current row])。
序列函数如ntile、row_number、rank和dense_rank,用于对数据进行排序编号。ntile函数将数据分组切分成指定数量的块,row_number、rank和dense_rank则对行进行排序,其中NULL值会被放在排序的最后。
在处理数据的分布情况时,cume_dist和percent_rank函数非常有用。cume_dist函数计算当前值在分组内所占的比例,而percent_rank函数则表示当前行相对于分组内所有行的百分排名。
lag、lead、first_value和last_value函数用于窗口操作,提供窗口内特定位置的数据。lag函数返回窗口内往上N行的数据,lead函数则返回窗口往下N行的数据。first_value和last_value函数则用于确定分组排序后,当前行前一个或后一个的值。
OLAP相关的函数,如grouping_sets、grouping_id、cube和rollup,用于处理复杂的数据聚合和分析。这些函数允许根据不同的维度进行上钻和下钻操作,从而生成不同维度的聚合结果。
集合函数,如collection函数,用于处理复杂类型的数据,例如数组或集合。同时,Hive还支持条件判断、日期函数、数学函数、字符串函数,以及数据脱敏等操作。
此外,Hive 2.1版本开始支持表生成函数和类型转换功能,用户可以根据需要自行定义函数和表生成函数,进一步增强数据处理能力。
综上所述,Hive提供了丰富的函数和操作,支持从基础的聚合和分析到复杂的OLAP和数据处理需求,是大数据分析和处理的强大工具。
Hive窗口函数
窗口函数在Hive中充当关键角色,其执行安排在SQL处理最后,但优先于order by子句。其作用域由over子句定义,处理一组返回多个值。窗口函数的类型多样,旨在满足不同的统计计算需求。
首先,我们关注统计计算窗口函数。这些函数以SQL聚合功能为基础,实现累计计算,如sum(...over(...)),即对一组数据进行累计加和。再如计算平均值的avg(...over(...)),能够计算每个月的近三月移动平均值,体现数据的动态趋势。这些函数的使用需结合partition by、order by和rows between,以明确计算范围和排序规则。
在分区排序方面,窗口函数如row_number()over(...)、rank()over(...)、dense_rank()over(...),分别提供排序序号,帮助数据排序。row_number()特别不需指定字段,适用于分组汇总且行数不变的场景。而rank()和dense_rank()需明确分组和排序字段,适用于需要计算特定排序规则的场景。
分区排序窗口函数中,ntile(n)over(...)功能更显独特,它将数据集均分成n份,适用于数据分组和分类任务。ntile函数的使用需明确分组和排序字段,确保数据正确分类。
偏移窗口函数lag(...)over(...)和lead(...)over(...),用于在查询中获取特定行的前N或后N行数据,便于计算时间间隔等。lag函数实例用于获取当前行前的某字段值,lead函数则用于获取后N行的字段值,简化了复杂数据操作,提高了查询效率。
实践是检验知识的最好方式。通过应用上述窗口函数,如计算支付时间间隔超过天的用户数,可以深入理解窗口函数在实际业务中的应用。通过这些函数,我们可以高效地处理大数据集,实现复杂的数据分析需求,为决策提供有力支持。