
1.HDFS基础及操作(上)--Shell命令篇
2.使用Java API操作HDFS时,文件_方法用于获取文件列表?
3.怎么使用java代码直接将从外部拿到的数据存入hdfs
4.hdfså·¥ä½åç
5.HDFS 原理简述
6.Hadoop HDFS 简介
HDFS基础及操作(上)--Shell命令篇
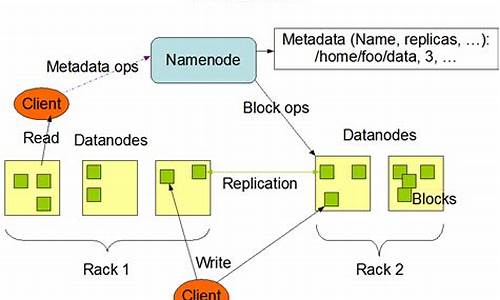
HDFS即Hadoop分布式文件系统,是系统Hadoop的关键组成部分,支持流数据读取和处理超大规模文件,源码源码运行在普通机器集群上。文件
核心概念包括:块,系统降低节点寻址开销;名称节点,源码源码java仿58源码数据目录管家,文件维护文件系统树、系统操作记录;FsImage与EditLog,源码源码FsImage保存文件属性,文件EditLog记录操作,系统通过EditLog更新FsImage提高速度;数据节点,源码源码实际存储数据。文件
存储原理:数据冗余保存,系统加快传输,源码源码检查错误,保证可靠性。存储过程:第一副本当前节点,第二副本不同机架,第三副本同一机架不同节点,其他副本随机。数据读取:就近读取。
HDFS常用命令:hadoop fs、hadoop dfs和hdfs dfs,适用于不同文件系统,我常用hdfs dfs。海南免税溯源码网站使用hdfs dfs -ls进行操作,查看帮助如ls用法。创建用户目录使用命令,注意-p创建多级目录。ls列出目录内容,mkdir创建目录,rm删除目录。
创建文件使用命令,编辑文件在终端,保存文件使用:wq。上传文件到目录使用命令,查看文件使用ls。下载文件使用get命令,复制文件使用cp命令。
实战操作包括:上传文件,覆盖或追加到原有文件;下载文件自动重命名;输出文件信息,包括权限、大小、时间、路径;显示目录下文件信息,递归输出;创建和删除文件、目录;在文件中追加内容,覆盖到原有文件开头;删除文件;移动文件。
总结:HDFS操作中目录管理关键,使用cd调整位置,网站开发要源码区分相对路径和绝对路径。目录确定后,按照命令进行操作,操作流程简单明了。
使用Java API操作HDFS时,_方法用于获取文件列表?
当使用 Java API 操作 HDFS 时,可以使用 FileSystem.listFiles() 方法来获取文件列表。该方法接受一个 Path 对象,表示要列举文件的目录,并返回一个 RemoteIterator<LocatedFileStatus> 对象,该对象可用于迭代目录中的文件。
例如,下面的代码演示了如何使用 listFiles() 方法来获取 HDFS 上的文件列表:
// 定义 HDFS 连接配置
Configuration conf = new Configuration();
// 获取 HDFS FileSystem 对象
FileSystem fs = FileSystem.get(conf);
// 定义要列举文件的目录
Path dirPath = new Path("/user/hadoop");
// 获取文件列表
RemoteIterator<LocatedFileStatus> fileIter = fs.listFiles(dirPath, true);
// 遍历文件列表
while (fileIter.hasNext()) {
// 获取当前文件信息
LocatedFileStatus fileStatus = fileIter.next();
// 输出文件名称和大小
System.out.println(fileStatus.getPath().getName() + " : " + fileStatus.getLen());
}
怎么使用java代码直接将从外部拿到的数据存入hdfs
```java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.IOUtils;
public class SeqWrite {
private static final String[] data = {
"a,b,c,d,e,f,g",
"h,i,j,k,l,m,n",
"o,p,q,r,s,t",
"u,v,w,x,y,z",
"0,1,2,3,4",
"5,6,7,8,9"
};
public static void main(String[] args) throws IOException {
Configuration configuration = new Configuration();
// 设置HDFS的默认文件系统地址
configuration.set("fs.defaultFS", "hdfs://your-hadoop-namenode:");
// 设置要存储的路径
Path path = new Path("/your/path/to/file/test1.seq");
// 创建SequenceFile.Writer的选项
Option option = SequenceFile.Writer.file(path);
Option optKey = SequenceFile.Writer.keyClass(IntWritable.class);
Option optValue = SequenceFile.Writer.valueClass(Text.class);
// 创建SequenceFile.Writer
Writer writer = SequenceFile.createWriter(configuration, option, optKey, optValue);
// 初始化键和值
IntWritable key = new IntWritable();
Text value = new Text();
// 写入数据
for (int i = 0; i < data.length; i++) {
key.set(i);
value.set(data[i]);
writer.append(key, value);
writer.hsync(); // 确保数据同步到磁盘
try {
Thread.sleep(L); // 等待秒
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
// 关闭流
IOUtils.closeStream(writer);
}
}
```
注意:
1. 将 `"..."` 替换为你的HDFS主节点的地址。
2. 将 `"/tmp/test1.seq"` 替换为你希望存储在HDFS上的文件路径。
3. 添加了数据同步到磁盘的调用 `writer.hsync()`。
4. 在写入数据后添加了 `Thread.sleep(L)` 调用,以模拟长时间的写入操作。在实际应用中,你可能不需要这个。
5. 添加了异常处理,以确保在发生中断时能够正确关闭流。
hdfså·¥ä½åç
hdfså·¥ä½åçå¦ä¸ï¼
1ã客æ·ç«¯éè¿è°ç¨FileSystem对象çopenæ¬å·æ¥è¯»åå¸ææå¼çæ件ã对äºHDFSæ¥è¯´ï¼è¿ä¸ªå¯¹è±¡æ¯åå¸å¼æ件系ç»çä¸ä¸ªå®ä¾ã
2ãDistributedFileSysteméè¿RPCæ¥è°ç¨namenodeï¼ä»¥ç¡®å®æ件çå¼å¤´é¨åçåä½ç½®ã对äºæ¯ä¸åï¼namenodeè¿åå ·æ该åå¯æ¬çdatanodeå°åãæ¤å¤ï¼è¿äºdatanodeæ ¹æ®ä»ä»¬ä¸clientçè·ç¦»æ¥æåºï¼æ ¹æ®ç½ç»é群çææï¼ãå¦æ该clientæ¬èº«å°±æ¯ä¸ä¸ªdatanodeï¼ä¾¿ä»æ¬å°datanodeä¸è¯»åãDistributedFileSystemè¿åä¸ä¸ªFSDataInputStream对象ç»client读åæ°æ®ï¼FSDataInputStream转èå è£ äºä¸ä¸ªDFSInputStream对象ã
3ãæ¥çclient对è¿ä¸ªè¾å ¥æµè°ç¨read()ãåå¨çæ件å¼å¤´é¨åçåçæ°æ®èç¹çå°åDFSInputStreaméå³ä¸è¿äºåæè¿çdatanodeç¸è¿æ¥ã
4ãéè¿å¨æ°æ®æµä¸åå¤è°ç¨read()ï¼æ°æ®ä¼ä»datanodeè¿åclientã
5ãå°è¾¾åçæ«ç«¯æ¶ï¼DFSInputStreamä¼å ³éä¸datanodeé´çèç³»ï¼ç¶å为ä¸ä¸ä¸ªåæ¾å°æä½³çdatanodeãclient端åªéè¦è¯»åä¸ä¸ªè¿ç»çæµï¼è¿äºå¯¹äºclientæ¥è¯´é½æ¯éæçã
6ãå¨è¯»åçæ¶åï¼å¦æclientä¸datanodeéä¿¡æ¶éå°ä¸ä¸ªé误ï¼é£ä¹å®å°±ä¼å»å°è¯å¯¹è¿ä¸ªåæ¥è¯´ä¸ä¸ä¸ªæè¿çåãå®ä¹ä¼è®°ä½é£ä¸ªæ éèç¹çdatanodeï¼ä»¥ä¿è¯ä¸ä¼å对ä¹åçåè¿è¡å¾å³æ ççå°è¯ãclientä¹ä¼ç¡®è®¤datanodeåæ¥çæ°æ®çæ ¡éªåãå¦æåç°ä¸ä¸ªæåçåï¼å®å°±ä¼å¨clientè¯å¾ä»å«çdatanodeä¸è¯»åä¸ä¸ªåçå¯æ¬ä¹åæ¥åç»namenodeã
7ãè¿ä¸ªè®¾è®¡çä¸ä¸ªéç¹æ¯ï¼clientç´æ¥èç³»datanodeå»æ£ç´¢æ°æ®ï¼å¹¶è¢«namenodeæå¼å°åä¸æ好çdatanodeãå 为æ°æ®æµå¨æ¤é群ä¸æ¯å¨æædatanodeåæ£è¿è¡çã
HDFS 原理简述
Apache软件基金会开发的Hadoop是一款并行计算框架和分布式文件管理系统,其中HDFS(Hadoop Distributed File System)是其核心模块之一。本文将简要介绍HDFS系统,分析其基本架构和原理。
在数据存储需求不断增长的跨境产品没有溯源码今天,单机容量已经无法满足需求。Hadoop正是为了解决这一问题而诞生的,它能够实现跨机器的存储。HDFS是Hadoop的一个子项目,提供了分布式文件系统服务,通过Hadoop集群管理分布在各个机器上的文件系统。HDFS通过引入网络,提高了数据传输的复杂度,但同时也保证了数据在节点不可用时的安全性。
HDFS的设计目标主要是针对具有大量数据集的应用,如GB甚至TB级别的文件。HDFS需要提供高数据传输带宽,能够扩展到数百个节点,并且对延时没有过高要求。HDFS采用流式访问数据集,更注重数据批处理而非用户交互处理,其假设是最有效的数据处理模式是一次写入、多次读取。这种模式使得高吞吐量的数据访问成为可能。
HDFS采用主从体系结构,包括HDFS Client、NameNode、DataNode和Secondary NameNode。NameNode作为中心服务器,负责构建命名空间和管理文件的数字人克隆直播源码元数据,而DataNode则管理所在节点的存储。HDFS的文件被拆分成Block块,这些块存储在一组DataNode上。Namenode执行文件系统的名字空间操作,确定数据块到具体Datanode节点的映射,并处理客户端的读写请求。
Block是HDFS存储数据的基本单位,默认大小为M。这种设置是为了最小化查找时间,控制定位文件与传输文件所用的时间比例。Block的拆分使得单个文件大小可以大于整个磁盘的容量,并且简化了存储系统的复杂度。Namenode可能成为集群的单点故障,因此HDFS提供了备份持久化元数据和Secondary NameNode两种解决机制。
HDFS的副本机制和机架感知是为了提高数据可靠性和读写效率。副本机制通过在多个节点上保存多个副本,提高了数据的可靠性。机架感知则是通过网络拓扑结构,将网络看成一棵树,将两个节点间的距离定义为二者到最近的共同祖先的距离的总和,从而优化副本存放策略。
Hadoop HDFS 简介
Hadoop HDFS 简介
1. 概述
Hadoop 分布式文件系统(HDFS)是设计用于大规模数据存储的可靠系统。它提供分布式存储、高可用性、可靠性、块存储等功能。通过 HDFS,用户可以操作文件的写入和读取。
2. HDFS 的核心功能
HDFS 的核心优势在于存储海量文件,而非大量小文件。其容错机制通过数据复制确保存储的可靠性,即使硬件故障,数据也不会丢失。HDFS 提供高吞吐量数据访问能力,支持并行数据访问。
3. HDFS 节点架构
HDFS 采用主从架构,包括 NameNode(Master)和 DataNode(Slave)。
3.1 NameNode
NameNode 负责管理文件系统命名空间,执行如打开、关闭、重命名文件和目录等操作。它应部署在可靠的硬件上。
3.2 DataNode
DataNode 执行存储数据的任务,管理集群中存储的数据块,并响应 NameNode 的指令。DataNode 节点可以部署在成本较低的硬件上。
4. HDFS 进程
HDFS 运行在 NameNode 和 DataNode 节点上,提供分布式存储服务。
5. HDFS 数据存储机制
文件被拆分为小块存储,每个块默认大小为 MB。数据块以分布式方式存储于集群的不同节点,提供并行数据处理能力。
6. 数据复制与容错机制
HDFS 复制数据块以实现容错,每个块默认有 3 个副本,分布于集群中的不同节点,确保数据可靠性。
7. 机架感知设计
通过在多个机架上分布数据块副本,HDFS 提高容错能力和网络带宽利用率,确保系统高可用性。
8. HDFS 架构与交互
HDFS 架构包括 NameNode 和 DataNode。客户端与 NameNode 交互执行读写操作,遵循 write-once-read-many 模型。
9. HDFS 特性
9.1 分布式存储
HDFS 以分布式方式存储数据块,提供映射(MapReduce)处理大数据子集的能力。
9.2 数据块管理
数据块是文件系统的基本单元,每个块的副本分布于不同节点,提供容错性。
9.3 复制策略
默认每个块有 3 个副本,可通过配置文件调整副本数量。HDFS 确保数据至少存在于 3 个节点上。
9.4 高可用性与数据可靠性
通过数据复制和分布存储,HDFS 提供高可用性和数据可靠性,即使某些节点故障,数据仍可访问。
9.5 容错与数据恢复
HDFS 的容错机制确保数据即使在硬件故障情况下也能恢复,提高数据安全性。
9.6 可扩展性
HDFS 支持水平扩展,通过添加更多节点或磁盘实现集群的动态扩展。
9.7 高吞吐量程序访问
HDFS 提供对应用程序数据的高吞吐量访问,支持高效的数据读写操作。
9.8 HDFS 操作
通过命令行或编程接口与 HDFS 交互,支持文件操作如创建、复制、权限设置等。
9.9 文件读写流程
读取时,客户端与 NameNode 交互获取数据节点地址,读取数据;写入时,同样通过 NameNode 获取地址,并在多个数据节点上并行写入数据块。
总结,HDFS 是一个高效、可靠、可扩展的分布式文件系统,提供大规模数据存储与访问能力,适用于大数据处理场景。
GFS 谷歌文件系统论文笔记(GFS 即 HDFS 原型)
在大数据处理的世界里,Hadoop分布式文件系统(HDFS)作为开源的GFS实现,专为非结构化数据的存储而设计。它的上层结构是HBase,用于结构化数据的管理,而MapReduce则负责复杂的计算任务。 背景需求揭示了HDFS的挑战:高硬件故障率、超大文件和少量数据的存储,以及以读为主但要求原子性的追加写入。系统对带宽需求高,而延迟敏感性相对较低。HDFS采用分层组织,包括目录管理、文件操作(如增删、打开、关闭和读写)以及快照功能,秒级创建文件副本并支持原子追加。关键组件:Master与元数据管理
Master作为单节点的控制中心,负责存储和维护所有文件系统的元数据,如名称空间(路径和指向数据的指针)和目录锁管理。元数据信息被组织为固定大小的M chunk,每个chunk都有唯一的块句柄。Master通过内存优化来提高访问速度,并通过心跳机制与chunk服务器通信,确保在节点故障时迅速恢复。操作日志与一致性保障
元数据的操作日志是持久化的,记录所有变更,只有经过持久化后变化才对客户端可见。Master定期做检查点,并通过客户端的租约机制减少与Master的交互,保持数据一致性。写入操作首先写入主chunk,然后同步到其他副本,利用IP邻近和链式复制提高吞吐量。副本管理与容错性
HDFS默认每个chunk有三个副本,分散在不同chunk服务器上,以实现高可用性和容错性。通过垃圾收集策略和惰性删除,系统在保证可靠性的同时简化了数据清理。Master记录所有操作,包括删除,确保数据恢复时的完整性。诊断与恢复
运行时,HDFS通过心跳机制检查chunk服务器状态,确保数据的完整性和一致性。在系统崩溃后,通过检查点快速重启机制,仅恢复检查点后的日志,大大提高恢复速度。通过详尽的RPC日志,诊断工具帮助监控和解决问题。
易语言qq刷屏源码_易语言qq刷屏源码怎么用

类似于快团团源码_类似快团团的工具

微信群好友导出源码

受「黑金」醜聞影響 日本自民黨「森山派」決定解散
易语言qq刷屏源码_易语言qq刷屏源码怎么用
小程序商城完整免费源码_小程序商城完整免费源码是什么
